dom解析器机制 web基本概念 tomcat
0 作业[cn.itcast.xml.sax.Demo2]
1)在SAX解析器中,一定要知道每方法何时执行,及SAX解析器会传入的参数含义
1 理解dom解析器机制
1)dom解析和dom4j原理一致
2)Node是所有元素的父接口
3)常用的API:
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();取得DOM解析器工厂
DocumentBuilder domParser = factory.newDocumentBuilder();取得DOM解析器
domParser.parse(*.xml)加载需要解析的XML文件
Document.getDocumentElement()取得XML文件的根元素/节点
Element.getNodeName():取得根元素
Element.getElementsByTagName("汽车")取得"汽车"元素的集合
NodeList.item(i)取得第N个元素,从0开始
Element.getTextContent():取得元素的文本内容
Element.getAttributes().getNamedItem("出产时间").getTextContent():取得元素中某属性的值
document.createElement("汽车");创建新元素
Element.setTextContent("我的汽车");设置元素的内容
Element.appendChild(newCarElement);在尾部添加元素
Element.insertBefore(newCarElement,
rootElement.getElementsByTagName("汽车").item(1));在指定的元素前添加元素
TransformerFactory tf = TransformerFactory.newInstance();创建输出工厂
Transformer transformer = tf.newTransformer();创建输出对象
Source source = new DOMSource(document);创建内存的document对象
Result result = new StreamResult(new File("src/cn/itcast/xml/dom/car.xml"));指定输出的目标地点
transformer.transform(source,result);将document对象输出到xml文件中
Element.setTextContent("深圳");更新元素的内容
Element.removeChild(secondCarElement);在父元素基础上删除直接子元素
4)dom解析器会将空白字符当作有效元素对待
5)要让dom解析器将空白字符忽略,必须满足二条件
a)对XML文件必须写一个DTD约束
b)factory.setIgnoringElementContentWhitespace(true);
6)dom类解析器和sax类解析器
a)dom是一次性加载到内容,形成document对象,人工导航,适合curd
b)sax是分次性加载到内容,sax解析器导航,但程序员需要编写sax处理器,必须扩展DefaultHandler类,适合r
package cn.itcast.xml.dom; import java.io.File; import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory; import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NodeList; //使用DOM解析器解析XML文件
public class Demo1 {
public static void main(String[] args) throws Exception {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder domParser = factory.newDocumentBuilder();
Document document = domParser.parse(new File("src/cn/itcast/xml/dom/car.xml"));
Element rootElement = document.getDocumentElement();
System.out.println("根元素为:"+rootElement.getNodeName());
NodeList nodeList = rootElement.getElementsByTagName("汽车");
System.out.println("共有:" + nodeList.getLength()+"辆汽车");
System.out.println("++++++++++++++++++++++++++");
for(int i=0;i<nodeList.getLength();i++){
Element element = (Element) nodeList.item(i);
String band = element.getElementsByTagName("车牌").item(0).getTextContent();
String place = element.getElementsByTagName("产地").item(0).getTextContent();
String price = element.getElementsByTagName("单价").item(0).getTextContent();
String time = element.getElementsByTagName("车牌").item(0).getAttributes().getNamedItem("出产时间").getTextContent(); System.out.println("车牌:" + band);
System.out.println("产地:" + place);
System.out.println("单价:" + price);
System.out.println("出产时间:" + time);
System.out.println("-------------------------");
}
}
}
package cn.itcast.xml.dom; import java.io.File;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.transform.Result;
import javax.xml.transform.Source;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.junit.Test;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NodeList; public class Demo2 {
//dom是否将空白字符当作一个有效的元素对待
public static void main(String[] args) throws Exception{
Document document = getDocument();
Element rootElement = document.getDocumentElement();
NodeList nodeList = rootElement.getChildNodes();
System.out.println("共有" + nodeList.getLength()+"个直接元素");
}
@Test
public void create() throws Exception{
Document document = getDocument();
Element newCarElement = document.createElement("汽车");
newCarElement.setTextContent("我的汽车");
Element rootElement = document.getDocumentElement();
//rootElement.appendChild(newCarElement);
rootElement.insertBefore(
newCarElement,
rootElement.getElementsByTagName("汽车").item(1));
write2xml(document);
}
@Test
public void update() throws Exception{
Document document = getDocument();
Element secondCarElement = (Element) document.getElementsByTagName("汽车").item(1);
secondCarElement.getElementsByTagName("产地").item(0).setTextContent("深圳");
secondCarElement.getElementsByTagName("车牌").item(0).getAttributes().getNamedItem("出产时间").setTextContent("2012年");
write2xml(document);
}
@Test
public void delete() throws Exception{
Document document = getDocument();
Element rootElement = document.getDocumentElement();
Element secondCarElement = (Element) rootElement.getElementsByTagName("汽车").item(1);
rootElement.removeChild(secondCarElement);
write2xml(document);
}
private void write2xml(Document document)throws Exception {
//将内存中的document对象写到外存的xml文件
TransformerFactory tf = TransformerFactory.newInstance();
Transformer transformer = tf.newTransformer();
//源
Source source = new DOMSource(document);
//目
Result result = new StreamResult(new File("src/cn/itcast/xml/dom/car.xml"));
transformer.transform(source,result);
}
private static Document getDocument() throws Exception {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
//设置dom解析器将空白字符过滤
factory.setIgnoringElementContentWhitespace(true);
DocumentBuilder domParser = factory.newDocumentBuilder();
Document document = domParser.parse(new File("src/cn/itcast/xml/dom/car.xml"));
return document;
}
}
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE 车辆清单 [
<!ELEMENT 车辆清单 (汽车+)>
<!ELEMENT 汽车 (车牌,产地,单价)>
<!ELEMENT 车牌 (#PCDATA)>
<!ELEMENT 产地 (#PCDATA)>
<!ELEMENT 单价 (#PCDATA)>
<!ATTLIST 车牌
出产时间 CDATA #REQUIRED>
]>
<车辆清单>
<汽车>
<车牌 出产时间="2010年">奥迪</车牌>
<产地>北京</产地>
<单价>30</单价>
</汽车>
<汽车>
<车牌 出产时间="2012年">本田</车牌>
<产地>深圳</产地>
<单价>60</单价>
</汽车>
</车辆清单>
2 web基本概念
1)JavaWeb是用Java技术开发基于Web的应用
2)在Internet上运行的资源有二大类:
a)静态资源
无论何时何地以何种身份访问该资源,显示的结果一样
HTML或XHTML或XML,CSS,JavaScript,...
b)动态资源
无论何时何地以何种身份访问该资源,有可以结果不一样
Servlet,Jsp,...
package cn.itcast.web.base; import java.io.BufferedReader;
import java.io.FileReader;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.ServerSocket;
import java.net.Socket; //使用JavaSocket编程,读取abc.html文件,写给每个浏览器客户端
public class Demo1 {
public static void main(String[] args) throws Exception {
ServerSocket ss = new ServerSocket(9999);
while (true) {
Socket s = ss.accept();
// 得到输入流
InputStream is = s.getInputStream();
// 将字节流包装成高级字符流,目的是行行读
BufferedReader br = new BufferedReader(new FileReader(
"d:\\abc.html"));
// 得到输出流
OutputStream os = s.getOutputStream();
String line = null;
// 循环读取abc.html文件中的内容
while ((line = br.readLine()) != null) {
// 输出到每个浏览器
os.write(line.getBytes());
}
br.close();
os.close();
s.close();
}
/*
* 项目在一定放在try-catch-finally中在非空的情况下关闭 br.close(); is.close();
* os.close(); s.close(); ss.close();
*/
}
}
*3 安装tomcat web服务器
1)将某个文件提外界用户访问,必须有一个类似的网络应用程序来接收和响应用户的请求
2)web服务器有多种类型
java开源:tomcat6/7。。。
商用:weblogic,websphere
获取Tomcat安装程序包
- tar.gz文件是Linux操作系统下的安装版本
- exe文件是Windows系统下的安装版本(上线)
- zip文件是Windows系统下的压缩版本(开发)绿色
3)安装tomcat
a)配置JDK正确版本[至少是JDK5]和路径
b)执行tomcat/bin/startup.bat启动Web服务器
c)CATALINA_HOME指明需要启动哪台tomcat服务器
错误案例:
a)tomcat端口被占用,可以通过server.xml文件修改默认端口号 <Con>
b)查看当前进程使用情况,工具Fport.exe
c)窗口一闪而过,JAVA_HOME目录设置出错
4)tomcat目录的含义:
*bin/启动和停止tomcat的脚本文件
*conf/配置tomcat的文本,以xml文件为主
*lib/tomcat用到的第三方jar包
logs/tomcat服务器操作相关的日志文件
temp/tomcat运行时用到的一些临时文件
**webapps/tomcat能被外界访问的符合标准目录结构的web应用
work/tomcat运行的工作目录
5)Web标准目录结构:
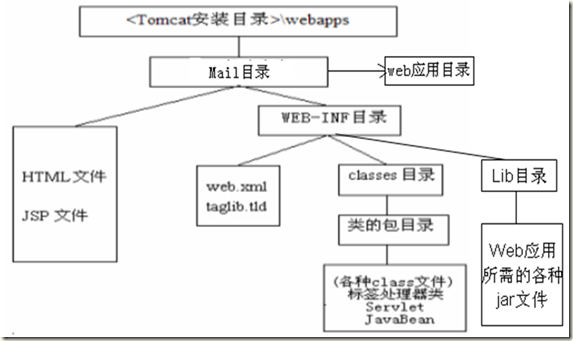
6)Web常用的编号
404:客户端请求的资源,服务端找不到
*4 配置虚拟主机和目录
1)虚拟目录:在tomcat/conf/server.xml文件中设置如下代码:
<Context path="/qq" docBase="d:\mail"/>
path="以/开头,表示虚拟目录"
docBase="web应用的真实目录"
附加: reloadable="false"服务端会自动监视/WEB-INF/classes或lib目录下的变化情况,一旦变化,服务湍在设置成true的情况下,自动加载最新的内容,如果设置成false,服务端无法加载最新的资源,需要手工重新启动服务器,开发阶段设置为true,上线阶段设置为false。unpackWAR="true"服务器会自动将web压缩文件解压成标准的web目录结构
2)设置默认web应用 |缺省的Web应用程序
<Context path="" docBase="d:\mail"/>
3)设置默认web资源 |缺省的web资源
mail-WEB-INF-web.xml文件中设置如下代码:
<welcome-file-list>
<welcome-file>mail.html</welcome-file>
<welcome-file>mail.htm</welcome-file>
<welcome-file>mail.jsp</welcome-file>
</welcome-file-list>
4)设置虚拟主机:在tomcat/conf/server.xml文件中设置如下代码:
<Host name="www.163.com" appBase="d:\sina">
<Context path="" docBase="d:\sina\mail"/>
<Context path="/news" docBase="d:\sina\news"/>
</Host>
name表示虚拟主机名,与HOSTS文件中定义的一致
appBase虚拟主机对应的Web应用根目录
\表示真实目录
/表示外界通过浏览器访问的目录
以windowXP为例:C:\WINDOWS\system32\drivers\etc\HOSTS文件
5)位于webapps/目录下的标准web应用,服务器会自动映射成一个虚拟目录
<Context path="/day04" docBase="d:\apache-tomcat-6.0.29\webapps\day04"/>
6)某些旧版的tomcat服务器,可能无法自动映射webapps/目录下的标准web应用,需要加上WEB-INF/web.xml文件才行
5 理解C/S和B/S结构的特点
1)Domain Name Service
2)DNS是电信内部的一个域名和IP地址的映射关系
3)在查询DNS之前,先查看本地操作系统对应的HOSTS文件,是否能找到对应的IP,如果能找到,不会查DNS了,只有在
查找不到的情况下,再连网找DNS服务器
4)CS结构:程序和数据分离在不同的端
*BS结构:程序和数据绑定在服务端
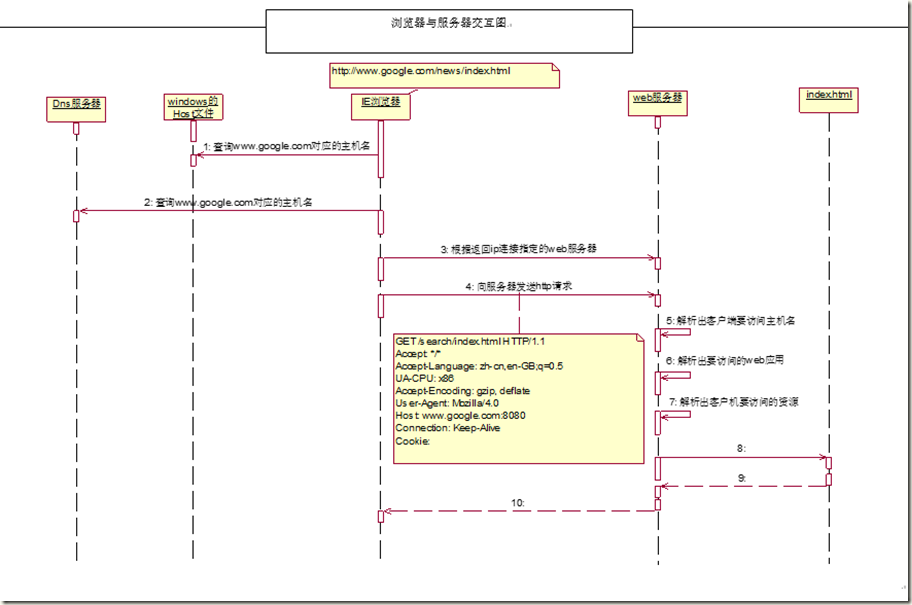
6 观察http协议
1)超文本的传输协议,是基于TCP/UDP协议(底层)
2)有二个版本
a)HTTP/1.0(一次用户请求,服务端响应后,立即断开)
b)HTTP/1.1(一次用户请求,服务端响应后,会保持一定的时间,在该一定时间后,用户可以再次请求)
3)为了让客户端响应速度快,在满足业务需求的情况下,尽量减少HTTP请求数的发送
dom解析器机制 web基本概念 tomcat的更多相关文章
- PHP Simple HTML DOM解析器
一直以来使用php解析html文档树都是一个难题.Simple HTML DOM parser 帮我们很好地解决了使用 php html 解析 问题.可以通过这个php类来解析html文档,对其中的h ...
- 使用Dom解析器,操作XML里面的信息
import java.io.FileNotFoundException;import java.io.FileOutputStream;import java.io.IOException;impo ...
- PHP Simple HTML DOM解析器使用入门
http://www.cnphp.info/php-simple-html-dom-parser-intro.html 一直以来使用php解析html文档树都是一个难题.Simple HTML DOM ...
- JAVA与DOM解析器提高(DOM/SAX/JDOM/DOM4j/XPath) 学习笔记二
要求 必备知识 JAVA基础知识.XML基础知识. 开发环境 MyEclipse10 资料下载 源码下载 sax.dom是两种对xml文档进行解析的方法(没有具体实现,只是接口),所以只有它们是无 ...
- JAVA与DOM解析器基础 学习笔记
要求 必备知识 JAVA基础知识.XML基础知识. 开发环境 MyEclipse10 资料下载 源码下载 文件对象模型(Document Object Model,简称DOM),是W3C组织推荐的 ...
- PHP HTML DOM 解析器 中文手册
简单的PHP HTML DOM 解析器 中文手册 | PHP Simple HTML DOM Parser中文手册 目录 快速入门 如何创建HTML DOM 对象? 如何查找HTML元素? 如何访问H ...
- 解析XML文件之使用DOM解析器
在前面的文章中.介绍了使用SAX解析器对XML文件进行解析.SAX解析器的长处就是占用内存小.这篇文章主要介绍使用DOM解析器对XML文件进行解析. DOM解析器的长处可能是理解起来比較的直观,当然, ...
- Java DOM解析器 - 解析XML文档
使用DOM的步骤 以下是在使用DOM解析器解析文档使用的步骤. 导入XML相关的软件包. 创建DocumentBuilder 从文件或流创建一个文档 提取根元素 检查属性 检查子元素 导入XML相关的 ...
- Java DOM解析器
文档对象模型是万维网联盟(W3C)的官方推荐.它定义了一个接口,使程序能够访问和更新样式,结构和XML文档的内容.支持DOM实现该接口的XML解析器. 何时使用? 在以下几种情况时,应该使用DOM解析 ...
随机推荐
- swfupload使用说明
网上的例子介绍的文档真的很多.下面简单介绍一下 SWFUpload的文件上传流程是这样的: 1.引入相应的js文件 2.实例化SWFUpload对象,传入一个配置参数对象进行各方面的配置. 3.点击S ...
- NPOI Excel导入 导出
添加引用 using NPOI.HSSF.UserModel; using NPOI.SS.UserModel; using System; using System.Collections.Gene ...
- C++ 容器及选用总结
目录 ==================================================== 第一章 容器 第二章 Vector和string 第三章 关联容器 第四章 迭代器 第五 ...
- WPF 概述
WPF 全称是:Windows Presentation Foundation,直译为Windows表示基础.WPF是专门为GUI(Graphic User Interface)程序开发设计的. 在过 ...
- 配置node与express初试
http://www.nodejs.org/下载对应系统的node版本并安装 用npm包管理器安装需要的包 sudo npm install -g express sudo npm install - ...
- Java中的异常处理(二)
1.finally package second; public class C { public static void main(String[] args){ String name = nul ...
- 录制游戏视频——fraps
http://pcedu.pconline.com.cn/341/3417224.html
- EXTJS 4.2 日期控件
{ xtype: "fieldcontainer", layout: "hbox", items: [{ fieldLabel: '开始时间', name: ' ...
- 插入排序(insertion_sort)
最简单的排序算法,又称插值排序,原理类似于打扑克牌时把摸到的牌插入手中已有序牌的过程. void insertion_sort(int* A ,int n){ int i,j,key; ;i < ...
- python 新时代
今天看到有关python的文章,感觉很好奇,学了python很久了,但是还没有真正的用过,只是写一些小程序 看了这篇文章以后真的感觉自己所了解都是皮毛,在此与大家分享: 原文链接:http://www ...