R语言--数据预处理
一、日期时间、字符串的处理
日期
Date: 日期类,年与日
POSIXct: 日期时间类,精确到秒,用数字表示
POSIXlt: 日期时间类,精确到秒,用列表表示
Sys.date(), date(), difftime(), ISOdate(), ISOdatetime()
#得到当前日期时间
(d1=Sys.Date()) #日期 年月日
(d3=Sys.time()) #时间 年月日时分秒 通过format输出指定格式的时间
(d2=date()) #日期和时间 年月日时分秒 "Fri Aug 20 11:11:00 1999" myDate=as.Date('2007-08-09')
class(myDate) #Date
mode(myDate) #numeric #日期转字符串
as.character(myDate) birDay=c('01/05/1986','08/11/1976') #
dates=as.Date(birDay,'%m/%d/%Y') #向量化运算,对向量进行转换
dates # %d 天 (01~31)
# %a 缩写星期(Mon)
# %A 星期(Monday)
# %m 月份(00~12)
# %b 缩写的月份(Jan)
# %B 月份(January)
# %y 年份(07)
# %Y 年份(2007)
# %H 时
# %M 分
# %S 秒 td=Sys.Date()
format(td,format='%B %d %Y %s')
format(td,format='%A,%a ')
format(Sys.time(), '%H %h %M %S %s') #日期转换成数字
as.integer(Sys.Date()) #自1970年1月1号至今的天数
as.integer(as.Date('1970-1-1')) #
as.integer(as.Date('1970-1-2')) # sdate=as.Date('2004-10-01')
edate=as.Date('2010-10-22')
days=edate-sdate
days #时间类型相互减,结果显示相差的天数 ws=difftime(Sys.Date(),as.Date('1956-10-12'),units='weeks') #可以指定单位 #把年月日拼成日期
(d=ISOdate(,,));class(d) #ISOdate 的结果是POSIXct
as.Date(ISOdate(,,)) #将结果转换为Date ISOdate(,,) #不存在的日期 结果为NA #批量转换成日期
years=c(,,,,,)
months=
days=c(,,,,,) as.Date(ISOdate(years,months,days)) #提取日期时间的一部分
p=as.POSIXlt(Sys.Date())
p=as.POSIXlt(Sys.time())
Sys.Date()
Sys.time()
p$year + #年份需要加1900
p$mon + #月份需要加1
p$mday p$hour
p$min
p$sec
字符串处理
nchar() 、length()
paste()、outer()
substr()、strsplit()
sub()、gsub()、grep()、regexpr()、grepexpr()
#字符串
x='hello\rwold\n' cat(x) #woldo hello遇到\r光标移到头接着打印wold覆盖了之前的hell变成woldo
print(x) #
#字符串长度
nchar(x) #字符串长度
length(x) #1 向量中元素的个数 #字符串拼接
board=paste('b',:,sep='-') #"b-1" "b-2" "b-3" "b-4"
board mm=paste('mm',:,sep='-') #"mm-1" "mm-2" "mm-3"
mm outer(board,mm,paste,sep=':') #向量的外积
#[,1] [,2] [,3]
#[1,] "b-1:mm-1" "b-1:mm-2" "b-1:mm-3"
#[2,] "b-2:mm-1" "b-2:mm-2" "b-2:mm-3"
#[3,] "b-3:mm-1" "b-3:mm-2" "b-3:mm-3"
#[4,] "b-4:mm-1" "b-4:mm-2" "b-4:mm-3" #拆分提取
board
substr(board,,) #子串
strsplit(board,'-',fixed=T) #拆分 #修改
sub('-','.',board,fixed=T) #修改指定字符
board
mm #"mm-1" "mm-2" "mm-3"
sub('m','p',mm) #替换第一个匹配项 "pm-1" "pm-2" "pm-3"
gsub('m','p',mm) #替换全部匹配项 "pp-1" "pp-2" "pp-3" #查找
mm=c(mm, 'mm4') #"mm-1" "mm-2" "mm-3" "mm4"
mm
grep('-',mm) #1 2 3 向量中1,2,3包含'-' regexpr('-',mm) #匹配成功会返回位置信息,没有找到则返回-1
二、数据预处理
保证数据质量
准确性
完整性
一致性
冗余性
时效性
...
1、提取有效数据,需要业务人员配合(主观),及相关的技术手段保障
2、了解数据定义,统一对数据定义的理解
...
数据集成 : 对多数据源进行整合
数据转换 :
数据清洗 : 异常数据,缺失数据
数据约简 : 提炼,行,列
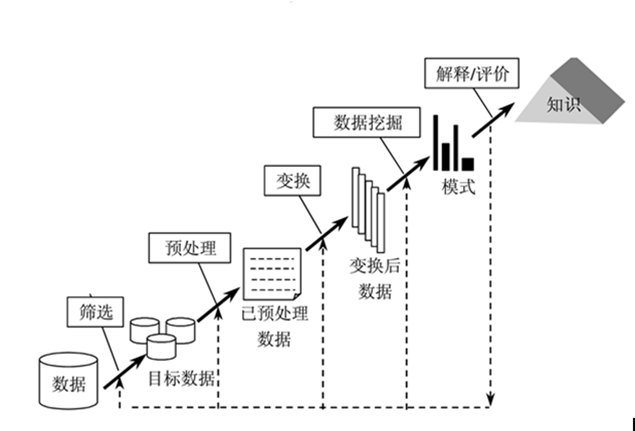
三、数据集成
通过merge对数据进行集成
#数据集成
#merge pylr::join (包::函数)
(customer = data.frame(Id=c(:),State=c(rep("北京",),rep("上海",))))
(ol = data.frame(Id=c(,,,),Product=c('IPhone','Vixo','mi','Note2'))) merge(customer,ol,by=('Id')) #inner join
merge(customer,ol,by=('Id'),all=T) # full join
merge(customer,ol,by=('Id'),all.x=T) # left outer join 左链接,左边数据都在
merge(customer,ol,by=('Id'),all.y=T) # right outer join 右链接,右边数据都在 #union 去重 在df1 和df2 有相同的列名称下
(df1=data.frame(id=seq(,by=,length=),name=paste('Zhang',seq(,by=,length=))))
(df2=data.frame(id=seq(,by=,length=),name=paste('Zhang',seq(,by=,length=)))) rbind(df1,df2) merge(df1,df2,all=T) #去重,不使用by merge(df1,df2,by=('id')) #重名的列会被更改显示
四、数据转换
构造属性
规范化(极差化、标准化)
离散化
改善分布
R语言--数据预处理的更多相关文章
- R语言数据预处理
R语言数据预处理 一.日期时间.字符串的处理 日期 Date: 日期类,年与日 POSIXct: 日期时间类,精确到秒,用数字表示 POSIXlt: 日期时间类,精确到秒,用列表表示 Sys.date ...
- R语言数据接口
R语言数据接口 R语言处理的数据一般从外部导入,因此需要数据接口来读取各种格式化的数据 CSV # 获得data是一个数据帧 data = read.csv("input.csv" ...
- R语言数据的导入与导出
1.R数据的保存与加载 可通过save()函数保存为.Rdata文件,通过load()函数将数据加载到R中. > a <- 1:10 > save(a,file='d://data/ ...
- R语言 数据重塑
R语言数据重塑 R语言中的数据重塑是关于改变数据被组织成行和列的方式. 大多数时间R语言中的数据处理是通过将输入数据作为数据帧来完成的. 很容易从数据帧的行和列中提取数据,但是在某些情况下,我们需要的 ...
- 最棒的7种R语言数据可视化
最棒的7种R语言数据可视化 随着数据量不断增加,抛开可视化技术讲故事是不可能的.数据可视化是一门将数字转化为有用知识的艺术. R语言编程提供一套建立可视化和展现数据的内置函数和库,让你学习这门艺术.在 ...
- 第六篇:R语言数据可视化之数据分布图(直方图、密度曲线、箱线图、等高线、2D密度图)
数据分布图简介 中医上讲看病四诊法为:望闻问切.而数据分析师分析数据的过程也有点相似,我们需要望:看看数据长什么样:闻:仔细分析数据是否合理:问:针对前两步工作搜集到的问题与业务方交流:切:结合业务方 ...
- 第三篇:R语言数据可视化之条形图
条形图简介 数据可视化中,最常用的图非条形图莫属,它主要用来展示不同分类(横轴)下某个数值型变量(纵轴)的取值.其中有两点要重点注意: 1. 条形图横轴上的数据是离散而非连续的.比如想展示两商品的价格 ...
- 第五篇:R语言数据可视化之散点图
散点图简介 散点图通常是用来表述两个连续变量之间的关系,图中的每个点表示目标数据集中的每个样本. 同时散点图中常常还会拟合一些直线,以用来表示某些模型. 绘制基本散点图 本例选用如下测试数据集: 绘制 ...
- 第四篇:R语言数据可视化之折线图、堆积图、堆积面积图
折线图简介 折线图通常用来对两个连续变量的依存关系进行可视化,其中横轴很多时候是时间轴. 但横轴也不一定是连续型变量,可以是有序的离散型变量. 绘制基本折线图 本例选用如下测试数据集: 绘制方法是首先 ...
随机推荐
- 【原创】Scrum模式也要根据自身特点微调,不能教条
手上的项目在用Scrum模式开发,运用的是禅道这个国产的平台,运作得还不错,具体如下: 1.整个开发团队有10个人,分为:新功能开发组和系统优化组,每组配备一个技术经理2.人员分在两个办公地点(同一城 ...
- Spring webapp - shutting down threads on Application stop
显示使用线程池Executors,必须执行 pool.shutdown() 否则会存在线程池泄露: http://stackoverflow.com/questions/22650569/spring ...
- java的基本认识
一.java的特点: 1.跨平台性:不受计算机硬件及操作系统的约束而在任意计算机环境下运行. 2.面向对象:以对象为基本粒度,基下包含属性和方法. 3.安全性:语言级安全性.编译性安全性.运行时安全性 ...
- oracle直通车第二周习题
1.教材第二章课后作业 1,2,3,4题. 答:1. 创建一查询,显示与Blake在同一部门工作的雇员的项目和受雇日期,但是Blake不包含在内. 2. 显示位置在Dallas的部门内的雇员姓名.变化 ...
- 解决ftp连接出现 无法从控制 Socket 读取。Socket 错误 = #10054。
ftp连接会显示以下错误信息 无法从控制 Socket 读取.Socket 错误 = #10054 或者是这样的信息 Opening data channel for directory list.T ...
- Android主流UI开源库整理(转载)
http://www.jianshu.com/p/47a4a7b99364 标题隐含了两个层面的意思,一个是主流,另一个是UI.主流既通用,一些常规的按钮.Switch.进度条等控件都是通用控件,因此 ...
- css学习笔记(4)
让顶部导航固定于页面的最顶端,无论页面上下滚动,顶部导航始终处在最顶端. *{ margin:0; padding:0}body{ padding-top:60px; }#nav{ width:100 ...
- poj 1416 (hdu 1539)Shredding Company:剪枝搜索
点击打开链接 题目大意是有一个分割机,可以把一串数字分割成若干个数字之后求和,题目输入一个数字上界和待分割的数字,让我们求出分割后数字之和在不超过给定max的情况下的最大值,并且给出分割方案,如果没有 ...
- HTML中行内元素与块级元素的区别
块级元素:独占一行,可设宽高,内外边距:块级元素有form,p,h1到h6,ol ,ul ,dl和dd和dt ,hr,li,pre,caption ,div ,table ,tr ,td ,th等. ...
- 学习了一下javascript的模块化编程
现在在我脑海里关于“模块化”的概念是这些词:简单.具有逻辑之美.易用.健壮.可扩展.似乎这些形容与我现在水平写出的代码有点格格不入啊. 所以今天想了解和简单的实践一下“模块化开发”. 1.首先学习一下 ...