(转)SQL Server 中的事务和锁(三)-Range S-U,X-X 以及死锁
在上一篇中忘记了一个细节。Range T-K 到底代表了什么?Range T-K Lock 代表了在 SERIALIZABLE 隔离级别中,为了保护范围内的数据不被并发的事务影响而使用的一类锁模式(避免幻读)。它由两个部分构成:
第一个部分代表了他锁定了一个索引范围,在这个范围内,所有索引使用 T 锁进行锁定;
第二个部分是而这个范围内已经命中的Key,这些 Key 将使用 K 锁进行锁定。
合并在一起我们说在这个范围内,索引范围和特定的row的锁定模式为 Range T-K。
举上一篇的一个例子吧:
SELECT [data] FROM [MyTable] WHERE [index_column]>=20 AND [index_column]<=40
的锁的使用情况是:
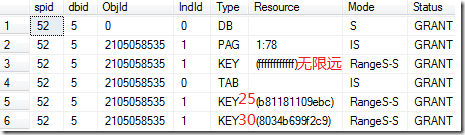
实际上,上述语句产生的锁有两个部分,第一个是 Range S 锁,范围是 20-40 的索引范围,第二是 Key 上使用的 S 锁,在图中可以看到有三个 Key 被命中了,分别是“无限远”,“25”对应的索引以及“30”对应的索引。其 Mode 为 Range S-S,其 Type 为 KEY,也就是,他们的范围锁为 Range S,Key 锁为 S 锁。
更新和插入操作涉及的锁
涉及的锁主要是两种,一种是 Range S-U 锁,另一种是 Range X-X 锁。
Range S-U,这个选定索引范围会获得 S 锁而命中的 Key 使用 U 锁锁定,以便将来转换为 X 锁。而在更新时,则彻底成为 X 锁,这个范围内的锁模式也就成了 Range X-X。由于更新的数据列不同(有可能是索引列,有可能不是),使用的索引也不同(聚集,非聚集,唯一,等),因此其情况就不容易像 Range S-S 锁那么容易得出规律了。总的来说有几种情况还是一致的,这里就不再逐个实验了(这里强烈推荐阅读 SQL Server 2008 Internals 这本书关于锁的章节,讲述的很清楚):
首先,在相等判断(例如“=”),且索引为唯一索引的情况下。如果该索引命中,不会有 Range T-K 锁锁定记录范围,而相应的记录直接获得 U 锁或者 X 锁;
其次,在相等判断,不论索引是否为唯一索引,如果该索引没有命中记录,则 Range T-K 锁锁定 “下一个”记录。(关于“下一个”的解释请参见上一篇);
第三,在范围条件(>、<、BETWEEN),不论索引是否唯一,如果该索引命中,不但该范围会获得 Range T-K 锁,而该范围的“下一个”记录也会获得 Range T-K 锁。
为什么 Serializable 隔离级别更容易死锁
我们从第一篇的图可以看到,SERIALIZABLE 级别能够保证最严格的数据一致性,但是这些保卫的手段只要稍稍变化就可以发展为死锁。事实上,在各种隔离级别中,数据一致性越高,则越容易发生死锁;数据一致性越低,则发生死锁的概率就越小。
在这些隔离级别中,SERIALIZABLE 是最容易死锁的,这得益于 Range T-K 锁使锁定的范围不仅仅限于现有数据,还有未来数据;不仅仅限定现有的若干数据页,而是一个广大的范围。
这其中,最恐怖的问题莫过于“下一个”数据的锁定。这非常容易造成大范围死锁。我们以第一篇的例子来说明:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
SELECT @findCount=COUNT(id) FROM MyTableWHERE [fk_related_id]=@ArgumentIF (@findCount > 0)BEGIN ROLLBACK TRANSACTION RETURN ERROR_CODEENDINSERT INTO MyTable ([fk_related_id],…)VALUES (@Argument,…)COMMIT TRANSACTIONRETURN SUCCESS_CODE |
在这个例子中,表 MyTable 的列 fk_related_id 是一个唯一索引(非聚集),事务隔离级别为 SERIALIZABLE。不同的存储过程执行会传入不同的 @Argument,表面看来,这不会有任何的问题,但是由于“下一个”数据的锁定,在稍高水平的并发上,就出现了大约 80% 的失败情况,这些失败都来源于死锁。我们挑选了其中的一次:
我们试图以每秒钟 15 个的压力在 @Argument 属于 [1, 1000] 的范围内进行存储过程调用。在这个过程中,有一个 @Argument 为 115 的记录首先成功的插入了进去!
| id | fk_related_id | data |
| 1 | 115 | … |
接下来有一个 @Argument 为 74 的记录获得了机会,我们假设它的 Session Id 为 A。它执行了 SELECT 语句:
| id | fk_related_id | data |
| 1 | 115 (A 获得了Range S-S Lock) | … |
接下来有一个 @Argument 为 4 的记录获得了机会,我们假设它的 Session Id 为 B。它执行了 SELECT 语句:
| id | fk_related_id | data |
| 115 (A 、B获得了Range S-S Lock) | … |
接下来,Session A 执行到了 INSERT 语句,那么 Range S-S 锁会试图进行一个转换测试(Range I-N 锁),但这显然是行不通的,因为 Session B 也获得了 Range S-S Lock,因此 Session A 陷入了等待;
而 Session B 也执行到了 INSERT 语句,相同的,它也陷入了等待;这样,Session A 等待 Session B 放弃 Range 锁,Session B 等待 Session A 放弃锁,这是一个死锁了。
而更糟糕的事情是,凡是 @Argument 小于 115 的记录,他都会试图令下一个记录获得新的 Range S-S 锁,从而进入无限的等待中,至少,1-115 号记录死锁,并且最终 114 个需要放弃,1个成功。这就是为什么 SERIALIZABLE 隔离级别不但会发生死锁,而且在某些时候,是大面积死锁。
总之:在 SERIALIZABLE 隔离级别下,只要有类似同一索引为条件先读后写的状况的,在较大并发下发生死锁的概率很高,而且如果碰巧既有的记录索引按照排序规则在非常靠后的位置,则很可能发生大面积死锁。
那么如何解决这个问题呢,呃,降低隔离级别当然是一个方法,例如,如果你能接受幻读,那么 REPEATABLE READ 是一个不错的选择。但是我突然在某篇博客中看到了使用 SELECT WITH UPDLOCK 的方法。事实上,这种东西让死锁更容易了。
例如,一个存储过程 SELECT B,而后 SELECT A;而另外的存储过程先 SELECT A,再 SELECT B,那么由于顺序不同,排他锁仅仅是 Read 的情况就可能发生死锁了。
那么为什么 REPEATABLE READ 会好得多呢?因为 REPEATABLE READ 紧紧锁定现有记录,而不会使用 Range 锁。我们仍然以上述存储过程为例,这样,只有两个被锁定的行数据在同一个页上(因为默认情况下使用页级锁),或者说挨得足够近,才有可能死锁,并且这个死锁仅仅限于这个数据页上的记录而不会影响其他记录,因此死锁的概率大大降低了。
我们实际测试中,在相同的测试条件下,并发提高到 100 的情况下时才有不到 0.1% 的死锁失败几率。当然我们付出了允许幻读的代价。
(转)SQL Server 中的事务和锁(三)-Range S-U,X-X 以及死锁的更多相关文章
- 【转】SQL Server中的事务与锁
SQL Server中的事务与锁 了解事务和锁 事务:保持逻辑数据一致性与可恢复性,必不可少的利器. 锁:多用户访问同一数据库资源时,对访问的先后次序权限管理的一种机制,没有他事务或许将会一塌糊涂 ...
- SQL Server中的事务与锁
了解事务和锁 事务:保持逻辑数据一致性与可恢复性,必不可少的利器. 锁:多用户访问同一数据库资源时,对访问的先后次序权限管理的一种机制,没有他事务或许将会一塌糊涂,不能保证数据的安全正确读写. 死锁: ...
- [转载]SQL Server中的事务与锁
了解事务和锁 事务:保持逻辑数据一致性与可恢复性,必不可少的利器. 锁:多用户访问同一数据库资源时,对访问的先后次序权限管理的一种机制,没有他事务或许将会一塌糊涂,不能保证数据的安全正确读写. 死锁: ...
- T-SQL查询进阶--SQL Server中的事务与锁
为什么需要锁 在任何多用户的数据库中,必须有一套用于数据修改的一致的规则,当两个不同的进程试图同时修改同一份数据时,数据库管理系统(DBMS)负责解决它们之间潜在的冲突.任何关系数据库必须支持事务的A ...
- 十五、SQL Server中的事务与锁
(转载别人的内容,值得Mark) 了解事务和锁 事务:保持逻辑数据一致性与可恢复性,必不可少的利器. 锁:多用户访问同一数据库资源时,对访问的先后次序权限管理的一种机制,没有他事务或许将会一塌糊涂,不 ...
- SQL Server 中的事务和锁(三)-Range S-U,X-X 以及死锁
在上一篇中忘记了一个细节.Range T-K 到底代表了什么?Range T-K Lock 代表了在 SERIALIZABLE 隔离级别中,为了保护范围内的数据不被并发的事务影响而使用的一类锁模式(避 ...
- Microsoft SQL Server中的事务与并发详解
本篇索引: 1.事务 2.锁定和阻塞 3.隔离级别 4.死锁 一.事务 1.1 事务的概念 事务是作为单个工作单元而执行的一系列操作,比如查询和修改数据等. 事务是数据库并发控制的基本单位,一条或者一 ...
- SQL Server 中的事务与事务隔离级别以及如何理解脏读, 未提交读,不可重复读和幻读产生的过程和原因
原本打算写有关 SSIS Package 中的事务控制过程的,但是发现很多基本的概念还是需要有 SQL Server 事务和事务的隔离级别做基础铺垫.所以花了点时间,把 SQL Server 数据库中 ...
- Sql Server中的事务隔离级别
数据库中的事物有ACID(原子性,一致性,隔离性,持久性)四个特性.其中隔离性是用来处理并发执行的事务之间的数据访问控制.SqlServer中提供了几种不同级别的隔离类型. 概念 Read UnCom ...
随机推荐
- 获取和设置tinyMCE 4编辑器的内容
对于tinymce编辑器是无法通过js进行内容的读写的,必须使用编辑器自身的方法才行,下面是一些方法,希望能对用到的朋友有所帮助: 1.如果当前页面只有一个编辑器: 获取内容:tinyMCE.acti ...
- (Beta)Let's-版本发布说明
Let's App(Beta)现已隆重上市 GIT源码请戳此处 版本的新功能 我们在这一版本对于项目的规划目标主要集中在三个方面——预约用户观感,完善功能链条,改善用户体验 界面 首先,在β阶 ...
- p2p软件如何穿透内网进行通信
http://blog.chinaunix.net/uid-22326462-id-1775108.html 首先先介绍一些基本概念: NAT(Network Address Translators) ...
- linux学习笔记一----------文件相关操作
一.目录结构 二.文件管理操作命令(有关文件夹操作,使用Tab键自动补全文件名(如果多个默认第一个)) 1.ls 查看目录信息:ls -l 查看目录详细信息(等价于ll 某些系统不支持) 2.pwd ...
- 简单了解Hibernate核心API
一.SessionFactory 1.它代表的是数据库的连接,其实就是在hibernate.cfg.xml文件中的配置信息 2.可以预定义SQL语句 3.SessionFactory是线程安全的,它维 ...
- hdu 2050 折线分割平面
训练递推用题,第一次做这个题,蒙的,而且对了. #include <stdio.h> int main(void) { int c,a; scanf("%d",& ...
- 登陆后淡入淡出更换rootViewController
- (void)restoreRootViewController:(UIViewController *)rootViewController { typedef void (^Animation) ...
- 解决Jquery对input file控件的onchange事件只生效一次的问题
如题,解决办法的代码如下: 1. $('#fileId').live('change',function(){ //逻辑添加.... }); 2. $('#fileId').change(functi ...
- Android(Java):jni源代码
public void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); ...
- 如何查看ubuntu下显卡驱动是否已经成功安装
首先得安装mesa-utils,在终端输入命令:sudo apt-get install mesa-utils然后再运行命令:glxinfo | grep rendering如果结果是“yes”,证明 ...