大数据架构之:Kafka
Kafka 是一个高吞吐、分布式、基于发布订阅的消息系统,利用Kafka技术可在廉价PC Server上搭建起大规模消息系统。Kafka具有消息持久化、高吞吐、分布式、多客户端支持、实时等特性,适用于离线和在线的消息消费
Kakfa特点:
- 解耦:消息系统在处理过程中插入一个隐含、基于数据的接口层。
- 冗余:消息队列持久化,防止数据丢失。
- 扩展性:消息队列解耦处理过程,容易扩展处理过程。
- 可恢复性:处理过程失效,恢复后可继续处理。
- 顺序保证:消息队列保证顺序。Kafka保证一个Partition内消息有序。
- 异步通信:消息队列允许消息加入队列,等需要时再处理。
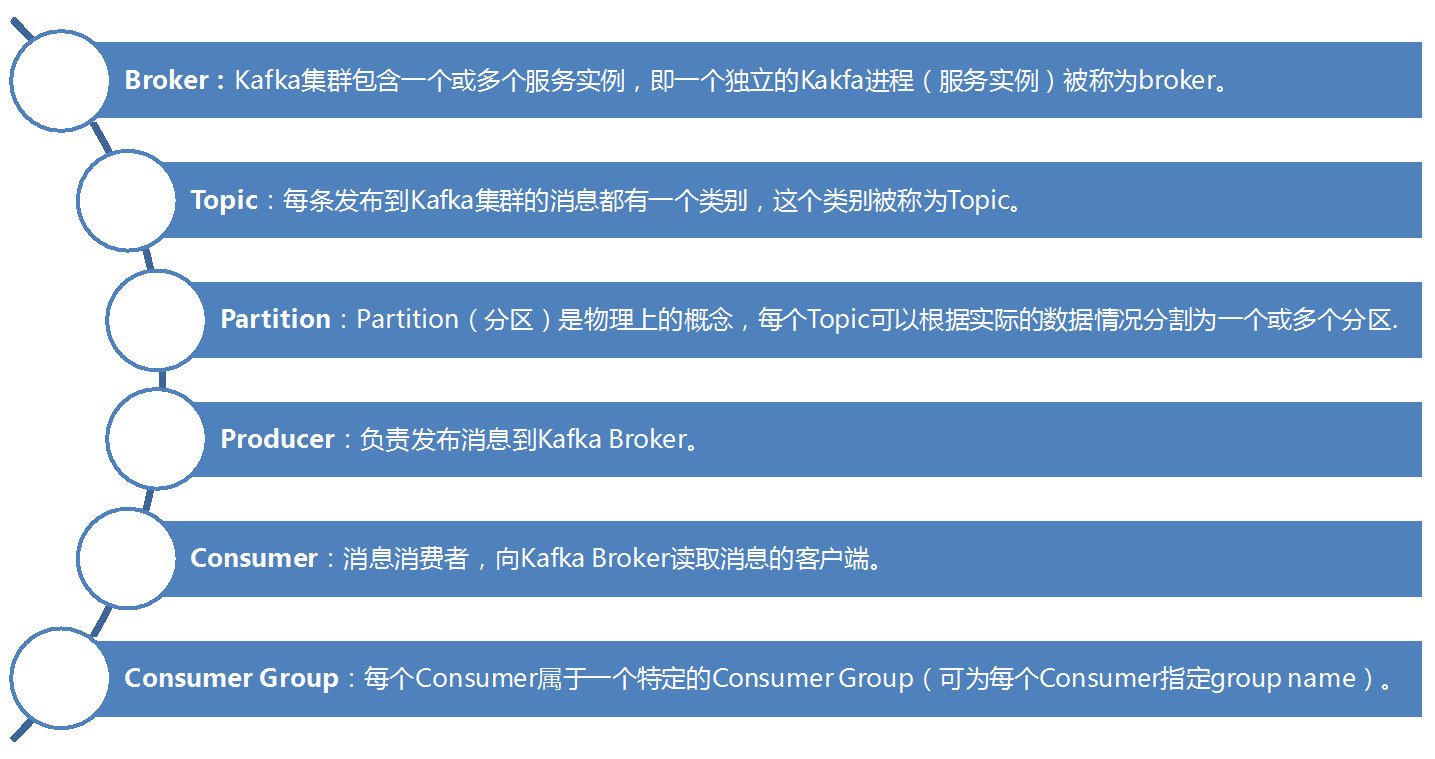
Kafka 的术语
Kafka 架构
典型Kafka架构
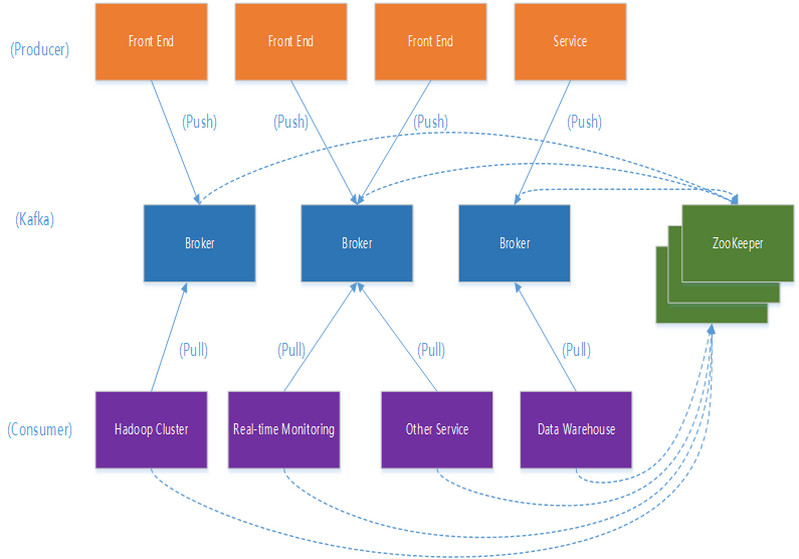
一个典型的Kafka集群中包含若干Producer(可以是web前端应用产生的消息,也可以是类似通过上网Flume收集上网日志产生的Events等),若干broker(Kafka支持水平扩展,一般broker数量越多,集群吞吐率越高),若干Consumer Group,以及一个Zookeeper集群。Kafka通过Zookeeper管理集群配置及服务协同。Producer使用push模式将消息发布到broker,Consumer通过监听使用pull模式从broker订阅并消费消息。
多个broker协同合作,producer和consumer部署在各个业务逻辑中被频繁的调用,三者通过zookeeper管理协调请求和转发。这样一个高性能的分布式消息发布和订阅系统就完成了。图上有个细节需要注意,producer刡broker的过程是push,也就是有数据就推送给broker,而consumer给broker的过程是pull,是通过consumer主动去拉数据的,而不是broker把数据主动发送给consumer端的。
producer、consumer、broker以及zookeeper返四者的关系
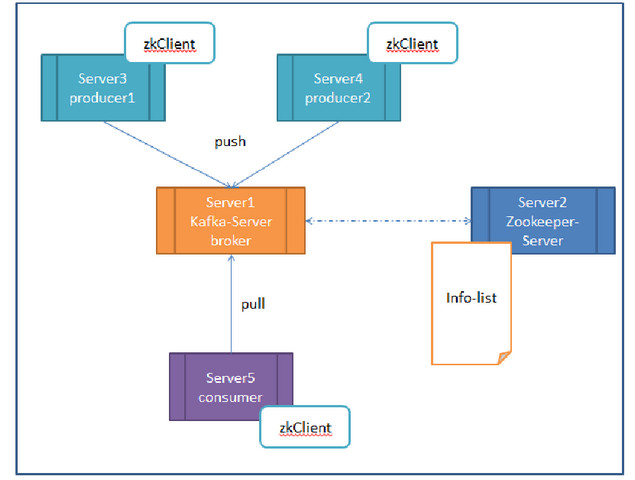
我们看上面的图,我们把broker的数量减少,叧有一台。现在假设我们按照上图进行部署:
Server-1 broker其实就是kafka的server,因为producer和consumer都要去连它。Broker主要还是做存储用。
Server-2是zookeeper的server端,zookeeper的具体作用你可以去上网查,在这里你可以先想象,它维持了一张表,记录了各个节点的IP、端口等信息(以后还会讲到,它里面还存了kafka的相关信息)。
Server-3、4、5他们的共同之处就是都配置了zkClient,更明确的说,就是运行前必须配置zookeeper的地址,道理也很简单,这之间的连接都是需要zookeeper来进行分发的。
Server-1和Server-2的关系,他们可以放在一台机器上,也可以分开放,zookeeper也可以配集群。目的是防止某一台挂了。
简单说下整个系统运行的顺序:
1. 启动zookeeper的server
2. 启动kafka的server
3. Producer如果生产了数据,会先通过zookeeper找到broker,然后将数据存放进broker
4. Consumer如果要消费数据,会先通过zookeeper找对应的broker,然后消费。
大数据架构之:Kafka的更多相关文章
- 后Hadoop时代的大数据架构(转)
原文:http://zhuanlan.zhihu.com/donglaoshi/19962491 作者: 董飞 提到大数据分析平台,不得不说Hadoop系统,Hadoop到现在也超过10年 ...
- 大数据架构师基础:hadoop家族,Cloudera产品系列等各种技术
大数据我们都知道hadoop,可是还会各种各样的技术进入我们的视野:Spark,Storm,impala,让我们都反映不过来.为了能够更好的架构大数据项目,这里整理一下,供技术人员,项目经理,架构师选 ...
- 后Hadoop时代的大数据架构
提到大数据分析平台,不得不说Hadoop系统,Hadoop到现在也超过10年的历史了,很多东西发生了变化,版本也从0.x进化到目前的2.6版本.我把2012年后定义成后Hadoop平台时代,这不是说不 ...
- 一篇了解大数据架构及Hadoop生态圈
一篇了解大数据架构及Hadoop生态圈 阅读建议,有一定基础的阅读顺序为1,2,3,4节,没有基础的阅读顺序为2,3,4,1节. 第一节 集群规划 大数据集群规划(以CDH集群为例),参考链接: ht ...
- 大数据架构-使用HBase和Solr将存储与索引放在不同的机器上
大数据架构-使用HBase和Solr将存储与索引放在不同的机器上 摘要:HBase可以通过协处理器Coprocessor的方式向Solr发出请求,Solr对于接收到的数据可以做相关的同步:增.删.改索 ...
- WOT干货大放送:大数据架构发展趋势及探索实践分享
WOT大数据处理技术分会场,PingCAP CTO黄东旭.易观智库CTO郭炜.Mob开发者服务平台技术副总监林荣波.宜信技术研发中心高级架构师王东及商助科技(99Click)顾问总监郑泉五位讲师, ...
- 学习《深度学习与计算机视觉算法原理框架应用》《大数据架构详解从数据获取到深度学习》PDF代码
<深度学习与计算机视觉 算法原理.框架应用>全书共13章,分为2篇,第1篇基础知识,第2篇实例精讲.用通俗易懂的文字表达公式背后的原理,实例部分提供了一些工具,很实用. <大数据架构 ...
- 大数据架构师必读的NoSQL建模技术
大数据架构师必读的NoSQL建模技术 从数据建模的角度对NoSQL家族系统做了比较简单的比较,并简要介绍几种常见建模技术. 1.前言 为了适应大数据应用场景的要求,Hadoop以及NoSQL等与传统企 ...
- Hbase和Hive在大数据架构中处在不同位置
先放结论:Hbase和Hive在大数据架构中处在不同位置,Hbase主要解决实时数据查询问题,Hive主要解决数据处理和计算问题,一般是配合使用.一.区别:Hbase: Hadoop database ...
随机推荐
- 【转】Monkey测试4——Monkey命令行可用的全部选项
Monkey命令行可用的全部选项 常规 --help 列出简单的用法. -v 命令行的每一个-v将增加反馈信息的级别. Level 0(缺省值)除启动提示.测试完成和最终结果之外,提供较少信息. Le ...
- OpenCV中Camshitf算法学习(补充)
结合OpenCV中Camshitf算法学习,做一些简单的补充,包括: 实现全自动跟随的一种方法 参考opencv中的相关demo,可以截取目标物体的图片,由此预先计算出其色彩投影图,用于实际的目标跟随 ...
- struts.properties文件
此配置文件提供了一种机制来更改默认行为的框架.其实所有的struts.propertiesconfiguration文件中包含的属性也可以被配置在web.xml中使用的init-param,以及在st ...
- 【翻译自mos文章】当点击完 finishbutton后,dbca 或者dbua hang住
当点击完 finishbutton后,dbca 或者dbua hang住 来源于: DBCA/DBUA APPEARS TO HANG AFTER CLICKING FINISH BUTTON (文档 ...
- js yield
meikidd 发布在meikidd2015年5月6日view:3397 在文章任何区域双击击即可给文章添加[评注]!浮到评注点上可以查看详情. 隐藏标注 首先请原谅我的标题党(●—●),tj 大神的 ...
- Eclipse集成resin服务器
就我遇到的问题来说吧: 1. resin-pro-4.0.36去官网下载,目前这是最新版,27M 2. Eclipse安装Resin服务器的插件 Help->Install New Soft-& ...
- [网络通信] OSI七层模型思维导图
ISO:国际标准化组织:OSI:开放系统互联 (部分描述不准确和不详细)
- 【BZOJ2186】[Sdoi2008]沙拉公主的困惑 线性筛素数
[BZOJ2186][Sdoi2008]沙拉公主的困惑 Description 大富翁国因为通货膨胀,以及假钞泛滥,政府决定推出一项新的政策:现有钞票编号范围为1到N的阶乘,但是,政府只发行编号与M! ...
- GBK和UTF-8文字编码的区别
UTF-8是一种国际化标准的文字编码,我们已知Windows系统程序已经将最初的UTF-8转向Unicode,而GBK的存在是为了中国国情而创造的,不过GBK也将伴随着中文字符的一直流传下去. GBK ...
- Connection cannot be null when 'hibernate.dialect' not set
严重: Exception sending context initialized event to listener instance of class [org.springframework.w ...