springboot+webmagic实现java爬虫jdbc及mysql
前段时间需要爬取网页上的信息,自己对于爬虫没有任何了解,就了解了一下webmagic,写了个简单的爬虫。
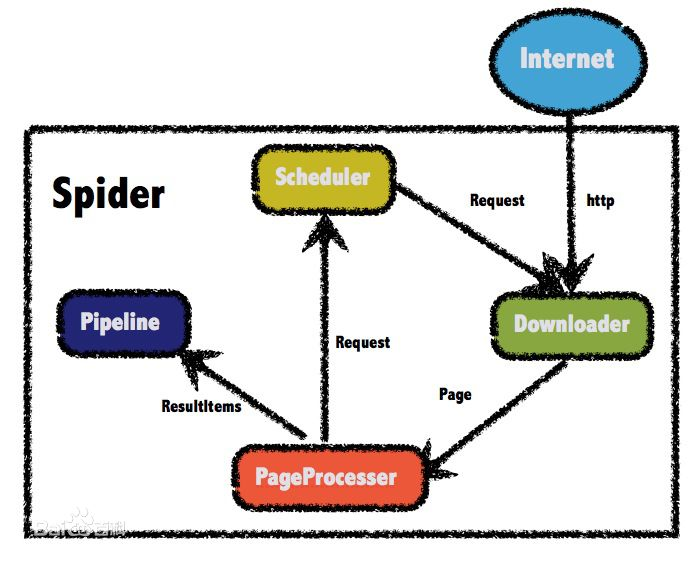
一、首先介绍一下webmagic:
webmagic采用完全模块化的设计,功能覆盖整个爬虫的生命周期(链接提取、页面下载、内容抽取、持久化),支持多线程抓取,分布式抓取,并支持自动重试、自定义UA/cookie等功能。
实现理念:
Maven依赖:
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.</version>
</dependency> <dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
jdbc模式:
ublic class CsdnBlogDao {
private Connection conn = null;
private Statement stmt = null;
public CsdnBlogDao() {
try {
Class.forName("com.mysql.jdbc.Driver");
String url = "jdbc:mysql://localhost:3306/test?"
+ "user=***&password=***3&useUnicode=true&characterEncoding=UTF8";
conn = DriverManager.getConnection(url);
stmt = conn.createStatement();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}
}
public int add(CsdnBlog csdnBlog) {
try {
String sql = "INSERT INTO `test`.`csdnblog` (`keyes`, `titles`, `content` , `dates`, `tags`, `category`, `views`, `comments`, `copyright`) VALUES (?, ?, ?, ?, ?, ?, ?, ?,?);";
PreparedStatement ps = conn.prepareStatement(sql);
ps.setInt(, csdnBlog.getKey());
ps.setString(, csdnBlog.getTitle());
ps.setString(,csdnBlog.getContent());
ps.setString(, csdnBlog.getDates());
ps.setString(, csdnBlog.getTags());
ps.setString(, csdnBlog.getCategory());
ps.setInt(, csdnBlog.getView());
ps.setInt(, csdnBlog.getComments());
ps.setInt(, csdnBlog.getCopyright());
return ps.executeUpdate();
} catch (SQLException e) {
e.printStackTrace();
}
return -;
}
}
实体类:
public class CsdnBlog {
private int key;// 编号
private String title;// 标题
private String dates;// 日期
private String tags;// 标签
private String category;// 分类
private int view;// 阅读人数
private int comments;// 评论人数
private int copyright;// 是否原创
private String content; //文字内容
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
public int getKey() {
return key;
}
public void setKey(int key) {
this.key = key;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getDates() {
return dates;
}
public void setDates(String dates) {
this.dates = dates;
}
public String getTags() {
return tags;
}
public void setTags(String tags) {
this.tags = tags;
}
public String getCategory() {
return category;
}
public void setCategory(String category) {
this.category = category;
}
public int getView() {
return view;
}
public void setView(int view) {
this.view = view;
}
public int getComments() {
return comments;
}
public void setComments(int comments) {
this.comments = comments;
}
public int getCopyright() {
return copyright;
}
public void setCopyright(int copyright) {
this.copyright = copyright;
}
@Override
public String toString() {
return "CsdnBlog [key=" + key + ", title=" + title + ", content=" + content + ",dates=" + dates + ", tags=" + tags + ", category="
+ category + ", view=" + view + ", comments=" + comments + ", copyright=" + copyright + "]";
}
}
启动类:
public class CsdnBlogPageProcessor implements PageProcessor {
private static String username="CHENYUFENG1991"; // 设置csdn用户名
private static int size = ;// 共抓取到的文章数量
// 抓取网站的相关配置,包括:编码、抓取间隔、重试次数等
private Site site = Site.me().setRetryTimes().setSleepTime();
public Site getSite() {
return site;
}
// process是定制爬虫逻辑的核心接口,在这里编写抽取逻辑
public void process(Page page) {
// 列表页
if (!page.getUrl().regex("http://blog\\.csdn\\.net/" + username + "/article/details/\\d+").match()) {
// 添加所有文章页
page.addTargetRequests(page.getHtml().xpath("//div[@id='article_list']").links()// 限定文章列表获取区域
.regex("/" + username + "/article/details/\\d+")
.replace("/" + username + "/", "http://blog.csdn.net/" + username + "/")// 巧用替换给把相对url转换成绝对url
.all());
// 添加其他列表页
page.addTargetRequests(page.getHtml().xpath("//div[@id='papelist']").links()// 限定其他列表页获取区域
.regex("/" + username + "/article/list/\\d+")
.replace("/" + username + "/", "http://blog.csdn.net/" + username + "/")// 巧用替换给把相对url转换成绝对url
.all());
// 文章页
} else {
size++;// 文章数量加1
// 用CsdnBlog类来存抓取到的数据,方便存入数据库
CsdnBlog csdnBlog = new CsdnBlog();
// 设置编号
csdnBlog.setKey(Integer.parseInt(
page.getUrl().regex("http://blog\\.csdn\\.net/" + username + "/article/details/(\\d+)").get()));
// 设置标题
csdnBlog.setTitle(
page.getHtml().xpath("//div[@class='article_title']//span[@class='link_title']/a/text()").get());
//设置内容
csdnBlog.setContent(
page.getHtml().xpath("//div[@class='article_content']/allText()").get());
// 设置日期
csdnBlog.setDates(
page.getHtml().xpath("//div[@class='article_r']/span[@class='link_postdate']/text()").get());
// 设置标签(可以有多个,用,来分割)
csdnBlog.setTags(listToString(page.getHtml().xpath("//div[@class='article_l']/span[@class='link_categories']/a/allText()").all()));
// 设置类别(可以有多个,用,来分割)
csdnBlog.setCategory(listToString(page.getHtml().xpath("//div[@class='category_r']/label/span/text()").all()));
// 设置阅读人数
csdnBlog.setView(Integer.parseInt(page.getHtml().xpath("//div[@class='article_r']/span[@class='link_view']")
.regex("(\\d+)人阅读").get()));
// 设置评论人数
csdnBlog.setComments(Integer.parseInt(page.getHtml()
.xpath("//div[@class='article_r']/span[@class='link_comments']").regex("\\((\\d+)\\)").get()));
// 设置是否原创
csdnBlog.setCopyright(page.getHtml().regex("bog_copyright").match() ? : );
// 把对象存入数据库
new CsdnBlogDao().add(csdnBlog);
// 把对象输出控制台
System.out.println(csdnBlog);
}
}
// 把list转换为string,用,分割
public static String listToString(List<String> stringList) {
if (stringList == null) {
return null;
}
StringBuilder result = new StringBuilder();
boolean flag = false;
for (String string : stringList) {
if (flag) {
result.append(",");
} else {
flag = true;
}
result.append(string);
}
return result.toString();
}
public static void main(String[] args) {
long startTime, endTime;
System.out.println("【爬虫开始】...");
startTime = System.currentTimeMillis();
// 从用户博客首页开始抓,开启5个线程,启动爬虫
Spider.create(new CsdnBlogPageProcessor()).addUrl("http://blog.csdn.net/" + username).thread().run();
endTime = System.currentTimeMillis();
System.out.println("【爬虫结束】共抓取" + size + "篇文章,耗时约" + ((endTime - startTime) / ) + "秒,已保存到数据库,请查收!");
}
}
使用mysql类型:
public class GamePageProcessor implements PageProcessor {
private static final Logger logger = LoggerFactory.getLogger(GamePageProcessor.class);
private static DianJingService d;
private static BannerService bs;
private static SportService ss;
private static YuLeNewsService ys;
private static UpdateService ud ;
// 抓取网站的相关配置,包括:编码、抓取间隔、重试次数等
private Site site = Site.me().setRetryTimes().setSleepTime();
public Site getSite() {
return site;
}
// process是定制爬虫逻辑的核心接口,在这里编写抽取逻辑
public static void main(String[] args) {
ConfigurableApplicationContext context= SpringApplication.run(GamePageProcessor.class, args);
d = context.getBean(DianJingService.class);
//Spider.create(new GamePageProcessor()).addUrl("网址").thread(5).run();
}
public void process(Page page) {
Selectable url = page.getUrl();
if (url.toString().equals("网址")) {
DianJingVideo dv = new DianJingVideo();
List<String> ls = page.getHtml().xpath("//div[@class='v']/div[@class='v-meta va']/div[@class='v-meta-title']/a/text()").all();
//hrefs
List<String> ls1 = page.getHtml().xpath("//div[@class='v']/div[@class='v-link']/a/@href").all();//获取a标签的href
List<String> ls2 = page.getHtml().xpath("//div[@class='v']/div[@class='v-meta va']/div[@class='v-meta-entry']/div[@class='v-meta-data']/span[@class='r']/text()").all();
//photo
List<String> ls3 = page.getHtml().xpath("//div[@class='v']/div[@class='v-thumb']/img/@src").all();
for (int i = ; i < ; i++) {
dv.setTitles(ls.get(i));
dv.setCategory("");
dv.setDates(ls2.get(i));
dv.setHrefs(ls1.get(i));
dv.setPhoto(ls3.get(i));
dv.setSources("");
d.addVideo(dv);
}
}
}
Controller:
@Controller
@RequestMapping(value = "/dianjing")
public class DianJingController {
@Autowired
private DianJingService s; /*
手游
*/
@RequestMapping("/dianjing")
@ResponseBody
public Object dianjing(){
List<DianJing> list = s.find2();
JSONObject jo = new JSONObject();
if(list!=null){ jo.put("code",);
jo.put("success",true);
jo.put("count",list.size());
jo.put("list",list);
}
return jo;
}
}
实体类就不展示了
dao层
@Insert("insert into dianjing (titles,dates,category,hrefs,photo,sources) values(#{titles},#{dates},#{category},#{hrefs},#{photo},#{sources})")
int adddj(DianJing dj);
springboot+webmagic实现java爬虫jdbc及mysql的更多相关文章
- Java使用Jdbc操作MySql数据库(一)
这个示例是Java操作MySql的基本方法. 在这个示例之前,要安装好MySql,并且配置好账户密码,创建一个logininfo数据库,在数据库中创建userinfo数据表.并且在表中添加示例数据. ...
- JAVA使用jdbc连接MYSQL简单示例
以下展示的为JAVA使用jdbc连接MYSQL简单示例: import java.sql.DriverManager; import java.sql.ResultSet; import java.s ...
- Java通过JDBC 进行MySQL数据库操作
转自: http://blog.csdn.net/tobetheender/article/details/52772157 Java通过JDBC 进行MySQL数据库操作 原创 2016年10月10 ...
- java用JDBC连接MySQL数据库的详细知识点
想实现java用JDBC连接MySQL数据库.需要有几个准备工作: 1.下载Connector/J的库文件,下载Connector/J的官网地址:http://www.mysql.com/downlo ...
- java通过jdbc访问mysql,update数据返回值的思考
java通过jdbc访问mysql,update数据返回值的思考 先不说那么多,把Java代码贴出来吧. public static void main(String[] args) throws I ...
- ava基础MySQL存储过程 Java基础 JDBC连接MySQL数据库
1.MySQL存储过程 1.1.什么是存储过程 带有逻辑的sql语句:带有流程控制语句(if while)等等 的sql语句 1.2.存储过程的特点 1)执行效率非常快,存储过程是数据库的服 ...
- [原创]java使用JDBC向MySQL数据库批次插入10W条数据测试效率
使用JDBC连接MySQL数据库进行数据插入的时候,特别是大批量数据连续插入(100000),如何提高效率呢?在JDBC编程接口中Statement 有两个方法特别值得注意:通过使用addBatch( ...
- 常用JavaBean:JdbcBean codes:Java通过JDBC 连接 Mysql 数据库
package bean;import java.sql.*;import com.mysql.jdbc.PreparedStatement;public class JdbcBean { publi ...
- 【Java】JDBC连接MySQL
JDBC连接MySQL 虽然在项目中通常用ORM的框架实现持久化.但经常因测试某些技术的需要,要写一个完整的JDBC查询数据库.写一个在这儿备份. 首先引入驱动包: <dependencies& ...
随机推荐
- (转) Arcgis for js之WKT和GEOMETRY的相互转换
http://blog.csdn.net/gisshixisheng/article/details/44057453 1.wkt简介 WKT(Well-known text)是一种文本标记语言,用于 ...
- Unity的分辨率
问题: 强制设置程序运行的分辨率 解决办法: 在程序开始运行时就对分辨率进行设定 设定方法如下: void GetResolution() { int width = Screen.currentRe ...
- Leetcode 49.字母异位词分组
字母异位词分组 给定一个字符串数组,将字母异位词组合在一起.字母异位词指字母相同,但排列不同的字符串. 示例: 输入: ["eat", "tea", " ...
- RBAC(Role-Based Access Control)
http://hi.baidu.com/akini/blog/item/eddbd61b90f6d4fbae513371.html RBAC 求助编辑百科名片 基 于角色的访问控制(Role-Base ...
- [TS-A1486][2013中国国家集训队第二次作业]树[树的重心,点分治]
首先考虑暴力,可以枚举每两个点求lca进行计算,复杂度O(n^3logn),再考虑如果枚举每个点作为lca去枚举这个点的子树中的点复杂度会大幅下降,如果我们将每个点递归考虑,每次计算过这个点就把这个点 ...
- angular的又一本好书
MANNING出的<ANGULAR.JS IN ACTION>. 比上本看完的书<ANGULAR ESSENTIAL>多了一些有全局性的东东. 八个关键概念:MODULE,CO ...
- ZooKeeper是什么(转)
ZooKeeper是什么? ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件.它是一个为分布式应用提 ...
- MySQL:Useful Commands
MySQL Useful Commands Start/Stop/Restart MySQL On Linux start/stop/restart from the command line: /e ...
- Nginx配置httpsserver
配置HTTPS主机.必须在server配置块中打开SSL协议,还须要指定服务器端证书和密钥文件的位置: server { listen 443; #要加密的域名 server_name www.te ...
- Vim技巧之四大模式_普通模式
Vim技巧之四大模式_普通模式 一见不钟情的普通模式 普通模式以下的强悍操作 什么是操作符 什么是动作命令 误操作怎么办 那种操作更划算 普通模式下的神奇大招 Vim技巧之四大模式_普通模式 众所周知 ...