Lucene 索引功能
Lucene 数据建模
基本概念
文档(doc): 文档是 Lucene 索引和搜索的原子单元,文档是一个包含多个域的容器。
域(field): 域包含“真正的”被搜索的内容,每一个域都有一个标识名称,而“域值”则是实际被搜索的对象。
词元(term): 每个域的域值可能为一个复合字符串,通过分析器的各种处理,能将其分解为可以被搜索的词元。例如:"中国人China",其中包含的词元有:"中"、"国"、"人"、"china"。
与数据库的比较
灵活的架构: Lucene 没有一个确定的全局模式,加入索引的每一个文档都是独立的,与之前加入的文档没有任何关系。
反向规格化: Lucene 需要解决文档真实结构和 Lucene 表示能力之间的不匹配问题。因为 Lucene 文档都是单一文档,互相没有关系。无法像数据库中通过键将不同的表关联起来。
索引过程
流程示意

- 提取文本和创建文档:从各种原始数据,比如 XML 文档、syslog 日志、网络数据包等提取出预想的文本信息并建立起对应的、包含各个域的文档。
- 分析文档:将文本数据分割为词汇单元串,然后执行一些可选操作(转小写、去掉 a/an/the/on/in 等),得到能够被搜索的词元(term)。
- 向索引添加文档:对输入数据分析完毕后就可以将分析结果写入索引文件中。
- Lucene 的索引是倒排索引,倒排索引回答"哪些文档包含XXX词元"这样的问题,而不是回答"XXX文档包含有哪些词元"。
倒排索引
分词:
为了创建倒排索引,需要先将各文档(docs)中域(field)的值切分为独立的单词(term),而后将之创建为一个无重复的有序单词列表。这个过程称之为“分词(tokenization)”。
标准化:
为了实现 full-text 域的搜索,倒排索引中的数据还需进行“标准化(normalization)”为标准格式,才能评估其与用户搜索请求字符串的相似度。
例如,将所有大写字符转换为小写,将复数统一为单数,将同义词统一进行索引,去掉类似 the/is/a/ 等这样的 "停用词(stopword)" 等。
分析:
“分词” 和 “正规化” 过程被称为分析,由 Analyzer 完成。
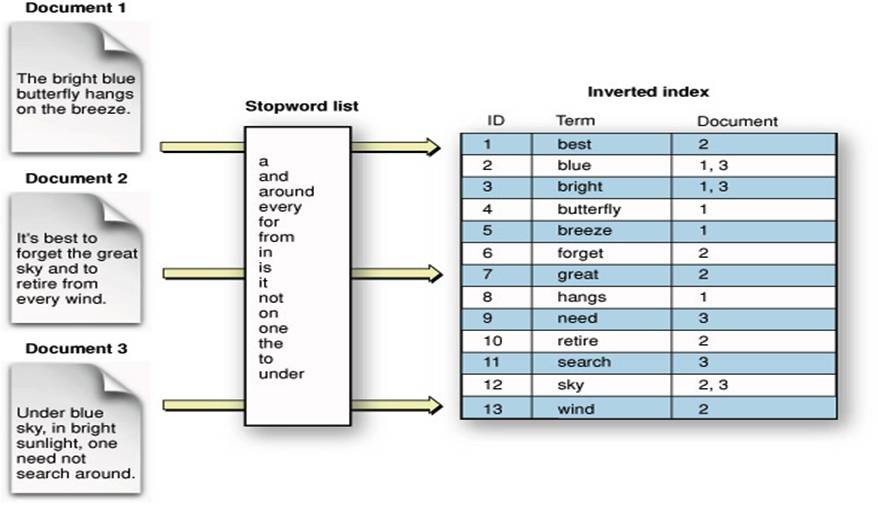
索引结构:
index:一个索引存放在一个目录中。
segment:一个索引中可以有多个段,段与段之间是独立的,添加新的文档可能产生新段,不同的段可以合并成一个新段。
document:文档是创建索引的基本单位,不同的文档保存在不同的段中,一个段可以包含多个文档。
field:域,一个文档包含不同类型的信息,可以拆分开索引。
term:词,索引的最小单位,是经过词法分析和语言处理后的数据。
索引正向信息:
按照层次依次保存了从索引到词的包含关系:
index-->segment-->document-->field-->term。
索引反向信息
反向信息保存了词典的倒排表映射:
term-->document
索引结构图:
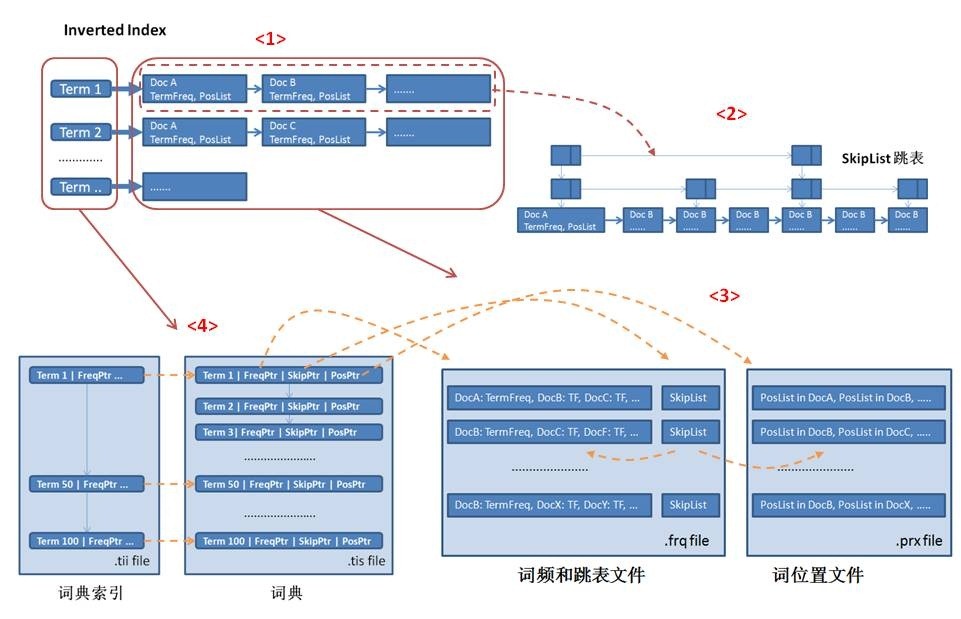
基本索引操作
向索引添加文档:
- addDocument(Document) ————使用默认分析器添加文档,该分析器在创建IndexWriter对象时指定,用于词汇单元化操作
- addDocument(Document, Analyzer) ————使用指定的分析器添加文档和词汇单元化操作
删除索引中的文档:
- deleteDocuments(Term) ————删除包含 term 的所有文档
- deleteDocuments(Term[]) ————删除包含 term 数组任意元素的所有文档
- deleteDocuments(Query) ————删除匹配查询语句的所有文档
- deleteDocuments(Query[]) ————删除匹配查询语句数组任意元素的所有文档
- deleteAll(term) ————删除索引中所有文档
跟更新索引中的文档:
Lucene 只能删除整个旧文档再重新添加新文档,即便是更新 API 实际执行的操作也是如此。
- updateDocument(Term, Document) ————先删除包含 term 变量的文档,在使用 writer 的默认分析器添加新文档
- updateDocument(Term, Document, Analyzer) ————功能与上面一致,不过可以指定分析器
域选项
域索引选项:
通过倒排索引来控制域文本是否可以被搜索。
- Index.ANALYZED ————使用分析器将域值分解成独立的词汇单元流
- Index.ANALYZED_NO_NORMS ————同上,不过不在索引中存储 norems 信息,可节省内存
- Index.NOT_ANALYZED ——————不对 string 进行分析,将域值作为单一次元进行索引
- Index.NOT_ANALYZED_NO_NORMS ——————同上,不过不在索引中存储norems信息,可节省内存
- Index.NO ——————使得对应域不可搜索
域存储选项:
用来确定是否需要存储域的真实值以便后续搜索时能恢复这个值。
- Store.YES————指定存储域值,原始的字符串值全部被保存在索引中
- Store.NO——————指定不存储域值
域的项向量选项:
Reader、TokenStream、byte[]域值:
域排序选项:
多值域:
对文档和域进行加权操作
当改变一个文档或域的加权因子时,必须完全删除并创建对应的文档,或者使用 updateDocument(起始也是删除再新建)方法。
文档加权操作:
通过文档加权因子,能够指示Lucene在计算相关性时考虑该文档针对索引中其它文档的重要程度。
- Document 的 setBoost(float) 方法
域加权操作:
通过域加权因子,能够指示Lucene在计算相关性时考虑该文档针对索引中其它文档的重要程度
- Field 的 setBoost(float) 方法
加权基准(Norms):
索引数字、日期和时间
索引数字:
- 在字符串中包含数字:通过选择分析器(有些分析器会把"It is a long time from 1900"中的数字去掉,不解析为词元)来保证字符串中的数字不被丢弃,而被当成一个 string 类型的词元(term)
- 只包含数字的域:要实现对数字域的范围搜索和排序,需要 NumericField 的 set 方法设置域类型为 long/int/float 之一
索引日期和时间:
- Lucene 首先将他们转换为数值类型(Unix 时间戳)再进行索引
域截取
对一些文档,比如二进制数据,解析失败可能会导致在索引创建大量的无用的域,域截取可以加以控制,以下为2个默认实例。
- MaxFieldLength.UNLIMITED ————不采取截取
- MaxFieldLength.LIMITED ————截取前1000项
其它 Directory 子类
Lucene 的抽象类 Directory 提供了一个简单的文件存储 API,当操作索引文件进行读写时候,需要调用 Directory 子类的对应方法来进行。
子类负责从文件系统中读写文件,都是继承于抽象基类 FSDirectory。
- SimpleFSDirectory ————使用 java.io.* API 将文件存入文件系统
- NIOFSDirectory ————使用 java.nio.* API 将文件保存至文件系统
- MMapDirectory ————使用内存映射 I/O 进行文件访问
- RAMDirectory ————将所有文件都存入 RAM
- FileSwitchDirectory ————使用两个文件目录,根据文件扩展名在两个目录之间进行切换
高级索引话题
一些未细化讨论的Lucene索引的高级概念。包括:
- 用IndexReader删除文档
- 回收被删除文档的磁盘空间
- 缓冲和刷新
- 索引提交
- ACID事务和索引连续性
- 合并段
Lucene 索引功能的更多相关文章
- MySQL和Lucene索引对比分析
MySQL和Lucene都可以对数据构建索引并通过索引查询数据,一个是关系型数据库,一个是构建搜索引擎(Solr.ElasticSearch)的核心类库.两者的索引(index)有什么区别呢?以前写过 ...
- lucene索引库的增删改查操作
1. 索引库的操作 保持数据库与索引库的同步 说明:在一个系统中,如果索引功能存在,那么数据库和索引库应该是同时存在的.这个时候需要保证索引库的数据和数据库中的数据保持一致性.可以在对数据库进行增.删 ...
- 深入Lucene索引机制
Lucene的索引里面存了些什么,如何存放的,也即Lucene的索引文件格式,是读懂Lucene源代码的一把钥匙. 当我们真正进入到Lucene源代码之中的时候,我们会发现: Lucene的索引过程, ...
- 一步一步跟我学习lucene(18)---lucene索引时join和查询时join使用演示样例
了解sql的朋友都知道,我们在查询的时候能够採用join查询,即对有一定关联关系的对象进行联合查询来对多维的数据进行整理.这个联合查询的方式挺方便的.跟我们现实生活中的托人找关系类似,我们想要完毕一件 ...
- Lucene索引文件学习
最近在做搜索,抽空看一下lucene,资料挺多的,不过大部分都是3.x了--在对着官方文档大概看一下. 优化后的lucene索引文件(4.9.0) 一.段文件 1.段文件:segments_5p和s ...
- lucene索引
一.lucene索引 1.文档层次结构 索引(Index):一个索引放在一个文件夹中: 段(Segment):一个索引中可以有很多段,段与段之间是独立的,添加新的文档可能产生新段,不同的段可以合并成一 ...
- lucene 索引合并策略
在索引算法确定的情况下,最为影响Lucene索引速度有三个参数--IndexWriter中的 MergeFactor, MaxMergeDocs, RAMBufferSizeMB .这些参数无非是控制 ...
- Lucene学习笔记: 四,Lucene索引过程分析
对于Lucene的索引过程,除了将词(Term)写入倒排表并最终写入Lucene的索引文件外,还包括分词(Analyzer)和合并段(merge segments)的过程,本次不包括这两部分,将在以后 ...
- iOS开发——UI_swift篇&UITableView实现索引功能
UITableView实现索引功能 关于UItableView的索引在平时项目中所见不多,最多的就是跟联系人有关的界面,虽然如此,但是作为一个swift开发的程序必须知道的一个技术点,所以今天 ...
随机推荐
- js基础第3天
仿淘宝搜索框案例(有价值) 判断用户输入事件 正常浏览器:oninput(判断用户输入) ie678浏览器兼容:onpropertychange(因为兼容性问题, ie浏览器678是需要使用这个来判断 ...
- 判断A树是否包含B树结构
题目:输入两棵二叉树A和B,判断B是不是A的子结构 分析:根据数的遍历方法,首先想到的是采用递归的方式要更简单些,树A从根节点进行遍历,首先判断与B的根节点值是否相等,如果相等则进行递归遍历验证,否则 ...
- TCP 3次握手和四次挥手
1.标示符说明 位码即tcp标志位: SYN(synchronous建立联机) ACK(acknowledgement 确认) PSH(push传送) FIN(finish结束) ...
- sql-逻辑循环while if
--计算1-100的和 declare @int int=1; declare @total int=0; while(@int<=100) begin set @total=@total+@i ...
- Django model中 双向关联问题,求帮助
Django model中 双向关联问题,求帮助 - 开源中国社区 Django model中 双向关联问题,求帮助
- 纯CSS完美实现垂直水平居中的6种方式
前言 由于HTML语言的定位问题,在网页中实现居中也不是如word中那么简单,尤其在内容样式多变,内容宽高不定的情况下,要实现合理的居中也是颇考验工程师经验的.网上讲居中的文章很多,但是都不太完整,所 ...
- Java网络编程(URL&URLConnection)
package cn.itcast.net.p2.ie_server; import java.io.IOException; import java.io.InputStream; import j ...
- android四大功能组件概要总结
1.activity 某一个activity对应于app中的一个具体的页面.而intent是具些activity都具有的同类型操作的抽象,比如Main View Edit PICK 已及所对应的数据 ...
- eclipse jetty启动内存溢出
一.eclipse jetty启动内存溢出, 异常信息 Exception in thread "ConfigClientWorker-Default" java.lang.Out ...
- Android内存中的图片
图片在内存中的大小 Android.graphics.Bitmap类里有一个内部类Bitmap.Config类,在Bitmap类里createBitmap(intwidth, int height, ...