Project2--Lucene的Ranking算法修改:BM25算法
原文出自:http://blog.csdn.net/wbia2010lkl/article/details/6046661
1. BM25算法
BM25是二元独立模型的扩展,其得分函数有很多形式,最普通的形式如下:
∑ 
其中,k1,k2,K均为经验设置的参数,fi是词项在文档中的频率,qfi是词项在查询中的频率。
K1通常为1.2,通常为0-1000
K的形式较为复杂
K=
上式中,dl表示文档的长度,avdl表示文档的平均长度,b通常取0.75
2. BM25具体实现
由于在典型的情况下,没有相关信息,即r和R都是0,而通常的查询中,不会有某个词项出现的次数大于1。因此打分的公式score变为
∑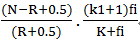
3. 使用Lucene实现BM25
Lucene本身的打分函数集中体现在tf·idf
为了简化实现过程,直接将代码中tf和idf函数的返回值修改为BM25打分公式的两部分。
文档的平均长度在索引建立的时候取得,同时在建立索引的过程中,将每个文档的docID与其长度,保存在一个hashMap中。
具体的函数实现如下(DefaulSimilarity类):
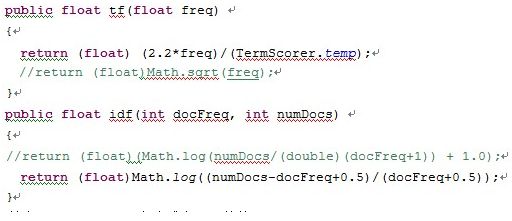
其中TermScore.temp为公式中K+fi的值
Temp的计算在TermScore类中进行计算:
public float score() {
assert doc != -1;
int f = freqs[pointer];
temp=(float)(1.2*(0.25+0.75*FileSearch.docToken.get(doc))+f);
System.out.println("weightValue: "+weightValue);
float raw = getSimilarity().tf(f)*weightValue; //
compute tf(f)*weight
//f < SCORE_CACHE_SIZE // check cache
//? scoreCache[f]*temp // cache hit
//: getSimilarity().tf(f)*weightValue*temp; // cache miss
System.out.println("score func doc id :"+doc+"
"+temp+" "+f+" "+
getSimilarity().tf(f));
System.out.println("raw value is"+raw);
return norms == null ?
raw : raw * SIM_NORM_DECODER[norms[doc]
& 0xFF];
}
值得注意的是:在lucene的得分计算中,使用explain函数可以看出,除了tf、idf的乘积之外,还有一个fieldNorm值,这个值的计算是基于索引的建立过程,与文档以及field的长度有关,综合考虑,这个值对于查询的过程还是比较有效的,因此在具体实现中,依然保存了fieldNorm的值。
Project2--Lucene的Ranking算法修改:BM25算法的更多相关文章
- 文本相似度 — TF-IDF和BM25算法
1,$TF-IDF$算法 $TF$是指归一化后的词频,$IDF$是指逆文档频率.给定一个文档集合$D$,有$d_1, d_2, d_3, ......, d_n \in D$.文档集合总共包含$m$个 ...
- 文本相似度-BM25算法
BM25 is a bag-of-words retrieval function that ranks a set of documents based on the query terms app ...
- Okapi BM25算法
引言 Okapi BM25,一般简称 BM25 算法,在 20 世纪 70 年代到 80 年代,由英国一批信息检索领域的计算机科学家发明.这里的 BM 是"最佳匹配"(Best M ...
- 分布式一致性算法:Raft 算法(论文翻译)
Raft 算法是可以用来替代 Paxos 算法的分布式一致性算法,而且 raft 算法比 Paxos 算法更易懂且更容易实现.本文对 raft 论文进行翻译,希望能有助于读者更方便地理解 raft 的 ...
- 【转】分布式一致性算法:Raft 算法(Raft 论文翻译)
编者按:这篇文章来自简书的一个位博主Jeffbond,读了好几遍,翻译的质量比较高,原文链接:分布式一致性算法:Raft 算法(Raft 论文翻译),版权一切归原译者. 同时,第6部分的集群成员变更读 ...
- Levenshtein Distance算法(编辑距离算法)
编辑距离 编辑距离(Edit Distance),又称Levenshtein距离,是指两个字串之间,由一个转成另一个所需的最少编辑操作次数.许可的编辑操作包括将一个字符替换成另一个字符,插入一个字符, ...
- ISAP算法对 Dinic算法的改进
ISAP算法对 Dinic算法的改进: 在刘汝佳图论的开头引言里面,就指出了,算法的本身细节优化,是比较复杂的,这些高质量的图论算法是无数优秀算法设计师的智慧结晶. 如果一时半会理解不清楚,也是正常的 ...
- 算法杂货铺——分类算法之朴素贝叶斯分类(Naive Bayesian classification)
算法杂货铺——分类算法之朴素贝叶斯分类(Naive Bayesian classification) 0.写在前面的话 我个人一直很喜欢算法一类的东西,在我看来算法是人类智慧的精华,其中蕴含着无与伦比 ...
- C++编程练习(11)----“图的最短路径问题“(Dijkstra算法、Floyd算法)
1.Dijkstra算法 求一个顶点到其它所有顶点的最短路径,是一种按路径长度递增的次序产生最短路径的算法. 算法思想: 按路径长度递增次序产生算法: 把顶点集合V分成两组: (1)S:已求出的顶点的 ...
随机推荐
- Python判断unicode是汉字,数字,英文,或者其他字符
功能: 判断unicode是否是汉字,数字,英文,或者是否是(汉字,数字和英文字符之外的)其他字符. 全角.半角符号相互转换. 全角.半角? 全角--指一个字符占用两个标准字符位置. 汉字字符和规定了 ...
- Android spannableStringBuilder用法整理
Android spannableStringBuilder用法整理 分类: Android开发2013-11-29 10:58 5009人阅读 评论(0) 收藏 举报 Androidspannabl ...
- HihoCoder 1185 : 连通性·三(强连通缩点)
连通性·三 时间限制:10000ms 单点时限:1000ms 内存限制:256MB 描述 暑假到了!!小Hi和小Ho为了体验生活,来到了住在大草原的约翰家.今天一大早,约翰因为有事要出去,就拜托小Hi ...
- 如何将u盘、移动硬盘转化为活动分区--绝招
https://jingyan.baidu.com/article/e75057f2a6a18aebc91a893e.html
- [C/C++]宽字符与控制台程序
转自:http://www.cnblogs.com/zplutor/archive/2010/11/27/1889227.html 在我刚开始学C/C++的时候,字符类型使用的都是char.接触Win ...
- django配置静态文件
django配置静态文件 参考文章链接:http://blog.csdn.net/hireboy/article/details/8806098
- openfaas 私有镜像配置
备注: 此项目是使用nodejs 生成唯一id 的\ 预备环境 docker harbor faas-cli openfaas k8s 1. 项目初始化 faas-cli new node --la ...
- 野村综合社,惠普2面,索尼,CDK面试经理
今天疯了一口气面试了四个企业,自我介绍都说了七八遍,晚上回家到头就睡.中间接了oracle的电话,也不知道如何. 11:00野村面试 野村综合社北京流通部 面试3个人,一个英语部门负责人,一个日语负责 ...
- 洛谷3778 [APIO2017]商旅
题目:https://www.luogu.org/problemnew/show/P3778 一看就是0/1分数规划.但不能直接套模板,因为有个商品种类的限制. 考虑从a买在b卖,商品种类根本没用,关 ...
- 【openCV学习笔记】在Mac上配置openCV步骤详解
(1)安装Homebrew:(需要Ruby) 注:因为snow leopard 以后已经自带Ruby了,所有可以不用自己安装Ruby. 看一下Homebrew的官网: http://mxcl.gith ...