字符集与Mysql字符集处理(一)
一、字符集总结
其实大多数的知识在这篇文章里已经讲得非常清楚了。这里只是讲一下自己的感悟。
1. UTF-8虽然是以UTF(unicode transfermation format)开头的,但是他并不是真正意义上的Unicode。他是在UCS上的再编码。而且,这是一个变长的编码方式。
2. 根据这篇文章的说法,在ISO制定UCS(Universal Character Set)的同时,另一个由厂商联合组织也在着手制定这样的编码,称为Unicode,后来两家联手制定统一的编码,但各自发布各自的标准文档,所以UCS编码和Unicode码是相同的。
3. 当我们在Linux下采用“locale –a”命令查看所有可用字符集时,出现的描述其实就是都是属于Native ANSI,因为他们都是标准ANSI的超集。
4. 当我们在Windows下将文件以UTF-8的方式进行存储时,Windows会将一个叫做UTF-8 Signature的三个字节写在文件的最开头,这样就可以表示,这个文件的编码方式就是UTF-8,而不是其他字符集。由于UTF-8是变长编码,所以这样就便于我们去区分如下的一种情况,即当文件中只有标准ANSI字符集中规定的字符时,我们还认为这是一个UTF-8编码,这样以后如果再出现CJK(Chinese,Japan,Korea)里面的汉字时,就可以顺利解码了。同样,也是因为它,当我们在windows下另存为UTF-8格式时,直接FTP到Linux下进行编译,即使将gcc的-finput-charset=utf-8设定,也会出现编译错误(因为有不认识的字符了,具体表现如此)。
5. 通常来说,我们所存储的文件(这里主要是指配置文件,代码文件)需要使用UTF-8编码。一方面是因为gcc的默认finput-charset选项是utf-8,另外一方面utf-8编码支持所有的字符(中文,英文)。 *.Java文件就是这样存储的。
6. 注意到一个专有名词叫做“C Locale”,他是一般C语言程序进入main之后的默认字符集(可以通过setlocale(LC_ALL, NULL)进行查看)。这个字符集就是ANSI字符集,因为所有的C程序都支持这个字符集,且有了这个字符集就可以运行程序了,所以就给了一个名字,叫做“C Locale”。
二、关于gcc对字符集的支持
这里所述的内容,主要是参考了这篇文章和man gcc。这里做一个总结。在整个编译过程中有如下几个关键的字符集。
- 代码文件的字符集A
- gcc内部处理的字符集B(UTF-8)
- gcc输出的二进制文件的字符集C(默认是UTF-8,可以使用-fexec-charset选项进行指定)
具体来说,当我们运用gcc命令将代码文件进行编译,它就直接认为代码文件的字符集是finput-charset选项中所指定的字符集(默认是utf-8),也就是说他也许根本就不知道你的字符集是字符集A。他根据finput-charset选项中的字符集向自己的内部所使用的字符集B进行转码。经过编译之后,就再次将二进制输出从内部字符集B转为字符集C。图示为,
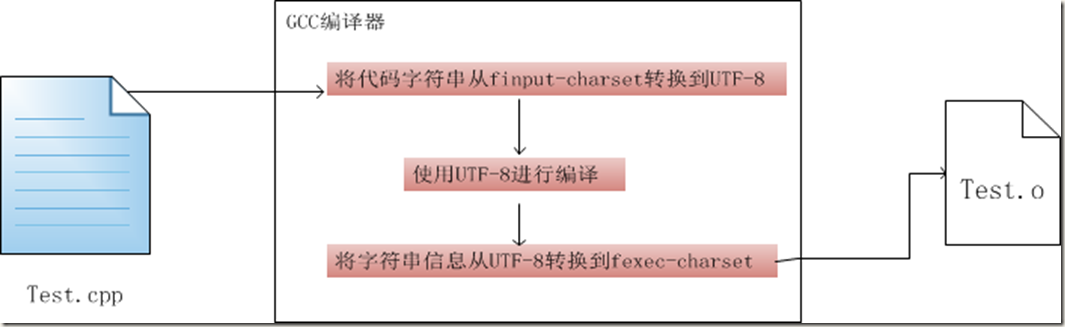
学过编译原理的同学应该会知道,在二进制文件中最多的应该是指令,那么什么是需要使用字符集C来表示的?当然是我们硬编码的字符串。直接嫁接这里的例子,如果有如下代码,
#include <stdio.h> int main(void)
{
printf("你好\n");
return 0;
}
且我们假设,源文件是UTF-8编码,我们也使用默认的gcc –fexec-charset。那么这个“你好”就需要使用字符集C进行编码,通过命令查看
$ od -tc nihao.c
0000000 # i n c l u d e < s t d i o .
0000020 h > \n \n i n t m a i n ( v o i
0000040 d ) \n { \n \t p r i n t f ( " 344 275
0000060 240 345 245 275 \ n " ) ; \n \t r e t u r
0000100 n 0 ; \n } \n
0000107
其中八进制的344 375 240(十六进制e4 bd a0)就是“你”的UTF-8编码,八进制的345 245 275(十六进制e5 a5 bd)就是“好”。
由此可以得到的结论是,尽量使用UTF-8来编写我们的源程序,这样就可以不用显式设置-finput-charset和-fexec-charset了,便于移植。
三、程序运行与字符集
1. printf(“%s”)到底做了什么?参考文档。
当我们在程序里面使用了printf(“%s”),他其实就是把字符串首地址到第一个“\0”处的字节write到当前终端的设备文件。如果当前终端的驱动程序能够识别UTF-8编码就能打印出汉字,如果当前终端的驱动程序不能识别UTF-8编码(比如一般的字符终端)就打印不出汉字。也就是说,像这种程序,识别汉字的工作既不是由C编译器做的也不是由libc做的,C编译器原封不动地把源文件中的UTF-8编码(假设这个源文件就是用UTF-8编码且没有另外指定-finput-charset)复制到目标文件中,libc只是当作以0结尾的字符串原封不动地write给内核,识别汉字的工作是由终端的驱动程序做的。
我一开始以为终端会帮我们做转码,因为我们设置了“LANG”这个环境变量(他会转而设置LC_ALL),所以做了如下实验。
#include <iostream>
#include <locale.h>
using namespace std; int main(int argc, char **argv)
{
string s = "你好";
cout << s << endl; char buff[10] = "你好";
for (int i = 0; i < 10; i++)
{
printf("%2X ", buff[i]);
}
cout << endl; return 0;
}
现在我保证输出的二进制是UTF-8编码的。实验如下,
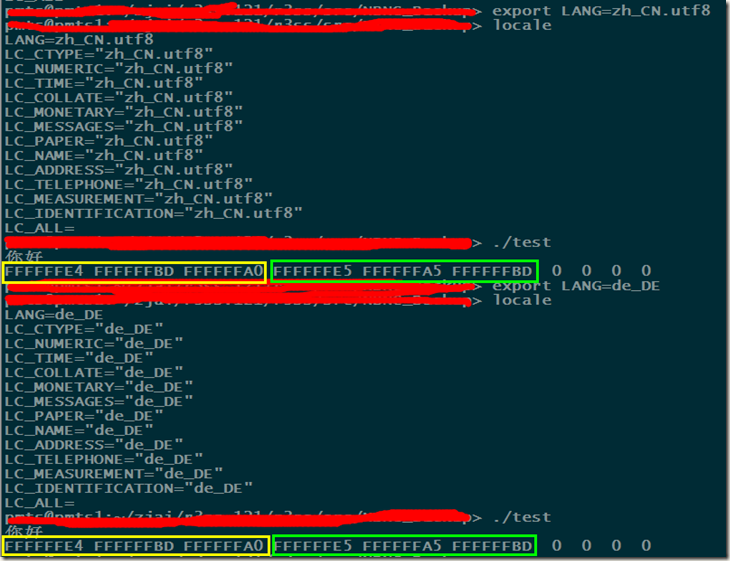
可以看到,输出和当前终端的字符集无关。因为从程序里面输出的字节流就是“你”和“好”的UTF-8编码,所以还是被设备驱动程序给正确解析了。
2. setlocale()到底用来做什么?
在做上面的实验的时候,其实我还对“终端字符集对输入和输出会进行转码”而有所期待。所以在代码里,我还特意尝试了个中setlocale(LC_ALL, “xxxx”)的调用,尝试看结果。但是结果总是和上面所说的一样,总是没有出现乱码输出。
经过一段分析和朋友的点拨,终于将setlocale与wcstombs(宽字符串转换到多字节串)、mbstowcs(多字节串转换到宽字符串)结合起来了。
要讲清楚这个事情,必须先从宽字符串(wide-character string)与多字节串(multibyte string)讲起。为什么要引入宽字符串,这里有比较好的讲法。摘抄如下。
“最根本的原因是,ANSI下的字符串都是以’\0’来标识字符串尾的(Unicod以“\0\0”束),许多字符串函数的正确操作均是以此为基础进行。而我们知道,在宽字符的情况下,一个字符在内存中要占据一个字的空间,这就会使操作ANSI字符的字符串函数无法正确操作。以”Hello”字符串为例,在宽字符下,它的五个字符是:
0x0048 0x0065 0x006c 0x006c 0x006f
在内存中,实际的排列是:
48 00 65 00 6c 00 6c 00 6f 00 (这里应该是源代码是UTF-8编码的,所以高位是00——Aicro注)
于是,ANSI字符串函数,如strlen,在碰到第一个48后的00时,就会认为字符串到尾了,用strlen对宽字符串求长度的结果就永远会是1! ”
其实这里所说的宽字符串,就是我们通常所说的Unicode串,也就是UCS-2。
mbstowcs就是将,反之是wcstombs。
- mbstowcs的具体工作流程
我们先通过在线转换工具了解到“你好”这两个汉字的宽字符(Unicode)表示是\u4f60\u597d。
下面的程序使用gcc编译的,使用各种默认选项。
#include <locale.h>
#include <iostream>
#include <stdlib.h>
#include "string.h" int main()
{
char* source = "你好"; setlocale(LC_ALL, "zh_CN.utf8"); // 获取长度
size_t wcs_size = mbstowcs(NULL, source, 0); // 申请内存并初始化
wchar_t* dest = new wchar_t[wcs_size + 1];
wmemset(dest, L'\0', wcs_size + 1); // 多字节串转换到宽字符串,注意,第三个参数是byte数
mbstowcs(dest, source, strlen(source) * sizeof(char)); // 验证一下
for (int i = 0; i < wcs_size; i++)
{
printf("%2X ", dest[i]);
} printf("\n"); return 0;
}
输出结果就是4F60 597D。可见,mbstowcs的作用过程是
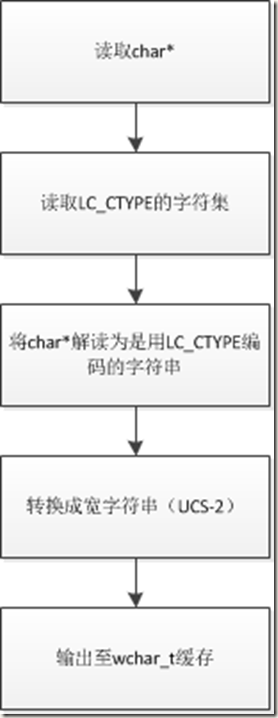
重点是,mbstowcs把LC_CTYPE认作是source(多字符字串)的编码。
- wcstombs的具体工作流程
我们先通过在线转换工具了解到“你好”这两个汉字的gbk编码是C4 E3 BA C3 。
实验程序
#include <locale.h>
#include <iostream>
#include <stdlib.h>
#include "string.h" int main()
{
char* source = "你好"; setlocale(LC_ALL, "zh_CN.utf8"); // 获取长度
size_t wcs_size = mbstowcs(NULL, source, 0); // 申请内存并初始化
wchar_t* dest = new wchar_t[wcs_size + 1];
wmemset(dest, L'\0', wcs_size + 1); // 多字节串转换到宽字符串,注意,第三个参数是byte数
mbstowcs(dest, source, strlen(source) * sizeof(char)); // 转回gbk编码
setlocale(LC_ALL, "zh_CN.gbk"); // 获取长度
size_t mbs_size = wcstombs(NULL, dest, 0); // 申请内存并初始化
char* buf_mbs = new char [mbs_size + 1];
memset(buf_mbs, '\0', mbs_size + 1); // 宽字符串转换到多字节串,注意,第三个参数是byte数
wcstombs(buf_mbs, dest, wcs_size * sizeof(wchar_t)); // 验证一下
for (int i = 0; i < mbs_size; i++)
{
printf("%2X ", buf_mbs[i]);
} printf("\n"); return 0;
}
输出结果与预期一样。这说明了wcstombs的流程。
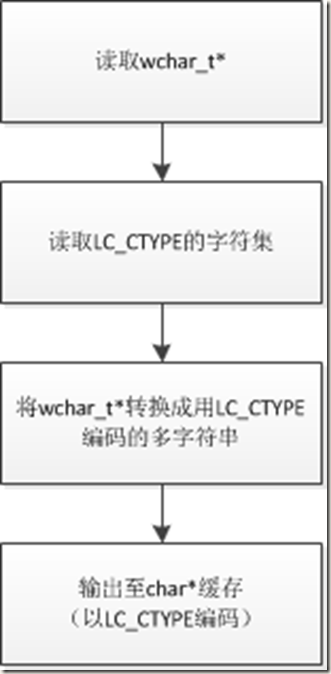
重点是,wcstombs把LC_CTYPE认作是destination(多字符字串)的编码。
总结:setlocale需要与wcstombs域mbstowcs联合使用。根据这篇文章的说法,程序在做内部计算时通常以宽字符编码,如果要存盘或者输出给别的程序,或者通过网络发给别的程序,则采用多字节编码。这就让我想到了原来读第四版《windows via c/c++》,好像第二章就讲到过这个问题,一直没有实践过,所以就忘记了。
字符集与Mysql字符集处理(一)的更多相关文章
- 字符集与Mysql字符集处理(二)
接着上篇文章继续讲字符集的故事.这一篇文章主要讲MYSQL的各个字符集设置,关于基础理论部分,参考于这里. 1. MYSQL的系统变量 – character_set_server:默认的内部操作 ...
- 9.Mysql字符集
9.字符集9.1 字符集概述 字符集就是一套文字符号及其编码.比较规则的集合. ASCII(American Standard Code for Information Interchange)字符集 ...
- 如何修改MySQL字符集
首先,MySQL的字符集问题主要是两个概念,一个是Character Sets,一个是Collations,前者是字符内容及编码,后者是对前者进行比较操作的一些规则.这两个参数集可以在数据库实例.单个 ...
- Mysql字符集设置
转 基本概念 • 字符(Character)是指人类语言中最小的表义符号.例如’A'.’B'等:• 给定一系列字符,对每个字符赋予一个数值,用数值来代表对应的字符,这一数值就是字符的编码(Encodi ...
- MySQL字符集
字符集的选择 1.如果数据库只需要支持中文,数据量很大,性能要求也很高,应该选择双字节定长编码的中文字符集(如GBK).因为相对于UTF-8而言,GBK"较小",每个汉字只占2个字 ...
- ubuntu系统修改mysql字符集
1.进入mysql,查看默认字符集: mysql>show variables like 'char%'; 2.退出mysql; 3.输入命令:sudo gedit /etc/mysql/con ...
- mysql5.5字符集设置的一点变化(对于中文乱码问题,需要设置mysql字符集)
工作中因为字符集问题没少头疼,还犯过一次错误,还好拯救及时,没有发生重大事故,唉,弄清楚点还是非常有必要的: 例如我的工作环境为CTR+redhat5+mysql5.5 在导入sql语句的时候必须要注 ...
- Mysql字符集知识总结
字符集&字符编码方式 字符集(Character set)是多个字符的集合,字符集种类较多,每个字符集包含的字符个数不同,这里的字符可以是英文字符,汉字字符,或者其他国家语言字符. 常见字符集 ...
- MySQL字符集的修改和查看
1.关于MySQL字符集 MySQL的字符集支持(Character Set Support)有两个方面: 字符集(Character set)和排序方式(Collation). MySQL对于字符集 ...
随机推荐
- paip.函数方法回调机制跟java php python c++的实现
paip.函数方法回调机制跟java php python c++的实现 作者Attilax 艾龙, EMAIL:1466519819@qq.com 来源:attilax的专栏 地址:http:// ...
- Leetcode 165 Compare Version Numbers
题意:比较版本号的大小 有点变态,容易犯错 本质是字符串的比较,请注意他的版本号的小数点不知1个,有的会出现01.0.01这样的变态版本号 class Solution { public: int c ...
- 深入学习系列--Data Structure--02字符串
字符串可以说是我们实际工作中使用最多的数据类型了,常见的字符串操作包括链接.取子串.格式化等.这部分内容总体来说比较容易理解,最难的部分要数字符串的模式匹配方法了,尤其是KMP算法,需要通过实践加以记 ...
- Python:IOError: image file is truncated 的解决办法
代码如下: #coding:utf-8 from PIL import Image import pytesseract def test(): im = Image.open(r"pic. ...
- Cocos2dx.3x入门三部曲-软件环境配置(一)
一.环境: Win7 32位 二.必备软件: l Java JDK 下载地址:http://www.oracle.com/technetwork/java/javase/downloads/inde ...
- 【Android开发坑系列】之Fragment
这个东西有顾名思义是碎片,和之前的Activity对应. 坑1:一般情况都会想当然的以为进程被杀掉之后,Fragment也会被回收 其实,Fragment有自己的生命周期,有自己的管理器(Fragme ...
- C++实现单例模式
昨天面试的时候,面试官让我用C++或Java实现一个单例模式. 因为设计模式是在12年的时候学习过这门课,而且当时觉得这门课很有意思,所以就把课本读了几遍,所以印象比较深刻,但是因为实际编程中很少注意 ...
- Scala 深入浅出实战经典 第62讲:Scala中上下文界定内幕中的隐式参数实战详解
王家林亲授<DT大数据梦工厂>大数据实战视频 Scala 深入浅出实战经典(1-87讲)完整视频.PPT.代码下载: 百度云盘:http://pan.baidu.com/s/1c0noOt ...
- mysql自动化安装
MySQL安装一般使用RPM或者源码安装的方式.RPM安装的优点是快速,方便.缺点是不能自定义安装目录.如果需要调整数据文件和日志文件的存放位置,还需要进行一些手动调整.源码安装的优点是可以自定义安装 ...
- Storage Systems topics and related papers
In this post, I will distill my own ideas and my own views into a structure for a storage system cou ...