tlflearn 编码解码器 ——数据降维用
# -*- coding: utf-8 -*- """ Auto Encoder Example.
Using an auto encoder on MNIST handwritten digits.
References:
Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner. "Gradient-based
learning applied to document recognition." Proceedings of the IEEE,
86(11):2278-2324, November 1998.
Links:
[MNIST Dataset] http://yann.lecun.com/exdb/mnist/
"""
from __future__ import division, print_function, absolute_import import numpy as np
import matplotlib.pyplot as plt
import tflearn # Data loading and preprocessing
import tflearn.datasets.mnist as mnist
X, Y, testX, testY = mnist.load_data(one_hot=True) # Building the encoder
encoder = tflearn.input_data(shape=[None, 784])
encoder = tflearn.fully_connected(encoder, 256)
encoder = tflearn.fully_connected(encoder, 64) # Building the decoder
decoder = tflearn.fully_connected(encoder, 256)
decoder = tflearn.fully_connected(decoder, 784, activation='sigmoid') # Regression, with mean square error
net = tflearn.regression(decoder, optimizer='adam', learning_rate=0.001,
loss='mean_square', metric=None) # Training the auto encoder
model = tflearn.DNN(net, tensorboard_verbose=0)
model.fit(X, X, n_epoch=20, validation_set=(testX, testX),
run_id="auto_encoder", batch_size=256) # Encoding X[0] for test
print("\nTest encoding of X[0]:")
# New model, re-using the same session, for weights sharing
encoding_model = tflearn.DNN(encoder, session=model.session)
print(encoding_model.predict([X[0]])) # Testing the image reconstruction on new data (test set)
print("\nVisualizing results after being encoded and decoded:")
testX = tflearn.data_utils.shuffle(testX)[0]
# Applying encode and decode over test set
encode_decode = model.predict(testX)
# Compare original images with their reconstructions
f, a = plt.subplots(2, 10, figsize=(10, 2))
for i in range(10):
temp = [[ii, ii, ii] for ii in list(testX[i])]
a[0][i].imshow(np.reshape(temp, (28, 28, 3)))
temp = [[ii, ii, ii] for ii in list(encode_decode[i])]
a[1][i].imshow(np.reshape(temp, (28, 28, 3)))
f.show()
plt.draw()
plt.waitforbuttonpress()
运行效果图:

深度学习——keras训练AutoEncoder模型
深度学习——keras训练AutoEncoder模型
安装keras:
先安装anaconda,再运行conda install keras,参照:
http://blog.csdn.net/qq_32329377/article/details/53008019
下载AutoEncoder模型训练代码:
https://github.com/MorvanZhou/tutorials/tree/master/kerasTUT
注意:需给每个文件加# -*- coding: utf-8 -*,否则会出现noASCII错误。
训练代码细解:
自编码,简单来说就是把输入数据进行一个压缩和解压缩的过程。原来有很多特征,压缩成几个来代表原来的数据,解压之后恢复成原来的维度,再和原数据进行比较。它是一种非监督算法,只需要输入数据,解压缩之后的结果与原数据本身进行比较。程序的主要功能是把
datasets.mnist 数据的 28*28=784 维的数据,压缩成 2 维的数据,然后在一个二维空间中可视化出分类的效果。首先,导入数据并进行数据预处理,本例使用Model模块的Keras的泛化模型来进行模型搭建,便于我们从模型中间导出数据并进行可视化。进行模型搭建的时候,注意要进行逐层特征提取,最终压缩至2维,解码的过程要跟编码过程一致相反。随后对Autoencoder和encoder分别建模,编译、训练。将编码模型的预测结果通过Matplotlib可视化出来,就可以看到原数据的二维编码结果在二维平面上的聚类效果,还是很明显的。
- 导入相关Python和keras模块(module):
import numpy as np
np.random.seed(1337) # for reproducibility
from keras.datasets import mnist
from keras.models import Model #泛型模型
from keras.layers import Dense, Input
import matplotlib.pyplot as plt - 1
- 2
- 3
- 4
- 5
- 6
- 7
需要注意的是,如果在Ubuntu下我们使用的远程命令行方式,因为在远程命令行的环境下显示不了图形界面,所以需要加入下面的两行代码(且需放在import matplotlib.pyplot as plt前),否则会运行报错。但是在Ubuntu的图形化界面下(比如,远程桌面或VNC Viewer)不需要。
import matplotlib
matplotlib.use('Agg')- 1
- 2
- 加载数据集
# x shape (60,000 28x28), y shape (10,000, )
(x_train, _), (x_test, y_test) = mnist.load_data()- 1
- 2
- 数据预处理
# data pre-processing
x_train = x_train.astype('float32') / 255. - 0.5 # minmax_normalized
x_test = x_test.astype('float32') / 255. - 0.5 # minmax_normalized
x_train = x_train.reshape((x_train.shape[0], -1))
x_test = x_test.reshape((x_test.shape[0], -1))
print(x_train.shape)
print(x_test.shape)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 压缩特征维度至2维
encoding_dim = 2- 1
接下来就是建立encoded和decoded,再用 autoencoder 把二者组建在一起。训练时用 autoencoder。
- 建立编码层
encoded = Dense(128, activation='relu')(input_img)
encoded = Dense(64, activation='relu')(encoded)
encoded = Dense(10, activation='relu')(encoded)
encoder_output = Dense(encoding_dim)(encoded)- 1
- 2
- 3
- 4
encoded 用4层 Dense 全联接层,激活函数用 relu,输入的维度就是前一步定义的 input_img。
接下来定义下一层,它的输出维度是64,输入是上一层的输出结果。
在最后一层,我们定义它的输出维度就是想要的 encoding_dim=2。
- 建立解码层
decoded = Dense(10, activation='relu')(encoder_output)
decoded = Dense(64, activation='relu')(decoded)
decoded = Dense(128, activation='relu')(decoded)
decoded = Dense(784, activation='tanh')(decoded) - 1
- 2
- 3
- 4
解压的环节,它的过程和压缩的过程是正好相反的。相对应层的激活函数也是一样的,不过在解压的最后一层用到的激活函数是 tanh。 因为输入值是由 -0.5 到 0.5 这个范围,在最后一层用这个激活函数的时候,它的输出是 -1 到 1,可以是作为一个很好的对应。
- 构建自编码模型
autoencoder = Model(inputs=input_img, outputs=decoded)- 1
直接用 Model 这个模块来组建模型,输入就是图片,输出是解压的最后的结果。
- 模型组建
encoder = Model(inputs=input_img, outputs=encoder_output) - 1
由 784维压缩到 2维,输入是图片,输出是压缩环节的最后结果。
- 编译模型
autoencoder.compile(optimizer='adam', loss='mse') - 1
优化器用的是 adam,损失函数用的是 mse
- 训练模型
autoencoder.fit(x_train, x_train, epochs=20, batch_size=256, shuffle=True) - 1
由于autocoder是一个压缩和解压的过程,所以它的输入和输出是一样的,都是训练集x。
- 可视化
encoded_imgs = encoder.predict(x_test)
plt.scatter(encoded_imgs[:, 0], encoded_imgs[:, 1], c=y_test, s=3)
plt.colorbar()
plt.show() - 1
- 2
- 3
- 4
终端操作:
ubuntu上:
打开到代码目录:
cd ~/keras/tutorials/kerasTUT- 1
开始训练:
python 9-Autoencoder_example.py- 1
训练结果图:
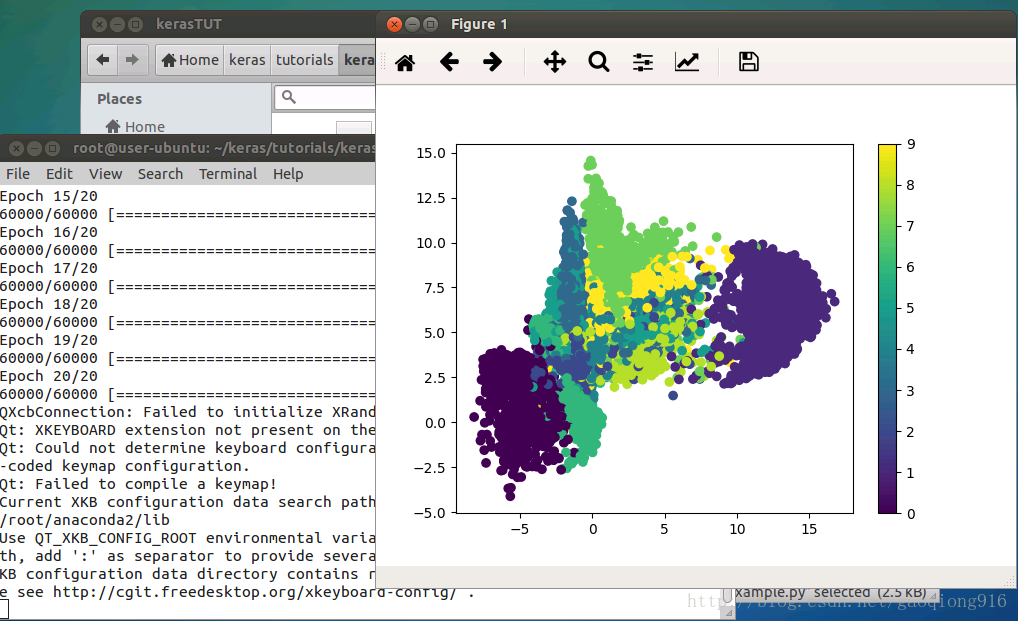
文章借鉴https://morvanzhou.github.io/tutorials/machine-learning/keras/2-6-autoencoder/
其他示例:见:https://blog.csdn.net/qq_36829947/article/details/79079537 原文,代码有缺失!

“自编码”是一种数据压缩算法,其中压缩和解压缩功能是1)数据特定的,2)有损的,3)从例子中自动学习而不是由人工设计。此外,在几乎所有使用术语“自动编码器”的情况下,压缩和解压缩功能都是用神经网络来实现的。
1)自动编码器是特定于数据的,这意味着它们只能压缩类似于他们所训练的数据。这与例如MPEG-2音频层III(MP3)压缩算法不同,后者通常只保留关于“声音”的假设,而不涉及特定类型的声音。在面部图片上训练的自动编码器在压缩树的图片方面做得相当差,因为它将学习的特征是面部特定的。
2)自动编码器是有损的,这意味着与原始输入相比,解压缩的输出会降低(类似于MP3或JPEG压缩)。这与无损算术压缩不同。
3)自动编码器是从数据实例中自动学习的,这是一个有用的属性:这意味着很容易培养算法的特定实例,在特定类型的输入上运行良好。它不需要任何新的工程,只需要适当的培训数据。
要构建一个自动编码器,需要三件事情:编码函数,解码函数和数据压缩表示与解压缩表示(即“丢失”函数)之间的信息损失量之间的距离函数。编码器和解码器将被选择为参数函数(通常是神经网络),并且相对于距离函数是可微分的,因此可以优化编码/解码函数的参数以最小化重构损失,使用随机梯度下降。这很简单!而且你甚至不需要理解这些词语在实践中开始使用自动编码器。
什么是自动编码器的好处?
二、使用Keras建立简单的自编码器
1. 单隐含层自编码器
建立一个全连接的编码器和解码器。也可以单独使用编码器和解码器,在此使用Keras的函数式模型API即Model可以灵活地构建自编码器。
50个epoch后,看起来我们的自编码器优化的不错了,损失val_loss: 0.1037。
- fromimport
fromimport
fromimport
import
import) /
- ) /
- :])))
- :])))
- print
print - ,))
- )(input_img)
- , activation=)(encoded)
- ]
- 'adadelta')
- , batch_size=,
- , validation_data=(x_test, x_test))
- 20))
- forin
, n, i + ) - , ))
- )
- )
- , n, i + + n)
- , ))
- )
- )
- plt.show()
2. 稀疏自编码器、深层自编码器
为码字加上稀疏性约束。如果我们对隐层单元施加稀疏性约束的话,会得到更为紧凑的表达,只有一小部分神经元会被激活。在Keras中,我们可以通过添加一个activity_regularizer达到对某层激活值进行约束的目的。
encoded = Dense(encoding_dim, activation='relu',activity_regularizer=regularizers.activity_l1(10e-5))(input_img)
把多个自编码器叠起来即加深自编码器的深度,50个epoch后,损失val_loss:0.0926,比1个隐含层的自编码器要好一些。
- import
1337 - fromimport
fromimport - fromimport
import# X shape (60,000 28x28), y shape (10,000, )
# 数据预处理
) / - ) /
- ], -))
- ], -))
- print
print# 压缩特征维度至2维
- # this is our input placeholder
,)) - # 编码层
, activation=)(input_img) - , activation=)(encoded)
- , activation=)(encoded)
- # 解码层
, activation=)(encoder_output) - , activation=)(decoded)
- , activation=)(decoded)
- , activation=)(decoded)
- # 构建自编码模型
# 构建编码模型
# compile autoencoder
'adam') - # training
, batch_size=, shuffle=) - # plotting
], encoded_imgs[:, ], c=y_test,s=)
- # use Matplotlib (don't ask)
import - 20))
- forin
- , n, i + )
- , ))
- )
- )
- , n, i + + n)
- , ))
- )
- )
- plt.show()
3. 卷积自编码器:用卷积层构建自编码器
当输入是图像时,使用卷积神经网络是更好的。卷积自编码器的编码器部分由卷积层和MaxPooling层构成,MaxPooling负责空域下采样。而解码器由卷积层和上采样层构成。50个epoch后,损失val_loss: 0.1018。
- fromimport
fromimport
fromimport
import
import
fromimport, , ))
- , (, ), activation=, padding=)(input_img)
- , ), padding=)(x)
- , (, ), activation=, padding=)(x)
- , ), padding=)(x)
- , (, ), activation=, padding=)(x)
- , ), padding=)(x)
- , (, ), activation=, padding=)(encoded)
- , ))(x)
- , (, ), activation=, padding=)(x)
- , ))(x)
- , (, ), activation=)(x)
- , ))(x)
- , (, ), activation=, padding=)(x)
- 'adadelta')
- # 打开一个终端并启动TensorBoard,终端中输入 tensorboard --logdir=/autoencoder
, batch_size=, - , validation_data=(x_test, x_test),
- )])
- decoded_imgs = autoencoder.predict(x_test)
UpSampling2D
上采样,扩大矩阵,可以用于复原图像等。

keras.layers.convolutional.UpSampling2D(size=(2, 2), data_format=None)
将数据的行和列分别重复size[0]和size[1]次
4. 使用自动编码器进行图像去噪
我们把训练样本用噪声污染,然后使解码器解码出干净的照片,以获得去噪自动编码器。首先我们把原图片加入高斯噪声,然后把像素值clip到0~1。
ps:去噪自编码器(denoisingautoencoder, DAE)是一类接受损坏数据作为输入,并训练来预测原始未被损坏数据作为输出的自编码器。
- #去噪 自编码器
fromimport
fromimport
fromimport
import
import
fromimport) /
- ) /
- , , ))
- , , ))
- , scale=, size=x_train.shape)
- , scale=, size=x_test.shape)
- , )
- , )
- print
print, , ))
- 3233'relu''same'
22'same'
3233'relu''same'
22'same'3233'relu''same'
22
3233'relu''same'
22
133'sigmoid''same''adam''binary_crossentropy'
# 打开一个终端并启动TensorBoard,终端中输入 tensorboard --logdir=/autoencoder
, batch_size=, - , validation_data=(x_test_noisy, x_test),
- , write_graph=)])
- 306
- 10
forin
,n,i+) - ,))
- )
- )
- ,n,i++n)
- ,))
- )
- )
- ,n,i++*n)
- ,))
- )
- )
- plt.show()
深度学习
tlflearn 编码解码器 ——数据降维用的更多相关文章
- PCA 实例演示二维数据降成1维
import numpy as np # 将二维数据降成1维 num = [(2.5, 2.4), (0.5, 0.7), (2.2, 2.9), (1.9, 2.2), (3.1, 3.0), (2 ...
- Coursera《machine learning》--(14)数据降维
本笔记为Coursera在线课程<Machine Learning>中的数据降维章节的笔记. 十四.降维 (Dimensionality Reduction) 14.1 动机一:数据压缩 ...
- Echarts之悬浮框中的数据排序
Echarts非常强大,配置也非常的多,有很多细节需要深入研究.详解一下关于悬浮框中的数据排序问题 悬浮框的数据排序默认是根据series中的数据位置排序的,在我们想自定义排序时,在echarts的配 ...
- 机器学习实战(Machine Learning in Action)学习笔记————09.利用PCA简化数据
机器学习实战(Machine Learning in Action)学习笔记————09.利用PCA简化数据 关键字:PCA.主成分分析.降维作者:米仓山下时间:2018-11-15机器学习实战(Ma ...
- 数据降维(Dimensionality reduction)
数据降维(Dimensionality reduction) 应用范围 无监督学习 图片压缩(需要的时候在还原回来) 数据压缩 数据可视化 数据压缩(Data Compression) 将高维的数据转 ...
- 记一次Oracle数据故障排除过程
前天在Oracle生产环境中,自己的存储过程运行时间超过1小时,怀疑是其他job运行时间过长推迟了自己job运行时间,遂重新跑job,发现同测试环境的确不同,运行了25分钟. 之后准备在测试环境中制造 ...
- 数据降维-PCA主成分分析
1.什么是PCA? PCA(Principal Component Analysis),即主成分分析方法,是一种使用最广泛的数据降维算法.PCA的主要思想是将n维特征映射到k维上,这k维是全新的正交特 ...
- keras使用AutoEncoder对mnist数据降维
import keras import matplotlib.pyplot as plt from keras.datasets import mnist (x_train, _), (x_test, ...
- 【Python代码】TSNE高维数据降维可视化工具 + python实现
目录 1.概述 1.1 什么是TSNE 1.2 TSNE原理 1.2.1入门的原理介绍 1.2.2进阶的原理介绍 1.2.2.1 高维距离表示 1.2.2.2 低维相似度表示 1.2.2.3 惩罚函数 ...
随机推荐
- 我的Android进阶之旅------>Android中adb install 安装错误常见列表
adb的安装过程分为传输与安装两步. 在出错后,adb会报告错误信息,但是信息可能只是一个代号,需要自己定位分析出错的原因. 下面是从网上找到的几种常见的错误及解决方法: 1.INSTALL_FAIL ...
- P2P-BT对端管理协议(附BT协议1.0)
对端管理 指的是远端peer集合的管理(尽管自身client也能够视为一个peer.但对端管理不包括自身peer) 一个client(client)必须维持与每一个远程peer连接的状态信息,即1V1 ...
- 如何删除github中的仓库?
使用Github管理项目确实有些好处,但删除仓库(repositories)确实不太好找到. 首先进入要删除的仓库,点击右下角的“settings” 然后拉到页面最下面在danger zone 按“d ...
- zabbix-2.4.8-1添加nginx状态监控
前期准备:nginx在编译是必须要加如下参数: 并且要在nginx的配置文件中添加如下配置: server { listen *: default_server; server_name localh ...
- Google Cloud Platfrom中运行基础的Apache Web服务
Links: https://cloud.google.com/compute/docs/tutorials/basic-webserver-apache 步骤: 1.安装Apache 2.重写Apa ...
- Groovy系列-groovy比起Java--有哪些地方写起来更舒服?
groovy比起java-有哪些地方写起来更舒服 java发展缓慢,语法落后冗余 说起java,其实java挺好的,java现在的性能也不错,但是,java的语法显然比较落后,而且冗余,getter/ ...
- 20160418 while,switch,do..while的使用
9 一.While循环 示例:求100以内所有数的和 Int i=1;//初始条件 Int sum=0; While(i<=100)//循环条件 { Sum+=i;//循环体 i++;//状态改 ...
- 解决 flex align-items:center 无法居中(微信小程序)
因为最近再做小程序,需要用到flex布局,因为写惯了web项目,初次学习确实感弹性布局的强大(关键是不用再管可恶的ie了). 但是也遇到了align-items:center无法居中的问题,想了很久终 ...
- VMWare中安装windowsXP遇到的问题
XP系统安装 1.安装Windows和安装linux不一样,创建虚拟机完成后Linux自动根据硬盘进行系统安装,不需要提前分区.而windows必须进行提前分区,这个分区是在虚拟磁盘上完成的,就是你创 ...
- Java 集合系列13之 TreeMap详细介绍(源码解析)和使用示例
转载 http://www.cnblogs.com/skywang12345/p/3310928.html https://www.jianshu.com/p/454208905619