(数据科学学习手札14)Mean-Shift聚类法简单介绍及Python实现
不管之前介绍的K-means还是K-medoids聚类,都得事先确定聚类簇的个数,而且肘部法则也并不是万能的,总会遇到难以抉择的情况,而本篇将要介绍的Mean-Shift聚类法就可以自动确定k的个数,下面简要介绍一下其算法流程:
1.随机确定样本空间内一个半径确定的高维球及其球心;
2.求该高维球内质心,并将高维球的球心移动至该质心处;
3.重复2,直到高维球内的密度随着继续的球心滑动变化低于设定的阈值,算法结束
具体的原理可以参考下面的地址,笔者读完觉得说的比较明了易懂:
http://blog.csdn.net/google19890102/article/details/51030884
而在Python中,机器学习包sklearn中封装有该算法,下面用一个简单的示例来演示如何在Python中使用Mean-Shift聚类:
一、低维
from sklearn.cluster import MeanShift
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
from matplotlib.pyplot import style
import numpy as np
'''设置绘图风格'''
style.use('ggplot')
'''生成演示用样本数据'''
data1 = np.random.normal(0,0.3,(1000,2))
data2 = np.random.normal(1,0.2,(1000,2))
data3 = np.random.normal(2,0.3,(1000,2)) data = np.concatenate((data1,data2,data3)) # data_tsne = TSNE(learning_rate=100).fit_transform(data)
'''搭建Mean-Shift聚类器'''
clf=MeanShift()
'''对样本数据进行聚类'''
predicted=clf.fit_predict(data)
colors = [['red','green','blue','grey'][i] for i in predicted]
'''绘制聚类图'''
plt.scatter(data[:,0],data[:,1],c=colors,s=10)
plt.title('Mean Shift')

二、高维
from sklearn.cluster import MeanShift
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
from matplotlib.pyplot import style
import numpy as np
'''设置绘图风格'''
style.use('ggplot')
'''生成演示用样本数据'''
data1 = np.random.normal(0,0.3,(1000,6))
data2 = np.random.normal(1,0.2,(1000,6))
data3 = np.random.normal(2,0.3,(1000,6)) data = np.concatenate((data1,data2,data3)) data_tsne = TSNE(learning_rate=100).fit_transform(data)
'''搭建Mean-Shift聚类器'''
clf=MeanShift()
'''对样本数据进行聚类'''
predicted=clf.fit_predict(data)
colors = [['red','green','blue','grey'][i] for i in predicted]
'''绘制聚类图'''
plt.scatter(data_tsne[:,0],data_tsne[:,1],c=colors,s=10)
plt.title('Mean Shift')
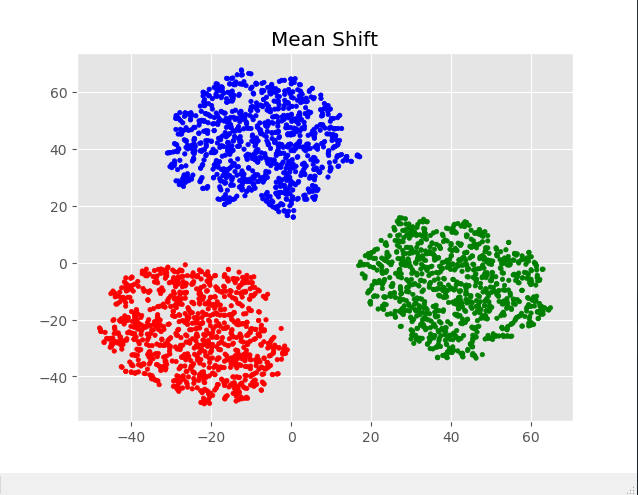
三、实际生活中的复杂数据
我们以之前一篇关于K-means聚类的实战中使用到的重庆美团商户数据为例,进行Mean-Shift聚类:
import matplotlib.pyplot as plt
from sklearn.cluster import MeanShift
from sklearn.manifold import TSNE
import pandas as pd
import numpy as np
from matplotlib.pyplot import style style.use('ggplot') data = pd.read_excel(r'C:\Users\windows\Desktop\重庆美团商家信息.xlsx')
input = pd.DataFrame({'score':data['商家评分'][data['数据所属期'] == data.iloc[0,0]],
'comment':data['商家评论数'][data['数据所属期'] == data.iloc[0,0]],
'sales':data['本月销售额'][data['数据所属期'] == data.iloc[0,0]]}) '''去缺省值'''
input = input.dropna() input_tsne = TSNE(learning_rate=100).fit_transform(input) '''创造色彩列表'''
with open(r'C:\Users\windows\Desktop\colors.txt','r') as cc:
col = cc.readlines()
col = [col[i][:7] for i in range(len(col)) if col[i][0] == '#'] '''进行Mean-Shift聚类'''
clf = MeanShift()
cl = clf.fit_predict(input) '''绘制聚类结果'''
np.random.shuffle(col)
plt.scatter(input_tsne[:,0],input_tsne[:,1],c=[col[i] for i in cl],s=8)
plt.title('Mean-Shift Cluster of {}'.format(str(len(set(cl)))))

可见在实际工作中的复杂数据用Mean-Shift来聚类因为无法控制k个值,可能会产生过多的类而导致聚类失去意义,但Mean-Shift在图像分割上用处很大。
以上便是本篇对Mean-Shift简单的介绍,如有错误望指出。
(数据科学学习手札14)Mean-Shift聚类法简单介绍及Python实现的更多相关文章
- (数据科学学习手札11)K-means聚类法的原理简介&Python与R实现
kmeans法(K均值法)是麦奎因提出的,这种算法的基本思想是将每一个样本分配给最靠近中心(均值)的类中,具体的算法至少包括以下三个步骤: 1.将所有的样品分成k个初始类: 2.通过欧氏距离将某个样品 ...
- (数据科学学习手札08)系统聚类法的Python源码实现(与Python,R自带方法进行比较)
聚类分析是数据挖掘方法中应用非常广泛的一项,而聚类分析根据其大体方法的不同又分为系统聚类和快速聚类,其中系统聚类的优点是可以很直观的得到聚类数不同时具体类中包括了哪些样本,而Python和R中都有直接 ...
- (数据科学学习手札16)K-modes聚类法的简介&Python与R的实现
我们之前经常提起的K-means算法虽然比较经典,但其有不少的局限,为了改变K-means对异常值的敏感情况,我们介绍了K-medoids算法,而为了解决K-means只能处理数值型数据的情况,本篇便 ...
- (数据科学学习手札10)系统聚类实战(基于R)
上一篇我们较为系统地介绍了Python与R在系统聚类上的方法和不同,明白人都能看出来用R进行系统聚类比Python要方便不少,但是光介绍方法是没用的,要经过实战来强化学习的过程,本文就基于R对2016 ...
- (数据科学学习手札13)K-medoids聚类算法原理简介&Python与R的实现
前几篇我们较为详细地介绍了K-means聚类法的实现方法和具体实战,这种方法虽然快速高效,是大规模数据聚类分析中首选的方法,但是它也有一些短板,比如在数据集中有脏数据时,由于其对每一个类的准则函数为平 ...
- (数据科学学习手札12)K-means聚类实战(基于R)
上一篇我们详细介绍了普通的K-means聚类法在Python和R中各自的实现方法,本篇便以实际工作中遇到的数据集为例进行实战说明. 数据说明: 本次实战样本数据集来自浪潮集团提供的美团的商家信息,因涉 ...
- (数据科学学习手札09)系统聚类算法Python与R的比较
上一篇笔者以自己编写代码的方式实现了重心法下的系统聚类(又称层次聚类)算法,通过与Scipy和R中各自自带的系统聚类方法进行比较,显然这些权威的快捷方法更为高效,那么本篇就系统地介绍一下Python与 ...
- (数据科学学习手札26)随机森林分类器原理详解&Python与R实现
一.简介 作为集成学习中非常著名的方法,随机森林被誉为“代表集成学习技术水平的方法”,由于其简单.容易实现.计算开销小,使得它在现实任务中得到广泛使用,因为其来源于决策树和bagging,决策树我在前 ...
- (数据科学学习手札29)KNN分类的原理详解&Python与R实现
一.简介 KNN(k-nearst neighbors,KNN)作为机器学习算法中的一种非常基本的算法,也正是因为其原理简单,被广泛应用于电影/音乐推荐等方面,即有些时候我们很难去建立确切的模型来描述 ...
随机推荐
- Python中深浅拷贝 垃圾回收与 super继承(六)
1 python拷贝 深拷贝,浅拷贝 与引用三者的区别 import copy a = [1, 2, 3, 4, ['a', 'b']] #原始对象 b = a #赋值,传对象的引用 c = copy ...
- Laravel SMS 短信发送包
Laravel Sms Laravel 贴合实际需求同时满足多种通道的短信发送组件 我们基于业务需求在 overtrue/easy-sms 基础进行扩展开发,主要实现如下目标: 支持短信验证码直接在 ...
- WAKE-WIN10-SOFT-python配置
1,anaconda下载,安装 1,1 官网:https://www.continuum.io/downloads 下载:https://repo.continuum.io/archive/ win1 ...
- Sql Server中一次更新多列数据
UPATE yourTableName SET column1 = xx, column2 = yy , column3 = zz WHERE yourCondition 举个例子,比如有这样一张表: ...
- 异常:Caused by: java.lang.NoSuchMethodError: javax.persistence.OneToMany.orphanRemoval()Z
Spring3.0 + Hibernate3.5:启动服务器报:Caused by: java.lang.NoSuchMethodError: javax.persistence.OneToMany. ...
- Python语言程序设计基础(6)—— 组合数据类型
tuple 元组(创建后不能修改) tuple = "cat","dog","tiger","human" print( ...
- ACM-ICPC 2018 徐州赛区网络预赛 A.Hard to prepare 【规律递推】
任意门:https://nanti.jisuanke.com/t/31453 A.Hard to prepare After Incident, a feast is usually held in ...
- 2018.11.22 mac中"允许所有安装来源"的命令 & Mac窗口标题显示文件的路径
当Mac遇到软件无法安装或者此文件已经损坏之类的时候 原因是软件为破解版,地址来源已改变,被系统拦截了,解决办法就是直接在终端中输入"sudo spctl --master-disable ...
- 用jquery写的json省市县三级联动下拉
<form action="#" name="myform"> <label>省</label><select nam ...
- mybatis学习记录五——动态sql
8 动态sql 8.1 什么是动态sql mybatis核心 对sql语句进行灵活操作,通过表达式进行判断,对sql进行灵活拼接.组装. 8.2 需求 用户信息综合查询列表 ...