Dropout 上
From 《白话深度学习与TensorFlow》
Dropout 顾名思义是“丢弃”,在一轮训练阶段丢弃一部分网络节点,比如可以在其中的某些层上临时关闭一些节点,让他们既不输入也不输出,这样相当于网络的结构发生了改变。而在下一轮训练过程中再选择性地临时关闭一些节点,原则上都是随机性。这样每一次训练相当于网络的一部分所形成的一个子网络或者子模型。而这种情况同时也在一种程度上降低了VC维的数量,减小过拟合的风险。在最终的分类阶段将所有的节点都置于有效状态,这样就可以把训练中得到的所有子网络并联使用,形成一个由多个VC维较低的部分的分类模型所组成的完整的分类模型。
在TensorFlow中设置训练当中的Dropout比例只要加入以下代码就可以:
keep_pro=tf.placeholder(tf.float32)
h_fc1_drop=tf.nn.dropout(h_fc1,keep_prob)
From 《Deep Learning》
先看一下bagging(bagging aggregating)吧,bagging是通过结合几个模型降低泛化误差的技术。主要想法是分别训练几个不同的模型,然后让所有模型表决测试样例的输出,被称为模型平均(model averaging)。Bagging学习是,定义k个不同的模型,从训练集有放回采样构造k个不同的数据集,然后在训练集i上训练模型i。
Dropout 提供了一种廉价的Bagging集成近似,能够训练和评估指数级数量的神经网络。Dropout训练的集成包括所有从基础网络除去非输出单元后形成的子网络。最先进的网络基于一系列仿射变换和非线性变换,我们只需要将一些单元的输出乘以零就能够有效地删除一个单元。


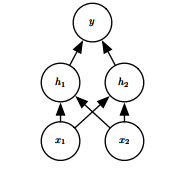


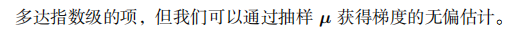

计算方便是Dropout的一个优点。
Dropout的另一个显著优点是不怎么限制使用的模型或者训练过程。
Dropout是一个正则化技术,它减少了模型的有效容量。目前为止,Dropout仍然是最广泛使用的隐式集成方法。
一种关于Dropout的重要见解是,通过随机行为训练网络并平均多个随机决定进行预测,实现了一种参数共享的Bagging形式。
Dropout不仅仅是训练一个Bagging的集成模型,而且是共享隐藏单元的集成模型。
Dropout正则化每个隐藏单元不仅是一个很好的特征,更需要在许多情况下是良好的特征。
相比于独立模型集成获得泛化误差改进,Dropout会带来额外的改进。
Dropout强大的大部分原因来自施加到隐藏单元的掩码噪声。Dropout的另一个重要方面是噪声是乘性的。
另一种深度学习算法——批标准化,在训练时向隐藏单元引入加性和乘性噪声重新参数化模型。
批标准化的目的是改善优化,但是噪声具有正则化的效果,有时没有必要再使用Dropout.
(正则化:

)
补充:
1.dropout解决的问题---过拟合(https://blog.csdn.net/loveliuzz/article/details/82912349)
过拟合是指模型训练到一定程度后,在训练集上得到的测试误差远大于在测试集上得到的误差。
导致过拟合的直接原因是模型学习了太多噪声模式,并错误的将其视为数据模式;导致过拟合的主要原因有:
1. 训练数据集太小
2. 模型太复杂
3. 过度训练
常用的过拟合解决方案
知道了产生过拟合的原因,就可以制定相应的解决方案,一般而言,解决的主要方法有:增加训练数据量、减少模型的复杂度、添加正则项等。在深度学习中,以上方法都可以使用,但是dropout是一个更加高效、简单的防止过拟合的方法。
dropout为什么可以防止过拟合
我们知道“随机森林”是一种不容易发生过拟合的算法,其采用的方法是“bagging”,即通过对多个树的输出结果加权平均,得出最后的结果。而每棵树都是在不同的训练集上、设置不同的参数得到的,因此是一种典型的通过多个不同参数,甚至不同类型的模型来降低方差的一种方法。这种方法对传统的机器学习算法、或者小型的NN模型可行,但是当数据量很大、模型很复杂的时候,我们不能训练多个不同的模型出来做”bagging”,因为深度神经网络的训练是一个很耗时的过程,需要大量的计算资源和时间。
dropout则为这种思想提供了一种“廉价”的解决方案,因为每一次迭代的过程中,我们会随机dropout掉一些神经元(至于在那一层做dropout,需要看不同的情况),如果设置的dropout的值为0.5,则表示每个神经元有50%的概率被留下来,50%的概率被”抹去“。这就相当于我们从原来的神经网络中随机采样了50%的节点,组成了一个新的神经网络,这个是原来的神经网络的一个子网络,但是规模要比原来的神经网络小很多,并且训练代价也比较小, 这个新的子网络就相当于是”随即森林“中的一个子树(sub-tree)了。我们多次迭代优化,每次迭代优化都会做这样的”随机采样“,从原来的网络中构造一个子网络(sub-network),而每次构造的网络也都不尽相同,这就使得学习到的sub-network在结果上差异性,最后再对这些每个迭代学习到的不同的sub-network做一个”bagging“来得到最终的输出结果。
dropout中的一些细节问题
- 如何对多个不同的sub-network做bagging:这里并没有做真正意义上的bagging,我们预测的时候,其实使用的整个完整的神经网络,并没有做任何dropout。这里面有一个”权值共享“的概念,正是这个概念让dropout的计算变得可行。因为每次迭代都会产生不用的sub-network,优化不同的权值,这必然使得前后两次之间的sub-network有相同的神经元被保留下来,那么这些神经元对应的权值没有必要在重新开始优化,而是继续沿用上一个迭代优化好的值。这就大大减少了优化单个sub-network的时间,使得在很少的时间内,这个sub-network就可以得到不错的泛化效果。否则,每个迭代步骤都要从新初始化权值矩阵,开始优化,这又是一个巨大的计算开销。
- train 和 test 的时候,dropout的概率怎么设置:按照原始的论文中,假设dropout的值是 p%,原始神经网络的神经元个数是N,因为在训练的过程中只有 p% 的神经元被保留下来,相应也只有p%的需要被优化的权值保留下来,这导致dropout后sub-network的输出也是整个原始神经网络的输出值的p%。所以,在测试的是时候使用的整个神经网络,我们只需要将每一层的权值矩阵乘以p%就可以保证测试网络的输出期望和训练网络的输出期望值大小一致了。
- 为什么很少见CNN层加dropout: 这种情况确实不多见,典型的TextCNN模型,就是没有在卷积层加dropout。但是原始论文中确实又指出可以在卷积层做dropout ,只是收益并不是太明显。另外,dropout对于具有大量参数的全连接效果最好,而CNN的卷积层不是全连接,参数不是很多,所以效果不明显。论文还建议如果在CNN中加,最好是在开始的层加dropout,越往后的层,越是要小心加dropout。
- 神经网络加上dropout后,test loss 比 train loss还要小:正常,在不考虑测试集采样偏差的情况下,这种情况的解释是:每次train loss是在一个batch上计算的,而单个batch又是在一个通过dropout得到的sub-network计算得到的,即相当于在单颗树上得到的train loss;而测试的时候,用的整个神经网络,即相当于在整个”森林“上做预测,结果当然会好一下。
训练有scale,测试不用管。
训练没scale,测试要乘p。
https://yq.aliyun.com/articles/68901
Dropout 上的更多相关文章
- CS231n 2016 通关 第六章 Training NN Part2
本章节讲解 参数更新 dropout ================================================================================= ...
- 在RNN中使用Dropout
dropout在前向神经网络中效果很好,但是不能直接用于RNN,因为RNN中的循环会放大噪声,扰乱它自己的学习.那么如何让它适用于RNN,就是只将它应用于一些特定的RNN连接上. LSTM的长期记 ...
- Deep Learning 23:dropout理解_之读论文“Improving neural networks by preventing co-adaptation of feature detectors”
理论知识:Deep learning:四十一(Dropout简单理解).深度学习(二十二)Dropout浅层理解与实现.“Improving neural networks by preventing ...
- 正则化方法:L1和L2 regularization、数据集扩增、dropout
正则化方法:防止过拟合,提高泛化能力 在训练数据不够多时,或者overtraining时,常常会导致overfitting(过拟合).其直观的表现如下图所示,随着训练过程的进行,模型复杂度增加,在tr ...
- 深度学习(dropout)
other_techniques_for_regularization 随手翻译,略作参考,禁止转载 www.cnblogs.com/santian/p/5457412.html Dropout: D ...
- Deep learning:四十一(Dropout简单理解)
前言 训练神经网络模型时,如果训练样本较少,为了防止模型过拟合,Dropout可以作为一种trikc供选择.Dropout是hintion最近2年提出的,源于其文章Improving neural n ...
- 简单理解dropout
dropout是CNN(卷积神经网络)中的一个trick,能防止过拟合. 关于dropout的详细内容,还是看论文原文好了: Hinton, G. E., et al. (2012). "I ...
- [转]理解dropout
理解dropout 原文地址:http://blog.csdn.net/stdcoutzyx/article/details/49022443 理解dropout 注意:图片都在github上 ...
- [CS231n-CNN] Training Neural Networks Part 1 : parameter updates, ensembles, dropout
课程主页:http://cs231n.stanford.edu/ ___________________________________________________________________ ...
随机推荐
- 取消overflow-scroll的滚动条
通常情况下设置完overflow:scroll之后,就会在页面中出现滚动条,下边的方法可以取消掉此滚动条: container为当前设置overflow:scroll的元素 1.使用以下CSS可以隐藏 ...
- Android Studio配置GreenDAO 3.2.0和使用方法
我相信,在平时的开发过程中,大家一定会或多或少地接触到SQLite.然而在使用它时,我们往往需要做许多额外的工作,像编写SQL语句与解析查询结果等.所以,适用于Android ORM框架也就孕育而生了 ...
- c#初学12-12-为什么mian函数必须是static的
c#初学12-12-为什么mian函数必须是static的 c#程序刚开始启动的时候都会有唯一一个入口函数main()函数, 而非静态成员又称实例成员,必须作用于实例.在程序刚开始运行的时候,未建立任 ...
- Qwiklab'实验-Hadoop, IoT, IAM, Key Management'
title: AWS之Qwiklab subtitle: 1. Qwiklab'实验-Hadoop, IoT, IAM, Key Management Service' date: 2018-09-1 ...
- baidu练习/html/css
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" ...
- 服务器搭建域控与SQL Server的AlwaysOn环境过程(五)配置异地机房节点
0 引言 注意点1 注意异地节点最好至少有2个AG节点,否则在本地节点进行手动故障转移的时候会出现仲裁警告,提示WSFC集群有脱机危险 在异地节点只有一个的情况下,虽然Windows2012R2有动态 ...
- redis 篇 - hash
hash 可以认为是 python 中的字典 field 不允许重复 string类型的field和value的映射表 每个hash可以存储 232 - 1 键值对(40多亿) 方法 hest key ...
- ELK搭建和部署-----(上半部分)
本实验基于centos7安装部署操作步骤如下: 1.首先准备两台centos7系统,IP地址自行定义. 2.先在服务器上安装时间同步中间件为chronyc 3.并启动命令为systemctl star ...
- linux下如何查看cpu信息
linux的cpu信息可以从文件中cpuinfo读取. 执行命令: # cat /proc/cpuinfo 我们一般看到的processor是逻辑核. 它的计数是从0开始的,例如这里看到的是31 ...
- # quill-image-extend-module :实现vue-quill-editor图片上传,复制粘贴,拖拽
改造vue-quill-editor: 结合element-ui上传图片到服务器 quill-image-extend-module vue-quill-editor的增强模块, 功能: 提供图片上传 ...