HttpRunnerManager 搭建使用方法
HttpRunnerManager
Design Philosophy
基于HttpRunner的接口自动化测试平台: HttpRunner, djcelery and Django_. HttpRunner手册: http://cn.httprunner.org/
Key Features
- 项目管理:新增项目、列表展示及相关操作,支持用例批量上传(标准化的HttpRunner json和yaml用例脚本)
- 模块管理:为项目新增模块,用例和配置都归属于module,module和project支持同步和异步方式
- 用例管理:分为添加config与test子功能,config定义全部变量和request等相关信息 request可以为公共参数和请求头,也可定义全部变量
- 场景管理:可以动态加载可引用的用例,跨项目、跨模快,依赖用例列表支持拖拽排序和删除
- 运行方式:可单个test,单个module,单个project,也可选择多个批量运行,支持自定义测试计划,运行时可以灵活选择配置和环境,
- 分布执行:单个用例和批量执行结果会直接在前端展示,模块和项目执行可选择为同步或者异步方式,
- 环境管理:可添加运行环境,运行用例时可以一键切换环境
- 报告查看:所有异步执行的用例均可在线查看报告,可自主命名,为空默认时间戳保存,
- 定时任务:可设置定时任务,遵循crontab表达式,可在线开启、关闭,完毕后支持邮件通知
- 持续集成:jenkins对接,开发中。。。
本地开发环境部署
安装mysql数据库服务端(推荐5.7+),并设置为utf-8编码,创建相应HttpRunner数据库,设置好相应用户名、密码,启动mysql
修改:HttpRunnerManager/HttpRunnerManager/settings.py里DATABASES字典和邮件发送账号相关配置
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'HttpRunner', # 新建数据库名
'USER': 'root', # 数据库登录名
'PASSWORD': 'lcc123456', # 数据库登录密码
'HOST': '127.0.0.1', # 数据库所在服务器ip地址
'PORT': '3306', # 监听端口 默认3306即可
}
} EMAIL_SEND_USERNAME = 'username@163.com' # 定时任务报告发送邮箱,支持163,qq,sina,企业qq邮箱等,注意需要开通smtp服务
EMAIL_SEND_PASSWORD = 'password' # 邮箱密码安装rabbitmq消息中间件,
path加入%RABBIT_HOME%\sbin RABBIT_HOME E:\Program Files\RabbitMQ Server\rabbitmq_server-3.7.8地址
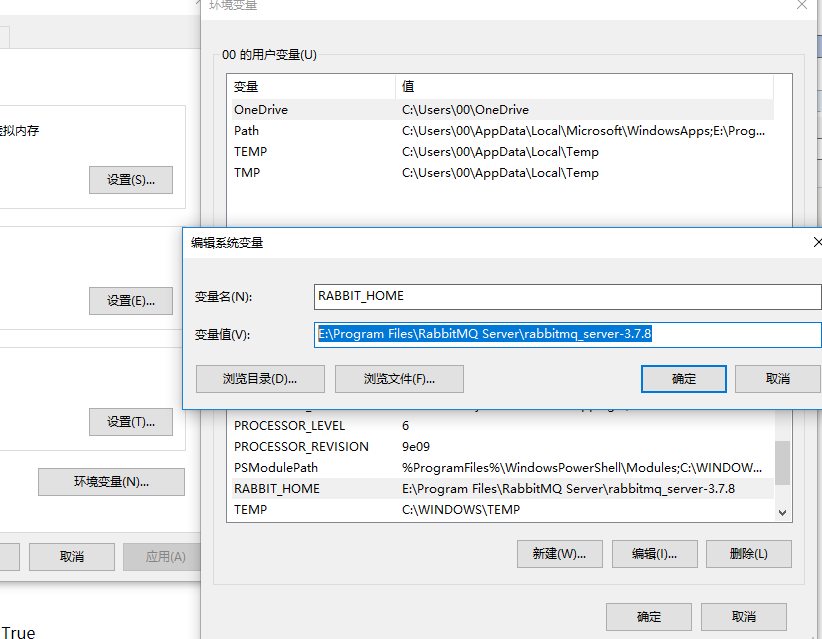
(1)运行命令行窗口cmd
- (2)输入命令rabbitmq-plugins enable rabbitmq_management
启动服务,访问:http://host:15672/#/ host即为你部署rabbitmq的服务器ip地址 username:guest、Password:guest, 成功登陆即可
service rabbitmq-server start
修改:HttpRunnerManager/HttpRunnerManager/settings.py里worker相关配置
djcelery.setup_loader()
CELERY_ENABLE_UTC = True
CELERY_TIMEZONE = 'Asia/Shanghai'
BROKER_URL = 'amqp://guest:guest@127.0.0.1:15672//' # 127.0.0.1:15672即为rabbitmq-server所在服务器ip地址
CELERYBEAT_SCHEDULER = 'djcelery.schedulers.DatabaseScheduler'
CELERY_RESULT_BACKEND = 'djcelery.backends.database:DatabaseBackend'
CELERY_ACCEPT_CONTENT = ['application/json']
CELERY_TASK_SERIALIZER = 'json'
CELERY_RESULT_SERIALIZER = 'json'
CELERY_TASK_RESULT_EXPIRES = 7200 # celery任务执行结果的超时时间,
CELERYD_CONCURRENCY = 10 # celery worker的并发数 也是命令行-c指定的数目 根据服务器配置实际更改 默认10
CELERYD_MAX_TASKS_PER_CHILD = 100 # 每个worker执行了多少任务就会死掉,我建议数量可以大一些,默认100
DEBUG = True 改成False 在C:\Users\00\Desktop\HttpRunnerManager-master\templates的base.html修改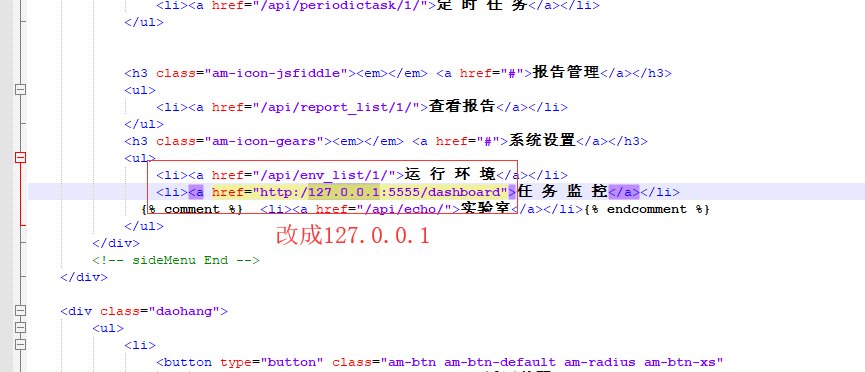
命令行窗口执行pip install -r requirements.txt 安装工程所依赖的库文件
命令行窗口切换到HttpRunnerManager目录 生成数据库迁移脚本,并生成表结构
pip install Celery
是在 Django 中, 连接数据库时使用的是 MySQLdb 库,这在与 python3 的合作中就会报以下错误django.core.exceptions.ImproperlyConfigured: Error loading MySQLdb module: No module named 'MySQLdb'
解决方法:在 __init__.py 文件中添加以下代码即可。import pymysql
pymysql.install_as_MySQLdb()cd C:\Users\00\Desktop\HttpRunnerManager-master python manage.py makemigrations ApiManager #生成数据迁移脚本
python manage.py migrate #应用到db生成数据表创建超级用户,用户后台管理数据库,并按提示输入相应用户名,密码,邮箱。 如不需用,可跳过此步骤
python manage.py createsuperuser
启动服务,
python manage.py runserver 0.0.0.0:8000
启动worker, 如果选择同步执行并确保不会使用到定时任务,那么此步骤可忽略
python manage.py celery -A HttpRunnerManager worker --loglevel=info #启动worker
python manage.py celery beat --loglevel=info #启动定时任务监听器
celery flower #启动任务监控后台访问:http://127.0.0.1:5555/dashboard 即可查看任务列表和状态
浏览器输入:http://127.0.0.1:8000/api/register/ 注册用户,开始尽情享用平台吧
浏览器输入http://127.0.0.1:8000/admin/ 输入步骤6设置的用户名、密码,登录后台运维管理系统,可后台管理数据
生产环境uwsgi+nginx部署参考:https://www.jianshu.com/p/d6f9138fab7b
新手入门手册
1、首先需要注册一个新用户,注册成功后会自动跳转到登录页面,正常登录即可访问页面 

2、登陆后默认跳转到首页,左侧为菜单栏,上排有快捷操作按钮,当前只简单的做了项目,模块,用例,配置的统计 
3、首先应该先添加一个项目,用例都是以项目为维度进行管理, 注意简要描述和其他信息可以为空, 添加成功后会自动重定向到项目列表 
4、支持对项目进行二次编辑,也可以进行筛选等,项目列表页面可以选择单个项目运行,也可以批量运行,注意:删除操作会强制删除该项目下所有数据,请谨慎操作 
5、当前项目可以新增模块了,之后用例或者配置都会归属模块下,必须指定模块所属的项目,模块列表与项目列表类似,故不赘述 
6、新增用例,遵循HtttpRuunner脚本规范,可以跨项目,跨模块引用用例,支持拖拽排序,动态添加和删减,极大地方便了场景组织, HttpRunner用例编写很灵活,建议规范下编写方式 



7、新增配置,可定义全局变量,全局hook,公共请求参数和公共headers,一般可用于测试环境,验证环境切换配置,具体用法参考HttpRunner手册 
8、支持添加项目级别定时任务,模块集合的定时任务,遵循crontab表达式, 模块列表为空默认为整个项目,定时任务支持选择环境和配置 
9、定时任务列表可以对任务进行开启或者关闭、删除,不支持二次更改 
10、用例列表运行用例可以选择单个,批量运行,鼠标悬浮到用例名称后会自动展开依赖的用例,方便预览,鼠标悬浮到对应左边序列栏会自动收缩,只能同步运行 
11、项目和模块列表可以选择单个,或者批量运行,可以选择运行环境,配置等,支持同步、异步选择,异步支持自定义报告名称,默认时间戳命名 
12、异步运行的用例还有定时任务生成的报告均会存储在数据库,可以在线点击查看,当前不提供下载功能 
13、高大上的报告(基于extentreports实现), 可以一键翻转主题哦 

其他
MockServer:https://github.com/yinquanwang/MockServer
因时间限制,平台可能还有很多潜在的bug,使用中如遇到问题,欢迎issue, 如果任何疑问好好的建议欢迎github提issue, 或者可以直接加群(628448476),反馈会比较快
HttpRunnerManager 搭建使用方法的更多相关文章
- (转)python 搭建libsvm方法。python版本和libsvm版本匹配很重要!
<集体智慧编程>关于婚介数据集的SVM分类 转自:http://muilpin.blog.163.com/blog/static/165382936201131875249123/ 作 ...
- 云计算之openstack ocata 项目搭建详细方法
之前写过一篇<openstack mitaka 配置详解>然而最近使用发现阿里不再提供m版本的源,所以最近又开始学习ocata版本,并进行总结,写下如下文档 OpenStack ocata ...
- CentOS 7.0源码包搭建LNMP方法分享(实际环境下)
CentOS 7.0编译安装Nginx1.6.0+MySQL5.6.19+PHP5.5.14 一.配置防火墙,开启80端口.3306端口 CentOS 7.0默认使用的是firewall作为防火墙,这 ...
- Docker容器版Jumpserver堡垒机搭建部署方法附Redis
1.简介 Jumpserver是全球首款完全开源的堡垒机,多云环境下更好用的堡垒机,使用GNU GPL v2.0开源协议,是符合 4A 的专业运维安全审计系统,使用Python / Django 进行 ...
- 基于Windows 7(本地)和CentOS7.6(云端)的Minecraft服务器(无Forge/有Forge)搭建方法
炎炎夏日中想和小伙伴们开黑的同学可以进来看一下了,本教程教你搭建基于两个平台的Minecraft服务器,这里我以Minecraft 1.11.2版本为例给大家讲解搭建流程.其中有Forge版本可以加入 ...
- vue.js开发环境搭建
1.安装node.js(http://www.runoob.com/nodejs/nodejs-install-setup.html) 2.基于node.js,利用淘宝npm镜像安装相关依赖 在cmd ...
- Java及Android开发环境搭建
前言 自从接触java以来,配置环境变量折腾了好几次,也几次被搞得晕头转向,后来常常是上网查阅相关资料才解决.但是过一段时间后一些细节就会记不清了,当要在其他机子上配置时又得上网查或者查阅相关书籍,如 ...
- haproxy简单负载均衡搭建
最近对负载均衡进行搭建具体方法如下: haproxy 修改部分(haproxy-cfg.cfg) global daemon maxconn 4500 defaults mode http timeo ...
- kafka学习(三)-kafka集群搭建
kafka集群搭建 下面简单的介绍一下kafka的集群搭建,单个kafka的安装更简单,下面以集群搭建为例子. 我们设置并部署有三个节点的 kafka 集合体,必须在每个节点上遵循下面的步骤来启动 k ...
随机推荐
- HDU 4525
也是水题了,不过注意负负也可以为正就好了. 今天看见bestcoder上的人那么厉害,唉,我什么时候才能赶上啊.. #include <iostream> #include <cst ...
- Lucene5学习之使用MMSeg4j分词器
分类:程序语言|标签:C|日期: 2015-05-01 02:00:24 MMSeg4j是一款中文分词器,详细介绍如下: 1.mmseg4j 用 Chih-Hao Tsai 的 MMSeg 算法( ...
- effective C++ 读书笔记 条款11
条款11: 在operator= 中处理"自我赋值" 在实现operator=时考虑自我赋值是必要的就像 x=y .我们不知道变量x与y代表的值是否为同一个值(把x和y说成是一个指 ...
- 在Win7中修改 系统盘中 “系统” - “用户” 的环境变量映射关系
1.在此列表中,选中对应登录帐号 HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\ProfileList 2.将Prof ...
- 20170322Linux
- oc62--block1
// // main.m // Block的应用场景 // typedef void (^workBlock)(); #import <Foundation/Foundation.h> / ...
- B1922 [Sdoi2010]大陆争霸 最短路
我一直都不会dij的堆优化,今天搞了一下...就是先弄一个优先队列,存每个点的数据,然后这个题就加了一点不一样的东西,每次的最短路算两次,一次是自己的最短路,另一次是机关的最短路,两者取最大值才是该点 ...
- bzoj 1800 & 洛谷 P2165 [AHOI2009]飞行棋 —— 模拟
题目:https://www.lydsy.com/JudgeOnline/problem.php?id=1800 https://www.luogu.org/problemnew/show/P21 ...
- Check the difficulty of problems(概率+DP)
http://poj.org/problem?id=2151 看的题解..表示没看懂状态转移方程.. #include<stdio.h> #include<string.h> ...
- day-05 python函数
# #-*- coding:utf-8 -*-# 1:编写一个名为 make_shirt()的函数,它接受一个尺码以及要印到 T 恤上的字样.这个函数应打印一个句子,概要地说明 T 恤的尺码和字样.d ...