SQL Server跨库跨服务器访问实现
我们经常会遇到一个数据库要访问另一个数据库,或者一台服务器要访问另一台服务器里面的数据库。 那么这个如何实现的呢? 相信看完这篇文章你就懂了!
同一台服务器跨库访问实现
1. 首先创建两个数据库CrossLibraryTable1,CrossLibraryTable2
--创建CrossLibraryTable1脚本:
go
if exists (select * from sysdatabases where name='CrossLibraryTable1')
drop database CrossLibraryTable1 /*检查有没有这个数据库,如果有就删除它。*/
go
create database CrossLibraryTable1
on primary
(
name='CrossLibraryTable1_data', ------------ 养成好习惯,数据文件加_data
filename='F:\代码存放\数据库\CrossLibraryTable1_data.mdf', ------------ 一定要是.mdf的文件,代表主数据文件
size=5mb, --默认数据库大小
maxsize=100mb, --最大容量
filegrowth=1mb --增长量
)
log on
(
name='CrossLibraryTable1_log', ------------ 养成好习惯,日志文件加_log
filename='F:\代码存放\数据库\CrossLibraryTable1_log.ldf', ------------ 一定要是.ldf的文件,代表日志文件
size=1mb, --默认数据库大小
filegrowth=10% --增长量
)
--创建CrossLibraryTable2脚本:
go
if exists (select * from sysdatabases where name='CrossLibraryTable2')
drop database CrossLibraryTable2 /*检查有没有这个数据库,如果有就删除它。*/
go
create database CrossLibraryTable2
on primary
(
name='CrossLibraryTable2_data', ------------ 养成好习惯,数据文件加_data
filename='F:\代码存放\数据库\CrossLibraryTable2_data.mdf', ------------ 一定要是.mdf的文件,代表主数据文件
size=5mb, --默认数据库大小
maxsize=100mb, --最大容量
filegrowth=1mb --增长量
)
log on
(
name='CrossLibraryTable2_log', ------------ 养成好习惯,日志文件加_log
filename='F:\代码存放\数据库\CrossLibraryTable2_log.ldf', ------------ 一定要是.ldf的文件,代表日志文件
size=1mb, --默认数据库大小
filegrowth=10% --增长量
)
然后,执行完脚本后,刷新一下就可以看到刚刚创建的数据库了:

2.接下来在两个数据库里面分别创建一个CrossTest1和一个CrossTest2表用于跨库查询
--创建CrossTest1脚本:
use CrossLibraryTable1
create table CrossTest1(
Id int primary key identity,
Name nvarchar(20)
)
--创建CrossTest2脚本:
use CrossLibraryTable2
create table CrossTest2(
Id int primary key identity,
Name nvarchar(20)
)
表创建好后,我们再添加几条数据进去:
use CrossLibraryTable1
insert into CrossTest1 values('跨库1测试数据1')
insert into CrossTest1 values('跨库1测试数据2') use CrossLibraryTable2
insert into CrossTest2 values('跨库2测试数据1')
insert into CrossTest2 values('跨库2测试数据2')
切换到CrossLibraryTable1下面查询CrossLibraryTable2的数据可以看到报如下错误
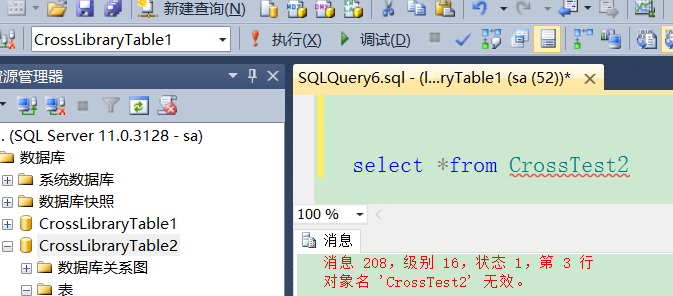
修正代码:
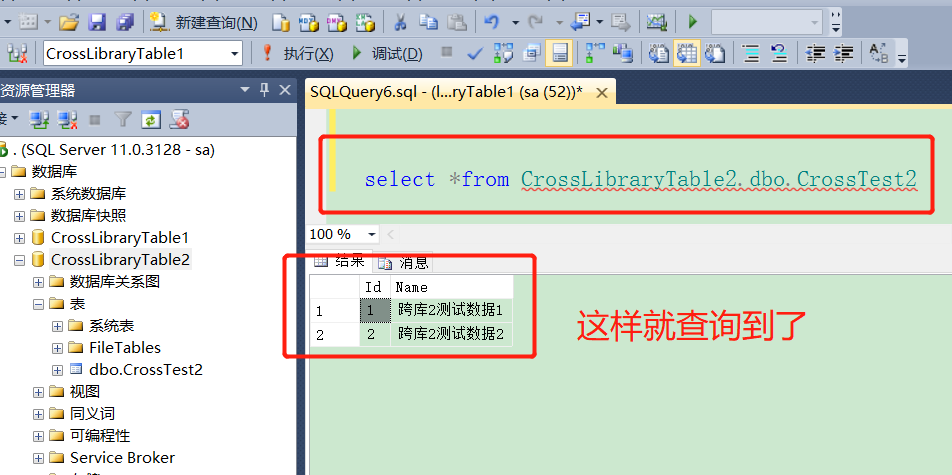
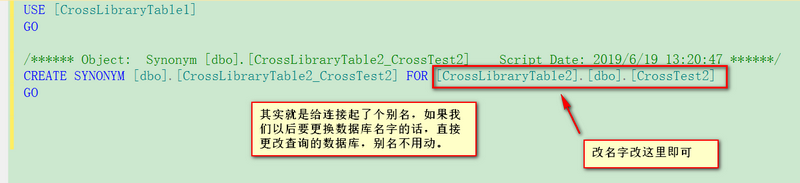
PS:像上面那样是可以进行查询,然而在项目中使用上面的代码格式就会引发一些问题,那什么问题呢?比如另一个数据库的名称改变了,我们就需要把所有用到这个的地方都得改掉,这样就很麻烦,那么有什么解决方案么,使得改一处就好了?当然有,用数据库同义词就可以轻松搞定!
创建同义词步骤如下:


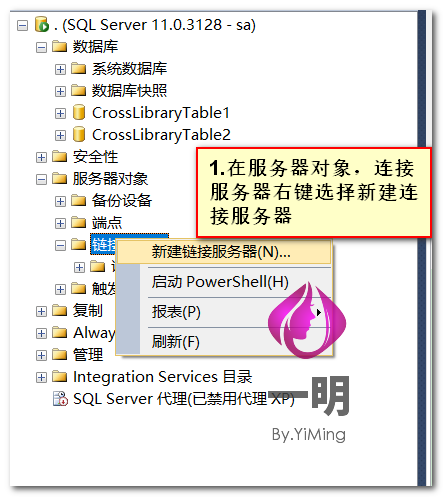
不同服务器跨库访问实现
当数据库在不同服务器上面,用上面的方法就不行了,那如何实现跨服务器访问呢?很简单,看下面↓↓↓
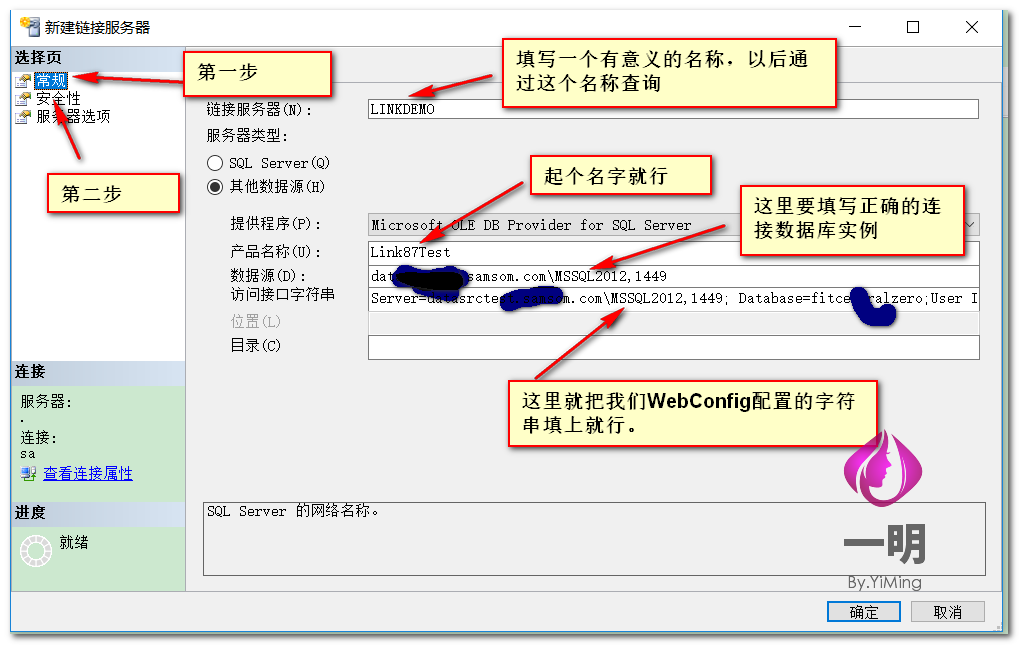
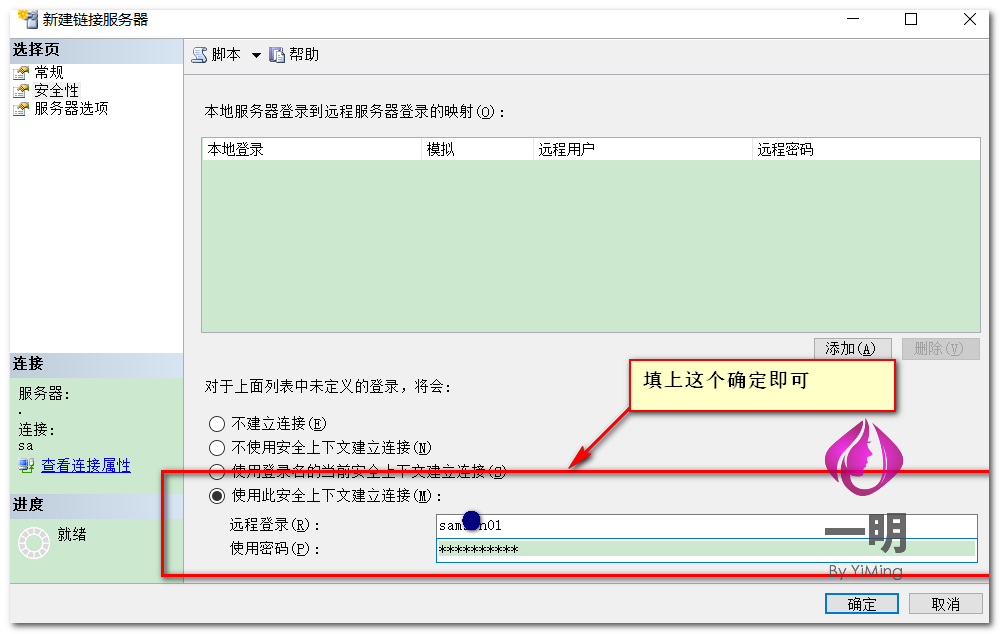
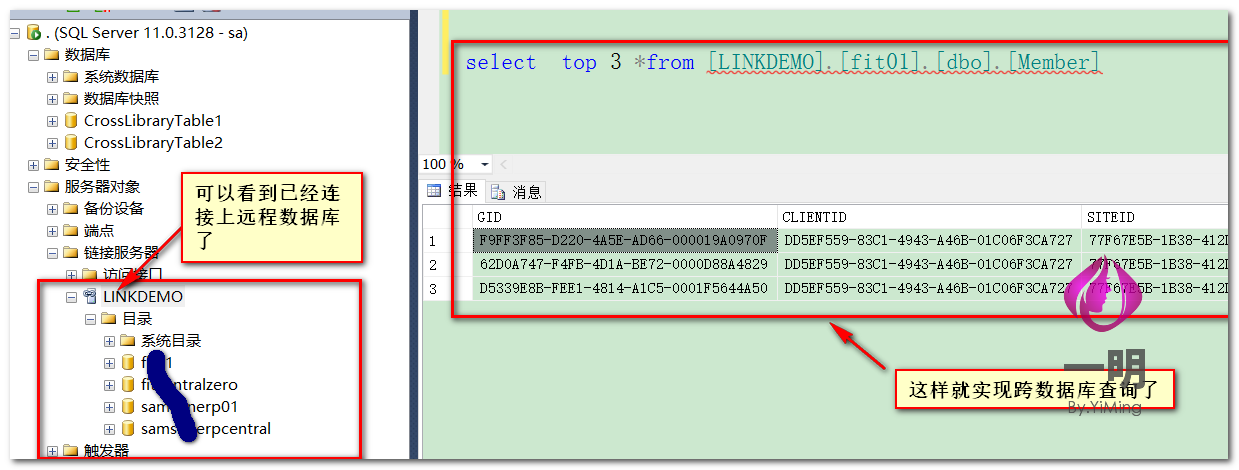
好了,SQL Server跨库跨服务器访问实现就到这了,如果按照步骤一步一步操作的话,相信您也已经实现了,下一篇文章就来谈谈分库分表实现。
SQL Server跨库跨服务器访问实现的更多相关文章
- sql server 数据库创建链接服务器访问另外一个sql server 数据库
继上篇在sql server中创建链接服务器访问oracle数据库:http://www.cnblogs.com/527289276qq/p/4770379.html 本文介绍在sql server中 ...
- sql server中使用链接服务器访问oracle数据库
一. 安装配置oracle客户端 要访问orcale数据,必须在访问的客户端机器上安装oracle客户端. Orcale有两种形式的客户端: l 完整的客户端 包括访问服务器端数据库 ...
- sql server 数据库创建链接服务器
本文介绍在sql server中创建链接服务器访问sql server数据库. 方法: 打开SSMS,新建程序,执行下面sql语句块: EXEC sp_addlinkedserver @server= ...
- SQL Server 中的跨库视图
SQL Server 中的跨库视图 在一个SQL中,有多个数据库,A.B.C,在使用C为连接库中,现在要查询A中的表T1. 那么,在C中建创视图(A_T1). SELECT *FROM A.dbo.T ...
- 【转】SQL Server -- 已成功与服务器建立连接,但是在登录过程中发生错误
SQL Server -- 已成功与服务器建立连接,但是在登录过程中发生错误 最近在VS2013上连接远程数据库时,突然连接不上,在跑MSTest下跑的时候,QTAgent32 crash.换成IIS ...
- 64位sql server 如何使用链接服务器连接Access
原文:64位sql server 如何使用链接服务器连接Access 测试环境 操作系统版本:Windows Server 2008 r2 64位 数据库版本:Sql Server 2005 64位 ...
- sql server登录名、服务器角色、数据库用户、数据库角色、架构区别联系
原创链接:https://www.cnblogs.com/lxf1117/p/6762315.html sql server登录名.服务器角色.数据库用户.数据库角色.架构区别联系 1.一个数据库用户 ...
- Razor视图引擎布局 Razor视图引擎的基本概念与法语 SQL Server Mobile 和 .NET 数据访问接口之间的数据类型映射 binary 和 varbinary datetime 和 smalldatetime float 和 real
Razor视图引擎布局 不需要像过去aspx一样,使用.Master文件,而是统一使用.cshtml 或 .vbhtml文件.但文件名一般以 _开头,这样做文件不会当做View显示出来 使用@Re ...
- SQL Server 无法连接到服务器。SQL Server 复制需要有实际的服务器名称才能连接到服务器。请指定实际的服务器名称。
异常处理汇总-数据库系列 http://www.cnblogs.com/dunitian/p/4522990.html SQL性能优化汇总篇:http://www.cnblogs.com/dunit ...
随机推荐
- HDU - 5894 Pocky(概率)
HDU5894—Pocky Problem Description: Let’s talking about something of eating a pocky. Here is a Decore ...
- 【模板】求1~n的整数的乘法逆元
洛谷3811 先用n!p-2求出n!的乘法逆元 因为有(i-1)!-1=i!-1*i (mod p),于是我们可以O(n)求出i!-1 再用i!-1*(i-1)!=i-1 (mod p)即是答案 #i ...
- 《ABCD组》第八次作业:ALPHA冲刺
<ABCD组>第八次作业:ALPHA冲刺 项目 内容 这个作业属于哪个课程 http://www.cnblogs.com/nwnu-daizh/ 这个作业的要求在哪里 https://ww ...
- 【codeforces 785E】Anton and Permutation
[题目链接]:http://codeforces.com/problemset/problem/785/E [题意] 给你一个初始序列1..n顺序 然后每次让你交换任意两个位置上面的数字; 让你实时输 ...
- CTF中编码与加解密总结
CTF中那些脑洞大开的编码和加密 转自:https://www.cnblogs.com/mq0036/p/6544055.html 0x00 前言 正文开始之前先闲扯几句吧,玩CTF的小伙伴也许会遇到 ...
- hdu_1859_最小长方形_201402282048
最小长方形 Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total Submi ...
- [bzoj4282]慎二的随机数列_动态规划_贪心
慎二的随机数列 bzoj-4282 题目大意:一个序列,序列上有一些数是给定的,而有一些位置上的数可以任意选择.问最长上升子序列. 注释:$1\le n\le 10^5$. 想法:结论:逢N必选.N是 ...
- Ubuntu下调整时区时间
Ubuntu下调整时区时间 学习了:http://blog.csdn.net/jintiaozhuang/article/details/38583031 进行了tzselect错误的修复 学习了:h ...
- STL在迭代的过程中,删除指定的元素
直接上Code,上 Picture #include <iostream> #include <list> using namespace std; // STL在迭代的过程中 ...
- 利用keepalive和timeout来推断死连接
问题是这样出现的. 操作:client正在向服务端请求数据的时候,突然拔掉client的网线. 现象:client死等.服务端socket一直存在. 在网上搜索后,须要设置KEEPALIVE属性. 于 ...