卡方分布、卡方独立性检验和拟合性检验理论及其python实现
如果你在寻找卡方分布是什么?如何实现卡方检验?那么请看这篇博客,将以通俗易懂的语言,全面的阐述卡方、卡方检验及其python实现。
1. 卡方分布
1.1 简介
抽样分布有三大应用:T分布、卡方分布和$\Gamma$分布。可以简单用四个字概括它们的作用:“以小博大”,即通过小数量的样本容量去预估总体容量的分布情况。这里开始介绍卡方分布。${\chi ^{\text{2}}}$分布在数理统计中具有重要意义。 ${\chi ^{\text{2}}}$分布是由阿贝(Abbe)于1863年首先提出的,后来由海尔墨特(Hermert)和现代统计学的奠基人之一的卡·皮尔逊(C K.Pearson)分别于1875年和1900年推导出来,是统计学中的一个非常有用的著名分布。
1.2 定义
若n个相互独立的随机变量${\xi _1},{\xi _2}, \cdots ,{\xi _n}$,均服从标准正态分布,则这n个服从标准正态分布的随机变量的平方和构成一新的随机变量${\text{X}}\left( {} \right)$,其分布规律称为卡方分布。记作:
$${\text{X}} \sim {\chi ^{\text{2}}}\left( k \right)$$
1.3 卡方分布的密度函数
$${f_k}(x) = \frac{{{{(1/2)}^{\frac{k}{2}}}}}{{\Gamma (k/2)}}{x^{\frac{k}{2} - 1}}{e^{ - \frac{x}{2}}}$$
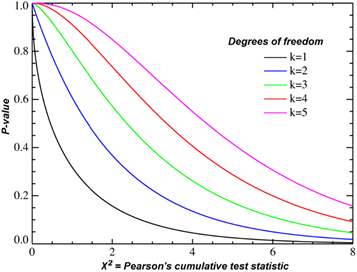
卡方分布的概率密度图
其中x≥0, 当x≤0时fk(x) = 0。这里$\Gamma$代表Gamma 函数。
在大多数涉及卡方分布的书中都会提供它的累积分布函数的对照表。此外许多表格计算软件如OpenOffice.org Calc和Microsoft Excel中都包括卡方分布函数。
卡方分布可以用来测试随机变量之间是否相互独立,也可用来检测统计模型是否符合实际要求。自由度为 k 的卡方变量的平均值是 k,方差是 2k。
1.4 性质(后续填坑)

2. 卡方检验
2.1 简介
卡方检验(chi-square,记为χ2\chi^2检验)是统计学中常用来计数数据分析的方法,对于总体的分布不作任何假设,因此它属于非参数检验法中的一种。本博文从理论到实际应用去阐述卡方检验,最后用python语言去实现卡方分布的代码。
${\chi ^{\text{2}}}$检验的基本思想是根据样本数据推断总体的频次与期望频次有显著性差异, ${\chi ^{\text{2}}}$的计算公式为:
$${\chi ^{\text{2}}} = \frac{{{{({f_0} - {f_e})}^2}}}{{{f_e}}}$$
其中,${{f_0}}$为实际观察频次,${{f_e}}$为理论值
这是卡方检验的原始公式,其中当${{f_e}}$越大,近似效果越好。显然${{f_0}}$与${{f_e}}$相差越大,卡方值就越大;${{f_0}}$与${{f_e}}$相差越小,卡方值就越小。因此它能够用来表示${{f_0}}$与${{f_e}}$相差的程度。根据这个公式,可认为卡方检验的一般问题是要检验名义型变量的实际观测次数和理论次数分布之间是否存在显著差异。
一般卡方检验方法进行统计检验时,要求样本容量不宜太小,理论次数$\geqslant 5$,否则需要进行校正。如果个别单元格的理论次数小于5,处理的方法有以下四种:
- 单元格合并法
- 增加样本数
- 去除样本数
- 使用校正公式,当某一期次数小于5时,应该利用校正公式计算卡方值。校正公式为:$${\chi ^{\text{2}}} = \sum {\frac{{{{(\left| {{f_0} - {f_e}} \right| - 0.5)}^2}}}{{{f_e}}}} $$
知道了卡方分布的原理,那具体是如何使用的呢?卡方分析有两个常见的应用——适合度(拟合性)分析和独立性分析。从我目前的经验来看,这也是应用十分广泛的一种统计分析方式。那么什么是卡方适合度分析和独立性分析呢?且听我慢慢道来。
“适配度检验”验证一组观察值的次数分配是否异于理论上的分配。
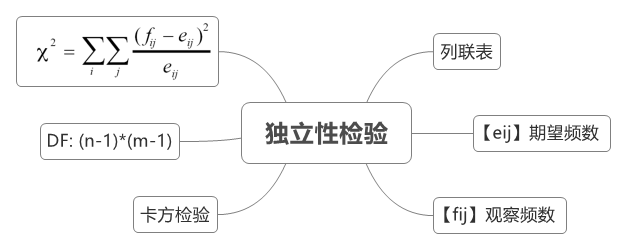
2.2 卡方独立性检验
“独立性检验”验证从两个变量抽出的配对观察值组是否互相独立(例如:每次都从A国和B国各抽一个人,看他们的反应是否与国籍无关)。
独立性检验主要用于两个或两个以上因素多项分类的计数资料分析,也就是研究两类变量之间的关联性和依存性问题。如果两变量无关联即相互独立,说明对于其中一个变量而言,另一变量多项分类次数上的变化是在无差范围之内;如果两变量有关联即不独立,说明二者之间有交互作用存在。
独立性检验一般采用列联表的形式记录观察数据, 列联表是由两个以上的变量进行交叉分类的频数分布表,是用于提供基本调查结果的最常用形式,可以清楚地表示定类变量之间是否相互关联。又可具体分为:
- 四格表的独立性检验:又称为2*2列联表的卡方检验。四格表资料的独立性检验用于进行两个率或两个构成比的比较,是列联表的一种最简单的形式。
- 行x列表资料的独立性检验:又称为RxC列联表的卡方检验。行x列表资料的独立性检验用于多个率或多个构成比的比较
2.3.1 独立性检验步骤
- Step1:建议原假设
H0:两变量相互独立;H1:两变量相互不独立
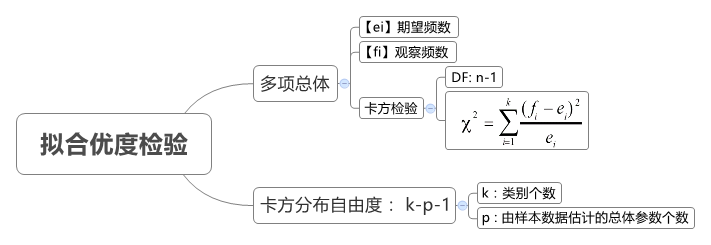
- Step2:计算自由度与理论频数
自由度:$df = (r - 1)(c - 1)$,理论频数:${e_{ij}} = \frac{{{F_{{Y_i}}} \cdot {F_{{X_j}}}}}{n}$
- Step3:计算统计量
$${\chi ^{\text{2}}} = \sum\limits_{i = 1}^r {\sum\limits_{j = 1}^c {\frac{{{{({f_{ij}} - {e_{ij}})}^2}}}{{{e_{ij}}}}} } \sim {\chi ^{\text{2}}}(df)$$
- Step4:查${\chi ^{\text{2}}}$分布临界值表,确定接受域和拒绝域
接受域:$${\chi ^{\text{2}}}_{1 - \frac{\alpha }{2}}(df) < {\chi ^{\text{2}}} < {\chi ^{\text{2}}}_{\frac{\alpha }{2}}(df)$$
2.3.2 应用条件
要求样本含量应大于40且每个格子中的理论频数不应小于5。当样本含量大于40但理论频数有小于5的情况时卡方值需要校正,即公式:$${\chi ^{\text{2}}} = \sum {\frac{{{{(\left| {{f_0} - {f_e}} \right| - 0.5)}^2}}}{{{f_e}}}} $$
2.3.3 应用实例
例:对下表所示频数分布表,以95%显著水平,检验色觉与性别是否有关。
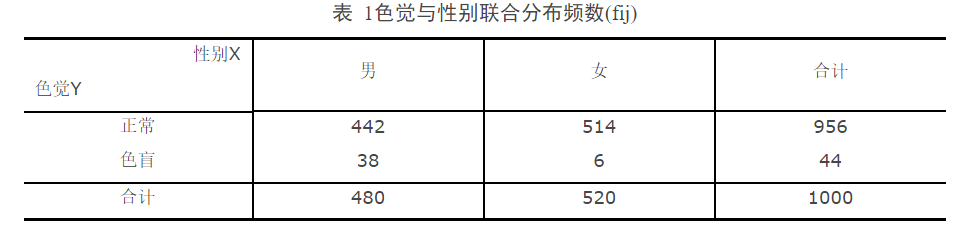
解:
- Step1:H0:色觉与性别相互独立;H1:色觉与性别相互不独立(相关)
- Step2:自由度$df = (r - 1)(c - 1) = (2 - 1)(2 - 1) = 1$,理论频数计算如表2。
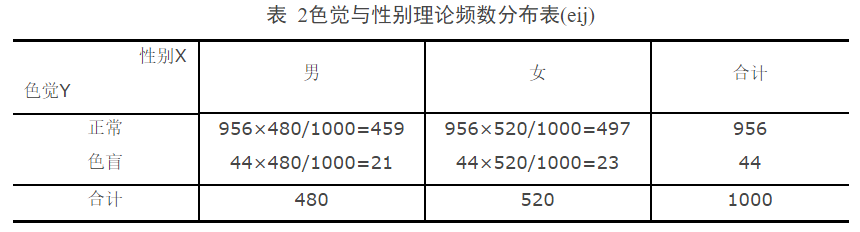
- Step3:计算统计量
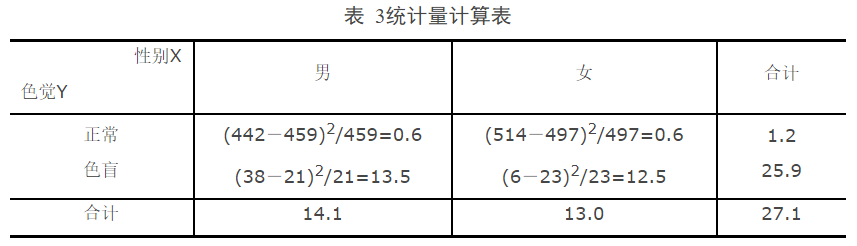
- Step4:查分布临界值表
$${\chi ^{\text{2}}}_{0.975}(1) = 0.00098,{\chi ^{\text{2}}}_{0.025}(1) = 5.0239$$
统计推断:${\chi ^{\text{2}}} = 27.1 > 5.0239$,所以拒绝原假设,即色觉与性别相互不独立。
2.3.4 RxC列联表的卡方检验
- 专用公式:
r行c列表资料卡方检验的${\chi ^{\text{2}}} = n \times (\frac{{{A_{11}}}}{{{n_1}{n_1}}} + \frac{{{A_{12}}}}{{{n_1}{n_2}}} + \cdots + \frac{{{A_{rc}}}}{{{n_r}{n_c}}}) - 1$
- 应用条件
要求每个格子中的理论频数T均大于5或1<T<5的格子数不超过总格子数的1/5。当有T<1或1<T<5的格子较多时,可采用并行并列、删行删列、增大样本含量的办法使其符合行x列表资料卡方检验的应用条件。多个率的两两比较可采用行x列表分割的办法。
独立性检验的理论频数的计算公式为:
$${f_e} = \frac{{{f_{xi}} \times {f_{yi}}}}{N}$$
2.3.5 独立性检验python实现
(1)环境配置
# -*- coding:utf-8 -*-
# @Time : 2018/6/29 18:08
# @Author : yuanjing liu
# @Email : lauyuanjing@163.com
# @File : 4.py
# @Software: PyCharm # 卡方独立性检验
import numpy as np
from scipy.stats import chi2_contingency
from scipy.stats import chi2
(2)卡方独立性检验函数
'''
(1)假设检验重要知识
H0:A与B相互独立 H1:A与B不相互独立
若卡方值大于临界值,拒绝原假设,表示A与B不相互独立,A与B相关
函数中re返回为1表示拒绝原假设,0表示接受原假设 (2)参数说明
输入:
alpha --- 置信度,用来确定临界值
data --- 数据,请使用numpy.array数组
输出:
g --- 卡方值,也就是统计量
p --- P值(统计学名词),与置信度对比,也可进行假设检验,P值小于置信度,即可拒绝原假设
dof --- 自由度
re --- 判读变量,1表示拒绝原假设,0表示接受原假设
expctd--- 原数据数组同维度的对应理论值 (3)应用场景
要求样本含量应大于40且每个格子中的理论频数不应小于5 理论知识详见博客:
''' def chi2_independence(alpha, data):
g, p, dof, expctd = chi2_contingency(data) if dof == 0:
print('自由度应该大于等于1')
elif dof == 1:
cv = chi2.isf(alpha * 0.5, dof)
else:
cv = chi2.isf(alpha * 0.5, dof-1) if g > cv:
re = 1 # 表示拒绝原假设
else:
re = 0 # 表示接受原假设 return g, p, dof, re, expctd
(3)测试
# test
alpha1 = 0.05 # 置信度,常用0.01,0.05,用于确定拒绝域的临界值
data1 = np.array([[442, 514], [38, 6]])
g, p, dof, re, expctd = chi2_independence(alpha1, data1)
(4)输出
g = 25.554809338151387
p = 4.2999294019586401e-07
dof = 1
re = 1
expctd = array([[ 458.88, 497.12], [ 21.12, 22.88]])
输出变量的含义,在函数处都已经说明,re=1表示拒绝原假设,结果和上面例子手算的一致。
2.4 卡方拟合性检验
2.4.1 定义
卡方检验能检验单个多项分类名义型变量各分类间的实际观测次数与理论次数之间是否一致的问题,这里的观测次数是根据样本数据得多的实计数,理论次数则是根据理论或经验得到的期望次数。这一类检验称为拟合性检验。其自由度通常为分类数减去1,理论次数通常根据某种经验或理论。
总而言之,卡方拟合度检验用于判断不同类型结果的比例分布相对于一个期望分布的拟合程度。
2.4.2 应用条件
卡方拟合性检验适用于变量为类别型变量的情况。 例如:变量为有罪或无罪。
当每个类别中观察到的或预期的频率太小时,此检验无效。要求样本含量应大于40且每个格子中的理论频数不应小于5
2.4.3 应用实例
随机抽取60名高一学生,问他们文理要不要分科,回答赞成的39人,反对的21人,问对分科的意见是否有显著的差异。
解:
(1)提出H0:学生们对文理分科的意见没有差异
(2)分析:如果没有显著的差异,则赞成与反对的各占一般,因此是一个无差假设的检验,于是理论次数为60/2=30,带入公式:
$${\chi ^{\text{2}}}{\text{ = }}\sum {\frac{{{{\left( {{f_0} - {f_e}} \right)}^2}}}{{{f_e}}}} = \frac{{{{\left( {39 - 30} \right)}^2}}}{{30}} + \frac{{{{\left( {21 - 30} \right)}^2}}}{{30}} = 5.4 > \chi _{0.05}^2\left( 1 \right) = 3.84$$
其中自由度df = 类别-1 = 2-1 = 1
所以拒绝原假设,认为对于文理分科,学生们的态度是有显著的差异的。
2.4.4 卡方拟合性检验python实现
(1)环境配置
# 卡方拟合性检验
import numpy as np
from scipy.stats import chisquare
from scipy.stats import chi2
(2)卡方独立性检验函数
'''
(1)假设检验重要知识
H0:类别A与B的比例没有差异 H1:类别A与B的比例有差异
若卡方值大于临界值,拒绝原假设,表示A与B不相互独立,A与B相关
函数中re返回为1表示拒绝原假设,0表示接受原假设 (2)参数说明
输入:
alpha --- 置信度,用来确定临界值
data --- 数据,请使用numpy.array数组
sp --- 表示输入数组的形状参数,默认为一维
输出:
chis --- 卡方值,也就是统计量
p_value --- P值(统计学名词),与置信度对比,也可进行假设检验,P值小于置信度,即可拒绝原假设
cv --- 拒绝域临界值
j --- 自由度
re --- 判读变量,1表示拒绝原假设,0表示接受原假设 (3)应用场景
要求样本含量应大于40且每个格子中的理论频数不应小于5 理论知识详见博客:
''' def chi2_fitting(data, alpha, sp=None):
chis, p_value = chisquare(data, axis=sp)
i, j = data.shape # j为自由度 if j == 0:
print('自由度应该大于等于1')
elif j == 1:
cv = chi2.isf(alpha * 0.5, j)
else:
cv = chi2.isf(alpha * 0.5, j - 1) if chis > cv:
re = 1 # 表示拒绝原假设
else:
re = 0 # 表示接受原假设 return chis, p_value, cv, j-1, re
(3)测试
data1 = np.array([[39, 21], ])
alpha1 = 0.05
chis1, p_value1, cv1, dof, re1 = chi2_fitting(data1, alpha1)
(4)输出
chis1 = 5.4000000000000004
p_value1 = 0.020136751550346329
cv1 = 5.0238861873148917
dof = 1
re1 = 1
显然chis1(卡方值)是大于cv1(临界值)的,因此拒绝原假设,认为对于文理分科,学生们的态度是有显著的差异的。与前面结果一直。这里可以输入多维度数组,而不是简单的一维数组,因为在国内没有找到合适的多维度多类别数组的例子,想结合例子来讲解,更便于理解,既然没有例子也就不使用python进行这个知识点的展示了,望理解。但是此函数中sp给多维度多类别的数组输入提供了方法,原理和scipy.stats.chisquare中的axis参数一样,请大家查阅官方文档。
2.5 卡方拟合性检验和独立性检验之间的关系
从表面上看,拟合性检验和独立性检验不论在列联表的形式上,还是在计算卡方的公式上都是相同的,所以经常被笼统地称为卡方检验。但是两者还是存在差异的。
首先,两种检验抽取样本的方法不同。如果抽样是在各类别中分别进行,依照各类别分别计算其比例,属于拟合优度检验。如果抽样时并未事先分类,抽样后根据研究内容,把入选单位按两类变量进行分类,形成列联表,则是独立性检验。
其次,两种检验假设的内容有所差异。拟合优度检验的原假设通常是假设各类别总体比例等于某个期望概率,而独立性检验中原假设则假设两个变量之间独立。
最后,期望频数的计算不同。拟合优度检验是利用原假设中的期望概率,用观察频数乘以期望概率,直接得到期望频数。独立性检验中两个水平的联合概率是两个单独概率的乘积。
3 文献
卡方检验 - 维基百科,自由的百科全书
https://zh.wikipedia.org/wiki/%E5%8D%A1%E6%96%B9%E6%A3%80%E9%AA%8C
卡方分布 - MBA智库百科
http://wiki.mbalib.com/wiki/%E5%8D%A1%E6%96%B9%E5%88%86%E5%B8%83
用Python进行卡方分析 - 简书
https://www.jianshu.com/p/c307d04eee56
拟合优度检验_百度百科
https://baike.baidu.com/item/%E6%8B%9F%E5%90%88%E4%BC%98%E5%BA%A6%E6%A3%80%E9%AA%8C
列联表分析2——独立性检验(卡方检验)_关文忠工作室_新浪博客
http://blog.sina.com.cn/s/blog_4d69c7430101ndub.html
卡方分布分析与应用 - 云+社区 - 腾讯云
https://cloud.tencent.com/developer/article/1010577
卡方检验 | Ren’s Cabinet of Curiosities
http://www.ryanzhang.info/tag/%E5%8D%A1%E6%96%B9%E6%A3%80%E9%AA%8C/
scipy.stats.chi2 — SciPy v1.1.0 Reference Guide(卡方分布)
https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.chi2.html#scipy.stats.chi2
scipy.stats.chi2_contingency — SciPy v0.15.1 Reference Guide(卡方独立性检验)
https://docs.scipy.org/doc/scipy-0.15.1/reference/generated/scipy.stats.chi2_contingency.html
scipy.stats.chisquare — SciPy v1.1.0 Reference Guide(卡方拟合性检验)
https://docs.scipy.org/doc/scipy/reference/generated/scipy.sta

转载说明
1、本人博客纯属技术积累和分享,欢迎大家评论和交流以求共同进步。
2、在无明确说明下,博客可以转载以供个人学习和交流,但是要附上出处。
3、如果原创博客使用涉及商业/公司行为请邮件(1547364995@qq.com)告知,一般情况均会及时回复同意。
4、如果个人博客中涉及他人文章我会尽力注明出处,但受限于能力并不能保证所有引用之处均能够注明出处,如有冒犯,请您及时邮件告知以便修改,并于此提前向您道歉。
5、转载过程中如有涉及他人作品请您与作者联系。
6、所有文章(不限于原创)仅为个人见解,个人只能尽量保证正确,如有错误您需要自负责任,并请您留下评论提出错误之处以便及时更正,惠泽他人,谢谢
卡方分布、卡方独立性检验和拟合性检验理论及其python实现的更多相关文章
- 方差分析、T检验、卡方分析如何区分?
差异研究的目的在于比较两组数据或多组数据之间的差异,通常包括以下几类分析方法,分别是方差分析.T检验和卡方检验. 三个方法的区别 其实核心的区别在于:数据类型不一样.如果是定类和定类,此时应该使用卡方 ...
- t分布, 卡方x分布,F分布
T分布:温良宽厚 本文由“医学统计分析精粹”小编“Hiu”原创完成,文章采用知识共享Attribution-NonCommercial-NoDerivatives 4.0国际许可协议(http://c ...
- 基于卡方的独立性检验原理及R语言实现
在读到<R语言实战>(第二版)P143页有关卡方独立性检验所记 假设检验 假设检验(Test of Hypothesis)又称为显著性检验(Test of Ststistical Sign ...
- spark机器学习从0到1特征选择-卡方选择器(十五)
一.公式 卡方检验的基本公式,也就是χ2的计算公式,即观察值和理论值之间的偏差 卡方检验公式 其中:A 为观察值,E为理论值,k为观察值的个数,最后一个式子实际上就是具体计算的方法了 n 为总 ...
- 数据分箱:等频分箱,等距分箱,卡方分箱,计算WOE、IV
转载:https://zhuanlan.zhihu.com/p/38440477 转载:https://blog.csdn.net/starzhou/article/details/78930490 ...
- 互信息 & 卡方 - 文本挖掘
在做文本挖掘,特别是有监督的学习时,常常需要从文本中提取特征,提取出对学习有价值的分类,而不是把所有的词都用上,因此一些词对分类的作用不大,比如“的.是.在.了”等停用词.这里介绍两种常用的特征选择方 ...
- 图像检索:RGBHistogram+欧几里得距离|卡方距离
RGBHistogram: 分别计算把彩色图像的三个通道R.G.B的一维直方图,然后把这三个通道的颜色直方图结合起来,就是颜色的描写叙述子RGBHistogram. 以下给出计算RGBHistogra ...
- Spark MLlib编程API入门系列之特征选择之卡方特征选择(ChiSqSelector)
不多说,直接上干货! 特征选择里,常见的有:VectorSlicer(向量选择) RFormula(R模型公式) ChiSqSelector(卡方特征选择). ChiSqSelector用于使用卡方检 ...
- 特征选择--->卡方选择器
特征选择(Feature Selection)指的是在特征向量中选择出那些“优秀”的特征,组成新的.更“精简”的特征向量的过程.它在高维数据分析中十分常用,可以剔除掉“冗余”和“无关”的特征,提升学习 ...
随机推荐
- AngularJS 中ng-model通过$watch动态取值
这个例子的意思是,当xxxx的长度不超过6时,xxxx和yyyy两个input的model是无关的,但当xxxx超过6,则yyyy会跟随其值而变化. 另一种做法是在input的ng-model后面添加 ...
- 神马是代码简单的cmd模式,这就是!
小狼正在研究 “怎么查找连在一起的同色方块?”算法问题 ,突然感觉我是不是需要一种开发模式,不然感觉自己的代码好乱的. 可能是研究算法吧,导致小狼的思路特别清晰,加上也用了差不多1年的nodejs.s ...
- Linux按键设备驱动一
① request_irq函数用于注册中断 int request_irq(unsigned int irq, void(*handler)(int, void*, struct pt_reg*), ...
- shell特殊字符汇总【转】
Linux下无论如何都是要用到shell命令的,在Shell的实际使用中,有编程经验的很容易上手,但稍微有难度的是shell里面的那些个符号,各种特殊的符号在我们编写Shell脚本的时候如果能够用的好 ...
- Linux下Makefile的automake生成全攻略--转
http://www.yesky.com/120/1865620.shtml 作为Linux下的程序开发人员,大家一定都遇到过Makefile,用make命令来编译自己写的程序确实是很方便.一般情况下 ...
- nyoj 269——VF——————【dp】
VF 时间限制:1000 ms | 内存限制:65535 KB 难度:2 描述 Vasya is the beginning mathematician. He decided to make ...
- 【转】常用的邮箱服务器(SMTP、POP3)地址、端口
gmail(google.com)POP3服务器地址:pop.gmail.com(SSL启用 端口:995)SMTP服务器地址:smtp.gmail.com(SSL启用 端口:587) 21cn.co ...
- Java Bean Validation(参数校验) 最佳实践
转载来自:http://www.cnblogs.com 参数校验是我们程序开发中必不可少的过程.用户在前端页面上填写表单时,前端js程序会校验参数的合法性,当数据到了后端,为了防止恶意操作,保持程序的 ...
- 深入理解JavaScript系列(32):设计模式之观察者模式
介绍 观察者模式又叫发布订阅模式(Publish/Subscribe),它定义了一种一对多的关系,让多个观察者对象同时监听某一个主题对象,这个主题对象的状态发生变化时就会通知所有的观察者对象,使得它们 ...
- 在 Visual Studio 中调试 XAML 设计时异常
在 Visual Studio 中进行 WPF, UWP, Silverlight 开发时,经常会遇到 XAML 设计器由于遭遇异常而无法正常显示设计器视图的情况.很多时候由于最终生成的项目在运行时并 ...