RCNN (Regions with CNN) 目标物检测 Fast RCNN的基础
Abstract:
贡献主要有两点1:可以将卷积神经网络应用region proposal的策略,自底下上训练可以用来定位目标物和图像分割 2:当标注数据是比较稀疏的时候,在有监督的数据集上训练之后到特定任务的数据集上fine-tuning可以得到较好的新能,也就是说用Imagenet上训练好的模型,然后到你自己需要训练的数据上fine-tuning一下,检测效果很好。现在达到的效果比目前最好的DPM方法 mAP还要高上20点,目前voc上性能最好。
着篇文章主要是介绍RCNN,跟后面的,Fast RCNN和Faster RCNN比较关联,这篇文章是后两个的基础
1.介绍
在开始他说到LeCun对卷积神经网络中采用的SGD(通过反向传播的随机梯度下降算法)对网络训练很有效,也直接促进了利用CNN来做检测。
其实CNN的算法在90年代就已经出现了,可惜当时被SVM取代了,主要原因就是当时训练不动。2012年的时候Krizhevsky复燃了CNN,其在Imagenet的数据集上训练达到了非常好的效果,主要是用了LeCun中的一些技巧如(rectifying non-linearities and “dropout” regularization)
后来就有了讨论说把CNN方到目标检测上能达到什么样的效果。因此RossGirshick把问题主要聚集在了2个点上:
1一个是用深度网络来做一个检测,并且在整个high-capacity model中用较少的标注数据来training,比如几万张图像,(毕竟Imagenet上有上千万的图像数据)。不像图像分类任务,检测是需要定位的。因此RCNN里把这个定位转换成一个regression problem(即回归问题)。当然他们在当时也想采用最经典的也就是sliding window,在卷积层增加了较大的感受野。但是他们最后没有采用,因为之前的DPM中也已经不采用这种方法了,无效的操作太多(PS.这里是我个人感觉,而且会增加复杂度)。他们最后采用的是Recognition using region的策略(这种paradigm已经在目标识别和semantic segmention中取得了较好的成功)。在测试阶段,他们提取约2000K预选框,从预选框中通过CNN提取出fixed-length的特征,最后通过特定类别的SVM来分类。对于不同大小的ROI采用了(affine image warping)来调整到固定的size,这种方法是不考虑region的形状的。整个系统的overview
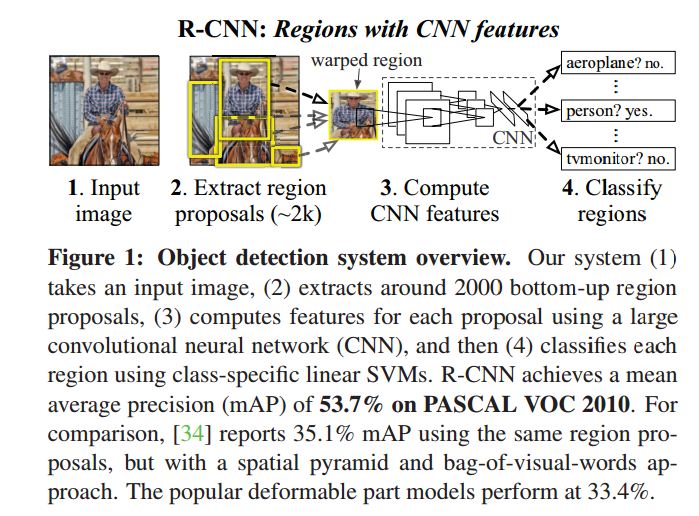
2.在实际检测中,训练的样本肯定是scarce,不足以训练一个大型的CNN网络。解决这个问题的方法是,首先通过无监督的预训练unsupervised pretraining,然后再进行supervised training,在实验中他们提到经过fine-tuninig,检测的mAP有8个点的提高。Ross提到Donahue的同时期的工作,其直接拿了krizhevsky的CNN网络用来做一个blackbox feature的extractor,这也在识别任务中表现出了较好的性能,如场景识别,细粒度的子分类,领域适应。分类计算中只有整个的分类工作只是一个矩阵相乘和非极大值抑制。
在错误分析中,可以发现bounding box的regression 可以明显的减少mislocalization。同理,作者说因为RCNN是工作在Region上的,因此其也可以较好的应用到semantic segmentation,最后也在voc2011上取得了较好的效果,比最好的高出1个点,(PS.我认为应该会有更好的性能,应该还没有做透,原来的那些分割仍然依赖浅层的特征)
特征提取:在网络之前,ROI不管大小形状都被缩放到一个固定的尺寸以适应网络。
2.2
测试时检测
在RCNN中,为每一类都训练了一个SVM,最后根据输出的特征类判断,每一个区域都有一个得分,最后通过greedy non-maximun supperssinon(for each class independently)来接受或者拒绝一个region,主要是看他这个有IoU的region是否比学习到的阈值有更高的得分。
对于运行分析
1.所有的CNN参数都在各个类别分享参数
2.CNN计算出来的参数是low dimensional 低维的,与其他方法比起来如空间金字塔,以及视觉词带模型
- The only class-specific computations are dot products between features and SVM weights and non-maximum suppression
4.RCNN可以应付类别很多情况并且不需要借助一些额外的近似手段,比如哈希什么的,别的方法在类别增长时,整个复杂度会上升很多,比之前的DPM的方法也要好很多
2.3 训练过程
supervised-pretraining ----> domain-specifi fine-tuning ---->object categroy classier
1.supervised-pretraining是在imagenet上训练好的模型
2.domian-specific fine-tuning 首先需要修改类别数目,并且在文中,Ross将IoU和GT大于0.5的看成是正样本,在SGD中 lr为pre-training rate的十分之一为0.001,这样不会影响预训练。在SGD中,每一次迭代,mini-batch大小是128,总共有32个postive window,96个negtive window.`
3可视化学习的特征
在可视化学习特征中中,采用了一个很大的局部感受野的数据集。这了主要对卷基层进行可视化,输入region图像,根据unit激活之的大小排序,来看他对什么样的输入敏感。下图可以看到有一些Unit对人脸敏感如1,有一些对点阵,狗敏感如2行,第三行,对红色敏感,对第四行对文字敏感,也能将一些特征融合到一起入颜色、纹理、形状,如5行的屋子。。等等
这里很关键!5层之后为全连接层,全连接层可以将这些丰富的特征进行组合建模!

3.2 关于参数消除的研究
1.performace没有fine-tuning
从表中可以看到fc7产生的特征比fc6澶色恒的特征要差,这也就是说29%差不多1.68million个数据是可以从CNN网络中去掉的,并且几乎对mAP没什么影响。更加惊讶的是,如果把f6和f7都去掉的话,只用pool5层的参数也就是大于整个网络6%的参数也可以取得不错的结果如下图所示:可以看到大部分representational的能力主要是来自于CNN的卷积层,而不是主要的全连接层。这个发现可以用在稠密的特征map中,比如说Hog。这种表现能力也就是说我们有可以将其应用到一些滑动窗检测子中如DPM,在pool5的特征基础之上。作者原文(Much of the CNN’s representationalpower comes from its convolutional layers, rather than fromthe much larger densely connected layers. This finding suggests potential utility in computing a dense feature map, in the sense of HOG, of an arbitrary-sized image by using only the convolutional layers of the CNN. This representation would enable experimentation with sliding-window detectors, including DPM, on top of pool5 features)
2.经过fine-tuning的性能
可以看到fine-tuning的效果还是很明显的,几乎提高了8个点,并且对于fc67的效果更明显,这也就是说从imagenet中学习到的pool5的特征比较general,并且对于性能的提升主要是来自对于在他们基础上的domain-specific具体应用场景的non-linear分类器的训练。

3.4 关于BBOX
首先需要明确的是,RCNN并不是从预选框里选择一个判断一下那么简单,在论文中的错误分析,大部分的检测错误的主要成分都是localize error 也就是定位错误,IoU在0.1和0.5之间。与别的类别以及背景confusion比例非常小,在这里作者根据最后输出的feature 进一步做了regression, 采用的是之前在DPM检测中的用的Linear regression model,这个让mAP大概提高了4个点。
4 Semantic segmentation
文中也提到了将RCNN网络用语分割,但是效果与目前较好的O2P的方法没有本质的提高约0.9。我认为主要还是网络学习过程并不足,其对于细粒度的特征没有一个整体的学习过程,目前在semantic segmentation上性能最好的是《Learning Deconvolution Network for Semantic Segmentation》目前在pascal-voc数据集上是第一的性能,他的网络中有一个对称的deconvolutoin network。
结束语:最近这几年确实,在目标物检测的性能上是停滞不前了,现在最好的DPM算法都是结合好多low-level的feature,并且这些feature都是手工设计的加上一些high-level context from detector和scene classifier。这篇文章给出了基于Region proposal和CNN网络极大的提高了mAP。有监督的预训练在特定场合的fine-tuning这一模式会针对很多数据系稀疏的是视觉问题有效。作者这里的意思是说拿Imagenet上训练好的那个模型,然后根据自己的特定应用场景,把模型用自己的数据fine-tuning一下,这样的做法是挺有效的。
RCNN (Regions with CNN) 目标物检测 Fast RCNN的基础的更多相关文章
- 基于候选区域的深度学习目标检测算法R-CNN,Fast R-CNN,Faster R-CNN
参考文献 [1]Rich feature hierarchies for accurate object detection and semantic segmentation [2]Fast R-C ...
- 目标检测算法的总结(R-CNN、Fast R-CNN、Faster R-CNN、YOLO、SSD、FNP、ALEXnet、RetianNet、VGG Net-16)
目标检测解决的是计算机视觉任务的基本问题:即What objects are where?图像中有什么目标,在哪里?这意味着,我们不仅要用算法判断图片中是不是要检测的目标, 还要在图片中标记出它的位置 ...
- 目标检测-Faster R-CNN
[目标检测]Faster RCNN算法详解 Ren, Shaoqing, et al. “Faster R-CNN: Towards real-time object detection with r ...
- Fast R-CNN论文理解
论文地址:https://arxiv.org/pdf/1504.08083.pdf 翻译请移步:https://blog.csdn.net/ghw15221836342/article/details ...
- Fast R-CNN论文详解 - CSDN博客
废话不多说,上车吧,少年 paper链接:Fast R-CNN &创新点 规避R-CNN中冗余的特征提取操作,只对整张图像全区域进行一次特征提取: 用RoI pooling层取代最后一层max ...
- rcnn,sppnet,fast rcnn,ohem,faster rcnn,rfcn
https://zhuanlan.zhihu.com/p/21412911 rcnn需要固定图片的大小,fast rcnn不需要 rcnn,sppnet,fast rcnn,ohem,faster r ...
- 深度学习中目标检测Object Detection的基础概念及常用方法
目录 关键术语 方法 two stage one stage 共同存在问题 多尺度 平移不变性 样本不均衡 各个步骤可能出现的问题 输入: 网络: 输出: 参考资料 What is detection ...
- Fast RCNN论文学习
Fast RCNN建立在以前使用深度卷积网络有效分类目标proposals的工作的基础上.使用了几个创新点来改善训练和测试的速度,同时还能增加检测的精确度.Fast RCNN训练VGG16网络的速度是 ...
- 深度学习论文翻译解析(十二):Fast R-CNN
论文标题:Fast R-CNN 论文作者:Ross Girshick 论文地址:https://www.cv-foundation.org/openaccess/content_iccv_2015/p ...
随机推荐
- svn 大全
环境:Win7 32 bit SVN简介:程序员在编写程序的过程中,每个程序员都会生成很多不同的版本,这就需要程序员有效的管理代码,在需要的时候可以迅速,准确取出相应的版本. Subversion是一 ...
- Python关键字参数
关键字参数允许你传入0个或任意个含参数名的参数,这些关键字参数在函数内部自动组装为一个dict.请看示例: #!/usr/bin/env python # -*- coding: utf-8 -*- ...
- 捋一捋Javascript数据类型转换规则
一.数据类型 5种基本数据类型:Null/Undefined/String/Boolean/Number 1种复杂数据类型:Object 二.数据类型检测 传送门<几种JS数据类型方式及其局限性 ...
- Vue入门演示
工作中用了很久vue,但是都是我们这边前端经理封装好的组件,想要看到底部的原理还要从层层代码里面剥离出来,逻辑太复杂,还不如自己一点点整理一下,一步一步走下去. github地址:https://gi ...
- mvc项目架构搭建之UI层的搭建
项目架构搭建之UI层的搭建 Contents 系列一[架构概览] 0.项目简介 1.项目解决方案分层方案 2.所用到的技术 3.项目引用关系 系列二[架构搭建初步] 4.项目架构各部分解析 5.项目创 ...
- SQL Server 分组 去除从复列
下面先来看看例子: table表 字段1 字段2 id name 1 a 2 b 3 c 4 c 5 ...
- 卸载openfire
首先,确保你已经关掉了openfire打开终端 (在应用程序-->实用工具-->)输入以下命令sudo rm -rf /Library/PreferencePanes/Openfire.p ...
- Masonry第三方代码约束
#import "RootViewController.h" #import "Masonry.h" @interface RootViewController ...
- IOS 网络浅析-(九 NSURLSession代理简介)
从最开始什么都不懂的小白,到到现在略知一二的小孩.我觉得不仅仅是我,大家应该都会注意到代理几乎贯穿着IOS,那么问题来了,我接下来要说什么呢,那就是.标题的内容啦.上篇网络系列的文章我介绍了NSURL ...
- 将spring源码导入到eclipse中
前置条件: 1. 正确安装jdk,并配置好JAVA_HOME.PATH.(我这里安装的是jdk1.8) 2. 正确安装好eclipse.(我的eclipse版本是: Neon Release (4.6 ...