深度学习(五)基于tensorflow实现简单卷积神经网络Lenet5
原文作者:aircraft
原文地址:https://www.cnblogs.com/DOMLX/p/8954892.html
深度学习教程目录如下,还在继续更新完善中
参考博客:https://blog.csdn.net/u012871279/article/details/78037984
https://blog.csdn.net/u014380165/article/details/77284921
目前人工智能神经网络已经成为非常火的一门技术,今天就用tensorflow来实现神经网络的第一块敲门砖。
首先先分模块解释代码。
1.先导入模块,若没有tensorflow还需去网上下载,这里使用mnist训练集来训练,进行手写数字的识别。
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf #导入数据,创建一个session对象 ,之后的运算都会跑在这个session里
mnist = input_data.read_data_sets("MNIST/",one_hot=True)
sess = tf.InteractiveSession()
2.为了方便,定义后来要反复用到函数
#定义一个函数,用于初始化所有的权值 W,这里我们给权重添加了一个截断的正态分布噪声 标准差为0.1
def weight_variable(shape):
initial = tf.truncated_normal(shape,stddev=0.1)
return tf.Variable(initial) #定义一个函数,用于初始化所有的偏置项 b,这里给偏置加了一个正值0.1来避免死亡节点
def bias_variable(shape):
inital = tf.constant(0.1,shape=shape)
return tf.Variable(inital) #定义一个函数,用于构建卷积层,这里strides都是1 代表不遗漏的划过图像的每一个点
def conv2d(x,w):
return tf.nn.conv2d(x,w,strides=[1,1,1,1],padding='SAME') #定义一个函数,用于构建池化层
def max_pool_2x2(x):
return tf.nn.max_pool(x,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
主要的函数说明:
卷积层:
tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None, data_format=None, name=None)
参数说明:
data_format:表示输入的格式,有两种分别为:“NHWC”和“NCHW”,默认为“NHWC”
input:输入是一个4维格式的(图像)数据,数据的 shape 由 data_format
决定:当 data_format 为“NHWC”输入数据的shape表示为[batch, in_height, in_width,
in_channels],分别表示训练时一个batch的图片数量、图片高度、 图片宽度、 图像通道数。当 data_format
为“NHWC”输入数据的shape表示为[batch, in_channels, in_height, in_width]filter:卷积核是一个4维格式的数据:shape表示为:[height,width,in_channels, out_channels],分别表示卷积核的高、宽、深度(与输入的in_channels应相同)、输出 feature map的个数(即卷积核的个数)。
strides:表示步长:一个长度为4的一维列表,每个元素跟data_format互相对应,表示在data_format每一维上的移动步长。当输入的默认格式为:“NHWC”,则
strides = [batch , in_height , in_width, in_channels]。其中 batch 和
in_channels 要求一定为1,即只能在一个样本的一个通道上的特征图上进行移动,in_height , in_width表示卷积核在特征图的高度和宽度上移动的布长,即 。padding:表示填充方式:“SAME”表示采用填充的方式,简单地理解为以0填充边缘,当stride为1时,输入和输出的维度相同;“VALID”表示采用不填充的方式,多余地进行丢弃。具体公式:
“SAME”:
“VALID”:
池化层:
tf.nn.max_pool( value, ksize,strides,padding,data_format=’NHWC’,name=None)
或者
tf.nn.avg_pool(…)
参数说明:
value:表示池化的输入:一个4维格式的数据,数据的 shape 由 data_format 决定,默认情况下shape 为[batch, height, width, channels]
其他参数与 tf.nn.cov2d 类型
ksize:表示池化窗口的大小:一个长度为4的一维列表,一般为[1, height, width, 1],因不想在batch和channels上做池化,则将其值设为1。
#placceholder 基本都是用于占位符 后面用到先定义
x = tf.placeholder(tf.float32,[None,784])
y_ = tf.placeholder(tf.float32,[None,10])
x_image = tf.reshape(x,[-1,28,28,1]) #将数据reshape成适合的维度来进行后续的计算 #第一个卷积层的定义
W_conv1 = weight_variable([5,5,1,32])
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image,W_conv1) + b_conv1) #激活函数为relu
h_pool1 = max_pool_2x2(h_conv1) #2x2 的max pooling #第二个卷积层的定义
W_conv2 = weight_variable([5,5,32,64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1,W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2) #第一个全连接层的定义
W_fc1 = weight_variable([7*7*64,1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2,[-1,7*7*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat,W_fc1) + b_fc1) #将第一个全连接层 进行dropout 随机丢掉一些神经元不参与运算
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1,keep_prob) #第二个全连接层 分为十类数据 softmax后输出概率最大的数字
W_fc2 = weight_variable([1024,10])
b_fc2 = bias_variable([10])
y_conv = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
上面用到了softmax函数来计算loss。
那softmax loss是什么意思呢?如下:
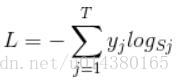
首先L是损失。Sj是softmax的输出向量S的第j个值,前面已经介绍过了,表示的是这个样本属于第j个类别的概率。yj前面有个求和符号,j的范围也是1到类别数T,因此y是一个1*T的向量,里面的T个值,而且只有1个值是1,其他T-1个值都是0。那么哪个位置的值是1呢?答案是真实标签对应的位置的那个值是1,其他都是0。所以这个公式其实有一个更简单的形式:
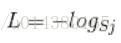
当然此时要限定j是指向当前样本的真实标签。
来举个例子吧。假设一个5分类问题,然后一个样本I的标签y=[0,0,0,1,0],也就是说样本I的真实标签是4,假设模型预测的结果概率(softmax的输出)p=[0.1,0.15,0.05,0.6,0.1],可以看出这个预测是对的,那么对应的损失L=-log(0.6),也就是当这个样本经过这样的网络参数产生这样的预测p时,它的损失是-log(0.6)。那么假设p=[0.15,0.2,0.4,0.1,0.15],这个预测结果就很离谱了,因为真实标签是4,而你觉得这个样本是4的概率只有0.1(远不如其他概率高,如果是在测试阶段,那么模型就会预测该样本属于类别3),对应损失L=-log(0.1)。那么假设p=[0.05,0.15,0.4,0.3,0.1],这个预测结果虽然也错了,但是没有前面那个那么离谱,对应的损失L=-log(0.3)。我们知道log函数在输入小于1的时候是个负数,而且log函数是递增函数,所以-log(0.6) < -log(0.3) < -log(0.1)。简单讲就是你预测错比预测对的损失要大,预测错得离谱比预测错得轻微的损失要大。
———————————–华丽的分割线———————————–
理清了softmax loss,就可以来看看cross entropy了。
corss entropy是交叉熵的意思,它的公式如下:
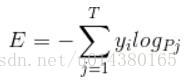
tf.nn.dropout(x, keep_prob, noise_shape=None, seed=None,name=None)
上面方法中常用的是前两个参数:
第一个参数x:指输入
第二个参数keep_prob: 设置神经元被选中的概率,在初始化时keep_prob是一个占位符, keep_prob = tf.placeholder(tf.float32) 。tensorflow在run时设置keep_prob具体的值,例如keep_prob: 0.5
第五个参数name:指定该操作的名字。
correct_predition 进行的是 分别取得预测数据和真实数据中概率最大的来比对是否一样
tf.cast()为类型转换函数 转换成float32类型
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y_conv),reduction_indices=[1])) #交叉熵
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy) #这里用Adam优化器 优化 也可以使用随机梯度下降 correct_predition = tf.equal(tf.argmax(y_conv,1),tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_predition,tf.float32)) #准确率 tf.initialize_all_variables().run() #使用全局参数初始化器 并调用run方法 来进行参数初始化
tf.initialize_all_variables() 接口是老的接口 也许你们的tensorflow 已经用不了 现在tf.initialize_all_variables()已经被tf.global_variables_initializer()函数代替
下面是使用大小为50的mini-batch 来进行迭代训练 每一百次 勘察一下准确率 训练完毕 就可以直接进行数据的测试了
for i in range(20000):
batch = mnist.train.next_batch(50)
if i%100 == 0:
train_accuracy = accuracy.eval(feed_dict={x:batch[0],y_:batch[1],keep_prob:1.0}) #每一百次验证一下准确率
print "step %d,training accuracy %g"%(i,train_accuracy) train_step.run(feed_dict={x:batch[0],y_:batch[1],keep_prob:0.5}) #batch[0] [1] 分别指数据维度 和标记维度 将数据传入定义好的优化器进行训练 print "test accuracy %g"%accuracy.eval(feed_dict={x:mnist.test.images,y_:mnist.test.labels,keep_prob:1.0}) #开始测试数据
同学们大概应该直到这个过程了,如果不理解神经网络Lenet 建议先百度看看他的原理
下面是完整代码。
# -*- coding: utf-8 -*-
"""
Created on XU JING HUI 4-26-2018 @author: root
"""
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf #导入数据,创建一个session对象 ,之后的运算都会跑在这个session里
mnist = input_data.read_data_sets("MNIST/",one_hot=True)
sess = tf.InteractiveSession() #定义一个函数,用于初始化所有的权值 W,这里我们给权重添加了一个截断的正态分布噪声 标准差为0.1
def weight_variable(shape):
initial = tf.truncated_normal(shape,stddev=0.1)
return tf.Variable(initial) #定义一个函数,用于初始化所有的偏置项 b,这里给偏置加了一个正值0.1来避免死亡节点
def bias_variable(shape):
inital = tf.constant(0.1,shape=shape)
return tf.Variable(inital) #定义一个函数,用于构建卷积层,这里strides都是1 代表不遗漏的划过图像的每一个点
def conv2d(x,w):
return tf.nn.conv2d(x,w,strides=[1,1,1,1],padding='SAME') #定义一个函数,用于构建池化层
def max_pool_2x2(x):
return tf.nn.max_pool(x,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME') #placceholder 基本都是用于占位符 后面用到先定义
x = tf.placeholder(tf.float32,[None,784])
y_ = tf.placeholder(tf.float32,[None,10])
x_image = tf.reshape(x,[-1,28,28,1]) #将数据reshape成适合的维度来进行后续的计算 #第一个卷积层的定义
W_conv1 = weight_variable([5,5,1,32])
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image,W_conv1) + b_conv1) #激活函数为relu
h_pool1 = max_pool_2x2(h_conv1) #2x2 的max pooling #第二个卷积层的定义
W_conv2 = weight_variable([5,5,32,64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1,W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2) #第一个全连接层的定义
W_fc1 = weight_variable([7*7*64,1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2,[-1,7*7*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat,W_fc1) + b_fc1) #将第一个全连接层 进行dropout 随机丢掉一些神经元不参与运算
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1,keep_prob) #第二个全连接层 分为十类数据 softmax后输出概率最大的数字
W_fc2 = weight_variable([1024,10])
b_fc2 = bias_variable([10])
y_conv = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y_conv),reduction_indices=[1])) #交叉熵
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy) #这里用Adam优化器 优化 也可以使用随机梯度下降 correct_predition = tf.equal(tf.argmax(y_conv,1),tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_predition,tf.float32)) #准确率 tf.initialize_all_variables().run() #使用全局参数初始化器 并调用run方法 来进行参数初始化 for i in range(20000):
batch = mnist.train.next_batch(50)
if i%100 == 0:
train_accuracy = accuracy.eval(feed_dict={x:batch[0],y_:batch[1],keep_prob:1.0}) #每一百次验证一下准确率
print "step %d,training accuracy %g"%(i,train_accuracy) train_step.run(feed_dict={x:batch[0],y_:batch[1],keep_prob:0.5}) #batch[0] [1] 分别指数据维度 和标记维度 将数据传入定义好的优化器进行训练 print "test accuracy %g"%accuracy.eval(feed_dict={x:mnist.test.images,y_:mnist.test.labels,keep_prob:1.0}) #开始测试数据
若有兴趣交流分享技术,可关注本人公众号,里面会不定期的分享各种编程教程,和共享源码,诸如研究分享关于c/c++,python,前端,后端,opencv,halcon,opengl,机器学习深度学习之类有关于基础编程,图像处理和机器视觉开发的知识

深度学习(五)基于tensorflow实现简单卷积神经网络Lenet5的更多相关文章
- 21个项目玩转深度学习:基于TensorFlow的实践详解01—MNIST机器学习入门
数据集 由Yann Le Cun建立,训练集55000,验证集5000,测试集10000,图片大小均为28*28 下载 # coding:utf-8 # 从tensorflow.examples.tu ...
- 深度学习:Keras入门(二)之卷积神经网络(CNN)
说明:这篇文章需要有一些相关的基础知识,否则看起来可能比较吃力. 1.卷积与神经元 1.1 什么是卷积? 简单来说,卷积(或内积)就是一种先把对应位置相乘然后再把结果相加的运算.(具体含义或者数学公式 ...
- 深度学习:Keras入门(二)之卷积神经网络(CNN)【转】
本文转载自:https://www.cnblogs.com/lc1217/p/7324935.html 说明:这篇文章需要有一些相关的基础知识,否则看起来可能比较吃力. 1.卷积与神经元 1.1 什么 ...
- 深度学习:Keras入门(二)之卷积神经网络(CNN)(转)
转自http://www.cnblogs.com/lc1217/p/7324935.html 1.卷积与神经元 1.1 什么是卷积? 简单来说,卷积(或内积)就是一种先把对应位置相乘然后再把结果相加的 ...
- 学习笔记TF057:TensorFlow MNIST,卷积神经网络、循环神经网络、无监督学习
MNIST 卷积神经网络.https://github.com/nlintz/TensorFlow-Tutorials/blob/master/05_convolutional_net.py .Ten ...
- 深度学习基础-基于Numpy的多层前馈神经网络(FFN)的构建和反向传播训练
本文是深度学习入门: 基于Python的实现.神经网络与深度学习(NNDL)以及花书的读书笔记.本文将以多分类任务为例,介绍多层的前馈神经网络(Feed Forward Networks,FFN)加上 ...
- 21个项目玩转深度学习:基于TensorFlow的实践详解02—CIFAR10图像识别
cifar10数据集 CIFAR-10 是由 Hinton 的学生 Alex Krizhevsky 和 Ilya Sutskever 整理的一个用于识别普适物体的小型数据集.一共包含 10 个类别的 ...
- 21个项目玩转深度学习:基于TensorFlow的实践详解03—打造自己的图像识别模型
书籍源码:https://github.com/hzy46/Deep-Learning-21-Examples CNN的发展已经很多了,ImageNet引发的一系列方法,LeNet,GoogLeNet ...
- 21个项目玩转深度学习:基于TensorFlow的实践详解06—人脸检测和识别——项目集锦
摘自:https://github.com/azuredsky/mtcnn-2 mtcnn - Multi-task CNN library language dependencies comment ...
随机推荐
- CSVHelper 导出CSV 格式
public class CSVHelper { System.Windows.Forms.SaveFileDialog saveFileDialog1;//保存 private string hea ...
- java 七牛上传图片到服务器(采用的html5 压缩 传输base64方式)
//html 页面如下<div class="form-group"> <label class="col-sm-2 control-label&quo ...
- select2的搜索框不能输入搜索内容
按照select2官网配置完后,搜索框弹出后无法输入内容,究竟怎么回事,于是在其他页面尝试了select2,发现可以啊,为什么在这个地方不可以,终于找到了造成这个问题的不同之处:select2在模态对 ...
- angular 守卫路由
import { NgModule } from '@angular/core'; import { Routes, RouterModule } from '@angular/router'; im ...
- EF 热加载 Winform/Asp.net
public partial class Form1 : Form { BackgroundWorker worker = new BackgroundWorker(); xxContext cont ...
- Java 根据Date计算年龄
- php代码审计7审计csrf漏洞
跨站请求伪造,也有人写出xsrf,黑客伪造用户的http请求,然后将http请求发送给存在csrf的网站,网站执行了伪造的http请求,就引发了跨站请求伪造 漏洞危害:攻击者盗用了你的身份信息,以你的 ...
- Django 实现上传图片功能
很多时候我们要用到图片上传功能,如果图片一直用放在别的网站上,通过加载网址的方式来显示的话其实也挺麻烦的,我们通过使用 django-filer 这个模块实现将图片文件直接放在自己的网站上. 感兴趣的 ...
- POJ-3468-A Simple Problem with Integers(线段树 区间更新 区间和)
A Simple Problem with Integers Time Limit: 5000MS Memory Limit: 131072K Total Submissions: 139191 ...
- 条目八《永不建立auto_ptr的容器》
条目八<永不建立auto_ptr的容器> 重要的事说三次,永不建立auto_ptr的容器,永不建立auto_ptr的容器,永不建立auto_ptr的容器!!! 为什么? 实质是auto_p ...