Power Network(网络流最大流 & dinic算法 + 优化)
| Time Limit: 2000MS | Memory Limit: 32768K | |
| Total Submissions: 24019 | Accepted: 12540 |
Description
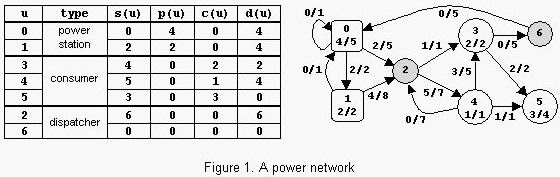
An example is in figure 1. The label x/y of power station u shows that p(u)=x and pmax(u)=y. The label x/y of consumer u shows that c(u)=x and cmax(u)=y. The label x/y of power transport line (u,v) shows that l(u,v)=x and lmax(u,v)=y. The power consumed is Con=6. Notice that there are other possible states of the network but the value of Con cannot exceed 6.
Input
Output
Sample Input
2 1 1 2 (0,1)20 (1,0)10 (0)15 (1)20
7 2 3 13 (0,0)1 (0,1)2 (0,2)5 (1,0)1 (1,2)8 (2,3)1 (2,4)7
(3,5)2 (3,6)5 (4,2)7 (4,3)5 (4,5)1 (6,0)5
(0)5 (1)2 (3)2 (4)1 (5)4
Sample Output
15
6
Hint
Source
#include<iostream>
#include<stdio.h>
#include<string.h>
using namespace std;
#define MAXN 202
const int INT_MAX = 0x3f3f3f3f ;
int s, t;
int n, np, nc, m;
char str[];
int c[MAXN][MAXN];
int f[MAXN][MAXN];
int e[MAXN];
int h[MAXN];
void push(int u, int v)
{
int d = min(e[u], c[u][v] - f[u][v]);
f[u][v] += d;
f[v][u] = -f[u][v];
e[u] -= d;
e[v] += d;
}
bool relabel(int u)
{
int mh = INT_MAX;
for(int i=; i<n+; i++)
{
if(c[u][i] > f[u][i])
mh = min(mh, h[i]);
}
if(mh == INT_MAX)
return false; //残留网络中无从u出发的路
h[u] = mh + ;
for(int i=; i<n+; i++)
{
if(e[u] == ) //已无余流,不需再次push
break;
if(h[i] == mh && c[u][i] > f[u][i]) //push的条件
push(u, i);
}
return true;
}
void init_preflow()
{
memset(h, , sizeof(h));
memset(e, , sizeof(e));
h[s] = n+;
for(int i=; i<n+; i++)
{
if(c[s][i] == )
continue;
f[s][i] = c[s][i];
f[i][s] = -f[s][i];
e[i] = c[s][i];
e[s] -= c[s][i];
}
}
void push_relabel()
{
init_preflow();
bool flag = true; //表示是否还有relabel操作
while(flag)
{
flag = false;
for(int i=; i<n; i++)
if(e[i] > )
flag = flag || relabel(i);
}
}
int main()
{
while(scanf("%d%d%d%d", &n, &np, &nc, &m) != EOF)
{
s = n; t = n+;
memset(c, , sizeof(c));
memset(f, , sizeof(f));
while(m--)
{
scanf("%s", &str);
int u=, v=, z=;
sscanf(str, "(%d,%d)%d", &u, &v, &z);
c[u][v] = z;
}
for(int i=; i<np+nc; i++)
{
scanf("%s", &str);
int u=, z=;
sscanf(str, "(%d)%d", &u, &z);
if(i < np)
c[s][u] = z;
else if(i >= np && i < np + nc)
c[u][t] = z;
}
push_relabel();
printf("%d\n", e[t]);
}
}
dinic递归 110ms / 非递归 110 或 94 ms:http://hefeijack.iteye.com/blog/1885944
dinic 63ms/SAP 63 ms:http://www.cnblogs.com/kuangbin/archive/2012/09/11/2680908.html
dinic 63ms :http://blog.csdn.net/u011721440/article/details/38611197
初学者可以先去poj1273试试水=。=
这道题只要加一个 源点 和 汇点 , 就万事大吉了。
自己写了一遍,用dinic的递归形式,一开始tle,但就加了一句话,813msAC,
貌似是一种优化,但为啥不清楚。
#include<stdio.h>
#include<string.h>
#include<queue>
#include<algorithm>
using namespace std;
const int M = , inf = 0x3f3f3f3f ;
int m , n ;
int map[M][M] ;
int dis[M]; bool bfs ()
{
queue <int> q ;
while (!q.empty ())
q.pop () ;
memset (dis , 0xff , sizeof(dis)) ;
dis[] = ;
q.push () ;
while (!q.empty () ) {
int u = q.front () ;
q.pop () ;
for (int v = ; v <= n ; v++) {
if (map[u][v] && dis[v] == -) {
dis[v] = dis[u] + ;
q.push (v) ;
}
}
}
if (dis[n] > )
return true ;
return false ;
} int find (int u , int low)
{
int a = ;
if (u == n)
return low ;
for (int v = ; v <= n ; v++) {
if (map[u][v] && dis[v] == dis[u] + && (a = find (v , min(map[u][v] , low)))) {
map[u][v] -= a ;
map[v][u] += a ;
return a ;
}
}
dis[u] = - ;//就这句
return ;
} int main ()
{
//freopen ("b.txt" , "r" , stdin) ;
int u , v , w ;
int ans ;
while (~ scanf ("%d%d" , &m , &n)) {
memset (map , , sizeof(map)) ;
while (m--) {
scanf ("%d%d%d" , &u , &v , &w) ;
map[u][v] += w ;
}
int maxn = ;
while (bfs()) {
if (ans = find( , inf))
maxn += ans ;
}
printf ("%d\n" , maxn) ;
}
return ;
}
用邻接表可以进一步优化(但上面那句话仍要加):因为用矩阵的话在find 和 bfs 时找点都要遍历一遍所有的点,但用邻接表的话可以很快找到。
110msAC:
#include<stdio.h>
#include<string.h>
#include<queue>
#include<algorithm>
using namespace std;
const int M = , inf = 0x3f3f3f3f ;
struct edge
{
int u , v , time_u ;
int w ;
}e[M * M * ];
int n , np , nc , m ;
int src , des ;
int cnt = ;
int dis[M] ;
char st[] ;
int head[M * M * ] ; void addedge (int u , int v , int w)
{
e[cnt].u = u ; e[cnt].v = v ; e[cnt].w = w ; e[cnt].time_u = head[u] ;
head[u] = cnt++ ;
e[cnt].v = u ; e[cnt].u = v ; e[cnt].w = ; e[cnt].time_u = head[v] ;
head[v] = cnt++ ;
}
bool bfs ()
{
queue <int> q ;
while (!q.empty ())
q.pop () ;
memset (dis , - , sizeof(dis)) ;
dis[src] = ;
q.push (src) ;
while (!q.empty ()) {
int u = q.front () ;
q.pop () ;
for (int i = head[u] ; i != - ; i = e[i].time_u) {
int v = e[i].v ;
if (dis[v] == - && e[i].w > ) {
dis[v] = dis[u] + ;
q.push (v) ;
}
}
}
if (dis[des] > )
return true ;
return false ;
} int find (int u , int low)
{
int a = ;
if (u == des)
return low ;
for (int i = head[u] ; i != - ; i = e[i].time_u) {
int v = e[i].v ;
if (e[i].w > && dis[v] == dis[u] + && (a = find(v , min (low , e[i].w)))) {
e[i].w -= a ;
e[i^].w += a ;
return a ;
}
}
dis[u] = - ;
return false ;
} int main ()
{
// freopen ("a.txt" , "r" , stdin) ;
int u , v , w ;
while (~ scanf ("%d%d%d%d" , &n , &np , &nc , &m)) {
src = n ;
des = n + ;
cnt = ;
memset (head , - , sizeof(head)) ;
while (m--) {
scanf ("%s" , st) ;
sscanf (st , "(%d,%d)%d" , &u , &v , &w) ;
addedge(u , v , w) ;
}
while (np--) {
scanf ("%s" , st) ;
sscanf (st , "(%d)%d" , &v , &w) ;
addedge (src , v , w) ;
}
while (nc--) {
scanf ("%s" , st) ;
sscanf (st , "(%d)%d" , &u , &w) ;
addedge (u , des , w) ;
} int ans = , res = ;
while (bfs()) {
while () {
if (ans = find(src , inf))
res += ans ;
else
break ;
}
}
printf ("%d\n" , res) ;
}
return ;
}
head[u]用来存放点u最新出现的时间 ,感觉和tarjan算法中的dfn[u]差不多;
time_u则保存上一次点u出现的时间 。
Power Network(网络流最大流 & dinic算法 + 优化)的更多相关文章
- POJ训练计划1459_Power Network(网络流最大流/Dinic)
解题报告 这题建模实在是好建.,,好贱.., 给前向星给跪了,纯dinic的前向星居然TLE,sad.,,回头看看优化,.. 矩阵跑过了.2A,sad,,, /******************** ...
- 网络流最大流——dinic算法
前言 网络流问题是一个很深奥的问题,对应也有许多很优秀的算法.但是本文只会讲述dinic算法 最近写了好多网络流的题目,想想看还是写一篇来总结一下网络流和dinic算法以免以后自己忘了... 网络流问 ...
- [讲解]网络流最大流dinic算法
网络流最大流算法dinic ps:本文章不适合萌新,我写这个主要是为了复习一些细节,概念介绍比较模糊,建议多刷题去理解 例题:codevs草地排水,方格取数 [抒情一下] 虽然老师说这个多半不考,但是 ...
- POJ 1459 Power Network(网络流 最大流 多起点,多汇点)
Power Network Time Limit: 2000MS Memory Limit: 32768K Total Submissions: 22987 Accepted: 12039 D ...
- POJ1459 Power Network 网络流 最大流
原文链接http://www.cnblogs.com/zhouzhendong/p/8326021.html 题目传送门 - POJ1459 题意概括 多组数据. 对于每一组数据,首先一个数n,表示有 ...
- 网络流——最大流Dinic算法
前言 突然发现到了新的一年什么东西好像就都不会了凉凉 算法步骤 建残量网络图 在残量网络图上跑增广路 重复1直到没有增广路(注意一个残量网络图要尽量把价值都用完,不然会浪费建图的时间) 代码实现 #i ...
- 网络流之最大流Dinic算法模版
/* 网络流之最大流Dinic算法模版 */ #include <cstring> #include <cstdio> #include <queue> using ...
- hdu-3572 Task Schedule---最大流判断满流+dinic算法
题目链接: http://acm.hdu.edu.cn/showproblem.php?pid=3572 题目大意: 给N个任务,M台机器.每个任务有最早才能开始做的时间S,deadline E,和持 ...
- 网络流(最大流-Dinic算法)
摘自https://www.cnblogs.com/SYCstudio/p/7260613.html 网络流定义 在图论中,网络流(Network flow)是指在一个每条边都有容量(Capacity ...
随机推荐
- Hibernate一级缓存与二级缓存的区别
一级缓存: 就是Session级别的缓存.一个Session做了一个查询操作,它会把这个操作的结果放在一级缓存中. 如果短时间内这个session(一定要同一个session)又做了同一个操作,那么h ...
- Android 中 appcompat_v7与各类资源报错问题
最近导一个项目进eclipse弄了一天都弄不好,先总结如下 首先按照网上其他同志的导入sdk/extras下的appcompat_v7项目.然后 发现 我们这里已经更新到6.0了,也就是说,我们报错的 ...
- 怎样写 OpenStack Neutron 的 Plugin (一)
鉴于不知道Neutron的人也不会看这篇文章,而知道的人也不用我再啰嗦Neutron是什么东西,我决定跳过Neutron简介,直接爆料. 首先要介绍一下我的开发环境.我没有使用DevStack,而是直 ...
- 全解┃OpenStack Newton发布,23家中国企业上榜(转载)
(转载自Openstack中文社区) 陈, 翔 2016-10-8 | 暂无评论 美国奥斯汀时间10月6日(北京时间6日24点),OpenStack Newton版本正式发布,在可扩展性.可靠性和用户 ...
- 我的bootstrap使用的历程
1.bootstrap快速开发,和amaze一样,同样是自己布局,然后找对应的模板,然后复制. 2.bootstrap实现的不完美的地方,我们要靠自己的样式去解决. 典型的居中布局, containe ...
- [AHOI2013]立方体(三维bit)
[Ahoi2013]立方体 Time Limit: 10 Sec Memory Limit: 64 MBSubmit: 130 Solved: 55[Submit][Status] Descrip ...
- [c#基础]堆和栈
前言 堆与栈对于理解.NET中的内存管理.垃圾回收.错误和异常.调试与日志有很大的帮助.垃圾回收的机制使程序员从复杂的内存管理中解脱出来,虽然绝大多数的C#程序并不需要程序员手动管理内存,但这并不代表 ...
- 编写兼容性JS代码
前文介绍了: 1 DOM四个常用的方法 2 使用DOM核心方法完成属性填充 本篇主要介绍在JS中需要注意的几个地方,另外为了减小html与javascript的耦合使用java进行onclick方法编 ...
- rational rose USE CASE
- Servlet Study 1
this content below are come from the JSR154 by sun Just for record purpose. if this relate to some ...