[译]Atomic VS. Non-Atomic 操作
原文链接:atomic-vs-non-atomic-operations
在网上已经写了很多关于原子操作的文章,但是通常都集中在原子的读-修改-写(RMW. read-modify-write)操作。但是这些并是所有的原子操作。同样重要的属于原子操作的还是有load(译注:读)和store(译注:写)。在这篇文章中,我将会在处理器层面和C/C++语言层面,比较原子性和非原子性的load和store。顺便,我们将会阐明以下在C++11中的“数据竞争”概念。
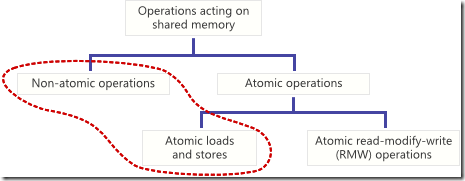
如果一个共享变量的操作,它能相对于其他线程,能够一步完成,那么这个操作就是原子性的操作。当对一个共享变量执行原子性的store操作,其他线程只能观察到它已经修改完后的数据。当对一个共享变量执行原子性的load操作,它会读取单一时刻所显示的完整的值。非原子性的store和load不会有上述的保证。
离开上述的保证,无锁编程(lock-free programming)将变得不可能,因为不能在相同时间,让多个线程操作同一个共享变量。我们可以将此明确表达为一个规则:
任何时间,两个线程并发地操作在一个共享变量上,这些操作中的一个执行一个写动作,所有的线程都必须使用原子操作。
如果你违反这个规则,其中有个线程使用了非原子操作,那么你将会陷入一个在C++11标准中称之为数据竞争(不要和Java中的data race概念,以及更通用的race condition搞混淆)的情形。C++11标准没有告诉编程人员为什么数据竞争是不好的。但是如果你引发了数据竞争,那么就会得到一个"未定义行为(undefined behavior)"的结果。数据竞争是不好的真正理由只有一个:它们会导致“撕裂读”(torn reads)和“撕裂写”(torn writes。译注:就是一个非完整的读写)。
一个内存操作可能是非原子的,因为它使用了多条CPU指令,甚至即使使用单条CPU指令,也可能是非原子的。也可能是因为程序员写的可移植代码。但是不能简单地做出这个假设。让我们看几个例子。
由于多条CPU指令的非原子操作
假设有一个64位的全局变量,初始化为0.

1 uint64_t sharedValue = 0;
此时,将一个64位的值更新到此变量:
1 void storeValue()
2 {
3 sharedValue = 0x100000002;
4 }
在32位的 x86平台上,使用GCC编译此函数,会产生以下汇编代码:
1 $ gcc -O2 -S -masm=intel test.c
2 $ cat test.s
3 ...
4 mov DWORD PTR sharedValue, 2
5 mov DWORD PTR sharedValue+4, 1
6 ret
7 ...
如你所见,编译器实现一个64位整形的赋值是通过两个单独的机器指令。第一条指令将低32位设置为0x00000002,第二条指令将高32位设置为0x00000001。很明显,这个赋值操作不是原子操作。如果sharedValue被不同线程并发访问,将会出错。
1. 如果一个线程在两条指令之间对sharedValue的访问时独占的,那么在内存中,sharedValue将会被设置为0x0x0000000000000002,
一个“撕裂写(a torn write)”。此时,如果另外一个线程读取sharedValue的值,那么将会读到一个完全虚假的值。
2. 更遭的是,如果一个线程在两条指令之间进行独占访问,此时另一个在第一个线程恢复前修改变量sharedValue,会
导致一个永久性的“撕裂写(torn write)”:高32位来源于一个线程,低32位来源于另一个线程。
3. 在多核设备中,线程都没必要进行一个会导致“撕裂写”的资源抢占。因为当一个线程调用sharedValue,在不同核心上的
任意线程在某个时刻都可能会去读sharedValue,此时的sharedValue可能处于修改的一半当中。
并发地从sharedValue读也会带来一些问题:
1 uint64_t loadValue()
2 {
3 return sharedValue;
4 }
5
6 $ gcc -O2 -S -masm=intel test.c
7 $ cat test.s
8 ...
9 mov eax, DWORD PTR sharedValue
10 mov edx, DWORD PTR sharedValue+4
11 ret
12 ...
13
同样,编译器用两条机器指令实现读取操作:第一条指令读取低32位的值到eax寄存器,然后第二条指令读取高32位的值到edx寄存器。在这种情况下,并发地发生一个写的操作,此时会产生一个“撕裂读(torn read)”。即使这个并发的写是原子操作。
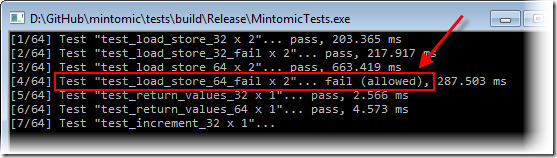
这些问题并不只是存在于理论上。Mintomic的测试套件中包含了一个叫test_load_store_64_fail的测试用例。一个线程使用普通的赋值操作符更新一个64位变量的值,另一个线程周期性地执行一个从相同变量的读取操作,对每次读取回来的结果进行校验。在x86多核机器上,和预期一样,此测试会经常失败。
非原子性的CPU指令
即使执行单条CPU指令,一个内存操作也可能是非原子性的。例如:在ARMv7指令集中,包含了一个strd指令,实现将两个32位的寄存器的值存储到一个64位的变量中。
1 strd r0, r1, [r2]
在一些ARMv7处理器中,这条指令时非原子性的。当处理器碰到这条指令时,实际上是执行2条32位的单独存储动作。再一次,任何运行在其他核心的线程都可能会观察到一个“撕裂读(torn write)”。有意思的是,“撕裂读(torn write)”甚至可能会发生在单核设备中:因为系统中断。在2条32位存储指令中间,可能会发生线程上下文的调度切换。这种情况下,当线程从中断中恢复后,将会重新执行一次strd指令。
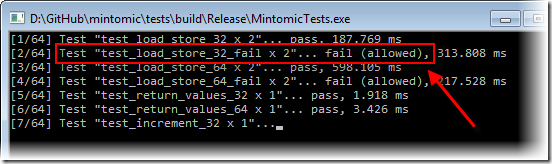
另外一个例子,是发生在大家熟知的x86平台上。一个32位的mov指令只有在内存操作数是自然对齐的情况下才是原子性的!其他情况下是非原子性的。换句话说,一个32位的整形,只有它的内存地址是4的整数倍情况下,原子性才能有保证。Mintomic有另一个测试用例test_load_store_32_fail,可以验证此种情况。在写本文的时候(译注:2013年6月),这个测试用例在x86平台上总是成功的。但是如果你将测试变量sharedInt的地址强制修改为非对齐的内存地址,那么测试结果将会失败。在我的Core 2 Quad Q6600机器上,如果sharedInt是跨越了单条缓存行界限(crosses a cache line boundary),那么测试就会失败。
1 // Force sharedInt to cross a cache line boundary:
2 #pragma pack(2)
3 MINT_DECL_ALIGNED(static struct, 64)
4 {
5 char padding[62];
6 mint_atomic32_t sharedInt;
7 }
8 g_wrapper;
对于特定处理的情况已经说的够多了,接下来看看在C/C++语言层面的原子性。
所有的C/C++操作都假设是非原子性的
在C和C++中,每一个操作都被假定为非原子性的,即使是普通的32位整形赋值。除非编译器或硬件厂商有特殊说明。
1 uint32_t foo = 0;
2
3 void storeFoo()
4 {
5 foo = 0x80286;
6 }
7
语言标准中没有提及关于以上情况的原子性。也许整形赋值是原子性的,也许不是。因为非原子性的操作不做任何保证,所以在C中定义普通的整形赋值时非原子性的。
在实际中,我们通常更了解我们的目标平台。例如:在所有的现代x86,x64,Itanium,SPARC,ARM和PowerPC处理器中,普通的32位整形,只要内存地址是对齐的,那么赋值操作就是原子操作。你可以通过查看处理器手册或者编译器文档来证实。在游戏产业,很多32位的赋值时依赖于这个特别的保证。
尽管如此,当写真正的可移植的C和C++代码时,有一个长期的伪装的传统就是,我们只知道语言标准中所记录的,除此之外,一概不知。可移植的C/C++代码是要运行在每台可能的设备上,过去的设备,现在的设备以及想象中的设备。从我个人来说,我喜欢想象有台机器,只能被一开始的混乱所改变。
在这样的机器上,你绝对不会想在同一时间执行并发的读操作,即使是普通的赋值。你可能最终只会读到一个完全随机的值。
在C++11中,有一种方式可以真正执行可移植的load原子操作和store原子操作:C++11 atomic库。使用C++11 atomic库,即使是运行在想象的机器上,也可以执行原子性的load和store。即使在C++11 atomic库的内部秘密地使用互斥锁使每个操作变得原子性。同样还有一个我上个月发布的叫Mintomic的库(译注:2013年6月,此库目前已废。)。虽然支持的平台可能不多,但是在几个老的编译器上还是可以正常工作的,它是手工优化的并且保证是无锁的。
不严格的(Relaxed)原子操作
让我们回到原来的sharedValue例子。我们将会使用Mintomic对其进行重写。这样在Mintomic支持的平台上,所有的操作都是原子性的了。首先,必须将sharedValue声明为Mintomic的原子数据类型的一种。
1 #include <mintomic/mintomic.h>
2
3 mint_atomic64_t sharedValue = { 0 };
4
mint_atomic64_t类型在不同的平台上,保证原子访问都有正确的内存对齐。这很重要。因为在一些平台的编译器中并不做出类似的保证。比如ARM上的和Xcode 3.2.5绑定的GCC4.2版,就不保证普通的uint64_t是8字节对齐的。
在修改sharedValue时,不再调用普通的、非原子的赋值操作,而是调用mint_store_64_relaxed
1 void storeValue()
2 {
3 mint_store_64_relaxed(&sharedValue, 0x100000002);
4 }
同样的,在读取sharedValue变量的值时,我们使用mint_load_64_relaxed
1 uint64_t loadValue()
2 {
3 return mint_load_64_relaxed(&sharedValue);
4 }
使用C++11的术语来说,上述方法是无数据竞争(data race-free)的。在执行并发操作时,绝对不可能存在“撕裂读”或“撕裂写”。不管是运行在ARMv6/ARMv7,x86,x64或PowerPC。
下面是C++11的版本
1 #include <atomic>
2
3 std::atomic<uint64_t> sharedValue(0);
4
5 void storeValue()
6 {
7 sharedValue.store(0x100000002, std::memory_order_relaxed);
8 }
9
10 uint64_t loadValue()
11 {
12 return sharedValue.load(std::memory_order_relaxed);
13 }
14
你可能注意到,不管Mintomic还是C++11版本的代码都使用了relaxed语义的原子操作,也就是带有_relaxed后缀的内存序列参数。
特别地,关于relaxed语义的原子操作,在此原子操作的之前或者之后的指令都可能被影响,也就是被乱序执行。可能是因为编译器指令乱序或者处理器的指令乱序。编译器可能还是在重复的relaxed原子操作上做一些优化,就像在非原子性的操作上一样。在所有的情况下,这个操作都是原子操作。
当并发地操作共享变量,一贯地使用C++11 atomic库或者Mintomic是个好习惯,即使是你知道在你所针对的平台上,普通的load或store操作已经是原子操作。一个atomic库的方法可以起到一个提示作用,提示这个变量是并发访问的。
[译]Atomic VS. Non-Atomic 操作的更多相关文章
- Java中的Atomic包
Atomic包的作用 方便程序员在多线程环境下,无锁的进行原子操作 Atomic包核心 Atomic包里的类基本都是使用Unsafe实现的包装类,核心操作是CAS原子操作: 关于CAS compare ...
- java多线程详解(8)-volatile,Atomic比较
在变成过程中我们需要保证变量的线程安全,在java中除了使用锁机制或者Threadlocal等保证线程安全,还提供了 java.util.concurrent.atomic.Atomic*(如Atom ...
- C++11 并发指南六(atomic 类型详解四 C 风格原子操作介绍)
前面三篇文章<C++11 并发指南六(atomic 类型详解一 atomic_flag 介绍)>.<C++11 并发指南六( <atomic> 类型详解二 std::at ...
- C++11 并发指南六( <atomic> 类型详解二 std::atomic )
C++11 并发指南六(atomic 类型详解一 atomic_flag 介绍) 一文介绍了 C++11 中最简单的原子类型 std::atomic_flag,但是 std::atomic_flag ...
- golang sync/atomic
刚刚学习golang原子操作处理的时候发现github上面一个比较不错的golang学习项目 附上链接:https://github.com/polaris1119/The-Golang-Standa ...
- 并发之java.util.concurrent.atomic原子操作类包
15.JDK1.8的Java.util.concurrent.atomic包小结 14.Java中Atomic包的原理和分析 13.java.util.concurrent.atomic原子操作类包 ...
- golang语言中sync/atomic包的学习与使用
package main; import ( "sync/atomic" "fmt" "sync" ) //atomic包提供了底层的原子级 ...
- boost并发编程boost::atomic
三个用于并发编程的组件: atomic,thread,asio(用于同步和异步io操作) atomic atomic,封装了不同计算机硬件的底层操作原语,提供了跨平台的原子操作功能,解决并发竞争读 ...
- CAS的实现Atomic类库
atomic 原子(atomic)本意是"不能被进一步分割的最小粒子",而原子操作(atomic operation)意为"不可被中断的一个或一系列操作".在多 ...
- JUC 中的 Atomic 原子类总结
1 Atomic 原子类介绍 Atomic 翻译成中文是原子的意思.在化学上,我们知道原子是构成一般物质的最小单位,在化学反应中是不可分割的.在我们这里 Atomic 是指一个操作是不可中断的.即使是 ...
随机推荐
- ImageLoader(多线程网络图片加载)+本地缓存 for windowsphone 7
搞了好长一阵子wp,做点好事. C/S手机app中应用最多的是 获取网络图片,缓存到本地,展示图片 本次主要对其中的delay:LowProfileImageLoader进行修改,在获取图片的时候, ...
- linux ubuntu 思源黑体安装
下载地址: 全部:700多M https://github.com/adobe-fonts/source-han-sans/releases/tag/1.001R 可选部分Github : http ...
- 条形码Code128源代码
public class Code128 { private DataTable m_Code128 = new DataTable(); ; /// <summary> /// 高度 / ...
- Asp.net 引用css/js资源文件
注意Page.ResolveUrl之前的双引号,不是单引号 <script type="text/javascript" src="<%= Page.Reso ...
- 如何快速建立Subversion服务器
本文拷贝自网址:http://www.subversion.org.cn/?action-viewnews-itemid-1 如何快速建立Subversion服务器,并且在项目中使用起来,这是大家最关 ...
- sqlsever2008及以上各个安装包的说明
LocalDB (SqlLocalDB)LocalDB 是 Express 的一种轻型版本,该版本具备所有可编程性功能,但在用户模式下运行,并且具有快速的零配置安装和必备组件要求较少的特点.如果您需要 ...
- 国产CPU研究单位及现状
1.国产CPU主要研制单位 (1)高性能通用CPU(“大CPU”,主要应用于高性能计算及服务器等) 主要研发单位:中国科学院计算所.北大众志.国防科技大学.上海高性能集成电路设计中心 (2)安全适用计 ...
- flex打印图片
<?xml version="1.0" encoding="utf-8"?><s:WindowedApplication xmlns:fx=& ...
- 使用plspl创建orcale作业
1.由于权限问题,第一步应先以sys账户登录,路径:工具->DBMS 调试程序->作业 ,新建一个作业,出现如下图的窗口 2.开始依次填写相应内容,Name为作业名字,注意要加上用户名前 ...
- 【Google Protocol Buffer】Google Protocol Buffer
http://www.ibm.com/developerworks/cn/linux/l-cn-gpb/ Google Protocol Buffer 的使用和原理 Protocol Buffers ...