学习笔记:分布式日志收集框架Flume
- 业务现状分析
- WebServer/ApplicationServer分散在各个机器上,想在大数据平台hadoop上进行统计分析,就需要先把日志收集到hadoop平台上。
- 思考:如何解决我们的数据从其他的server上移动到Hadoop之上?
- 脚本shell,用cp拷贝到hadoop集群上,再通过hadoop fs -put xxxx存储到hdfs上,但是这种方式会有如下问题:
- 如何做监控?如果拷贝过程中某台机器断掉了怎么做到很好的监控?
- 采用cp方式,需要设定一个复制的间隔时间,这样做时效性如何?
- log一般存为txt文本文件,如果把文本格式的数据直接通过网络传输,对i/o的开销很大
- 如何做负载均衡,压缩等等
- 脚本shell,用cp拷贝到hadoop集群上,再通过hadoop fs -put xxxx存储到hdfs上,但是这种方式会有如下问题:
- Flume概述
- Flume is a distributed, reliable, and available service for efficiently collecting(收集), aggregating(聚合), and moving(移动) large amounts of log data. It has a simple and flexible architecture based on streaming data flows. It is robust and fault tolerant with tunable reliability mechanisms and many failover and recovery mechanisms. It uses a simple extensible data model that allows for online analytic application.
- Flume设计目标:可靠性,扩展性,管理性
- 业界同类产品的对比
- Flume:Cloudera/Apache java
- Scribe:Facebook c/c++ 不再维护
- Chuka:Yahoo/Apache java 不再维护
- kafka:
- Fluentd:Ruby
- Logstash:ELK
- Flume架构及核心组件
-
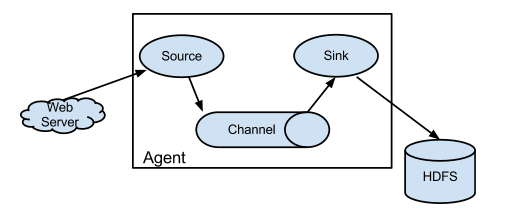
- Source :收集,常用的Source:Avro Source,Exce Source,Spooling,NetCat TCP Source,Kafka Source
- Channel : 聚集,常用的Channels:Memory Channels,File Channels,Kafka Channels
- Sink :输出,常用的Sink:HDFS Sink,Hive Sink,Logger Sink,Avro Sink,Hbase,Kafka
- 设置multi-agent flow(可参看官网)
-
- Flume环境搭建
- 安装JDK
- 安装Flume
- Flume实战案例
- 案例一的需求:从指定网络端口采集数据输出到控制台
# example.conf: A single-node Flume configuration #使用Flume的关键就是写配置文件
#配置Source
#配置Channel
#配置Sink
#把以上三个组件串起来
#a1:agent名称;r1:source名称;k1:sink名称;c1:channels的名称
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1 # Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = # Describe the sink
a1.sinks.k1.type = logger # Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity =
a1.channels.c1.transactionCapacity = # Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1启动agent:
bin/flume-ng agent --name a1 -c $FLUME_HOME/conf --conf-file xxx(刚刚定义的example.conf) -Dflume.root.logger=INFO,consol
- 案例二的需求:监控一个文件实时采集新增的数据输出到控制台
#agent选型:exec source + memory channel + logger sink
#文件名:exec-memory-logger.conf a1.sources = r1
a1.sinks = k1
a1.channels = c1 a1.sources.r1.type = exec
a1.sources.r1.command= tail -F /home/hadoop/data.log#要监控的文件 a1.sinks.k1.type = logger a1.channels.c1.type = memory # Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1启动agent命令同上:
bin/flume-ng agent --name a1 -c $FLUME_HOME/conf --conf-file exec-memory-logger.conf
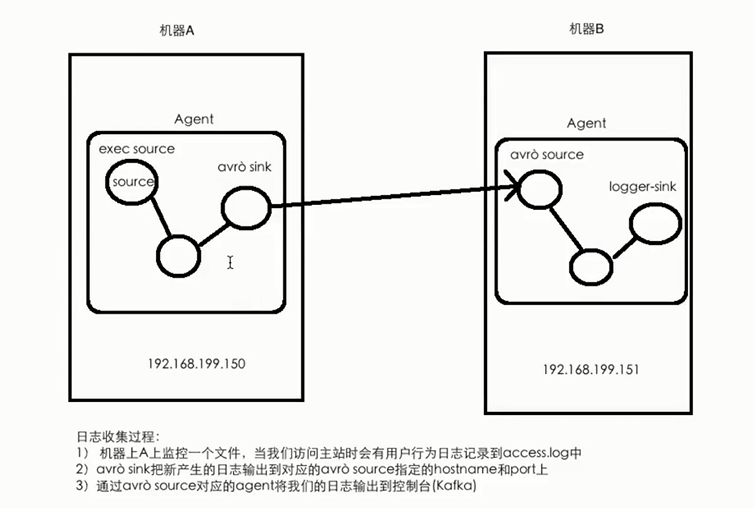
- 案例三的需求:将A服务器上的日志实时采集到B服务器上
#技术选型:
#exec source + memory channel + avro sink
#avro source + menory channel + logger sink #第一个conf文件内容如下:exec-memry-avro.conf
exec-memory-avro.source = exec-source
exec-memory-avro.sink = avro-sink
exec-memory-avro.channels = memory-channel exec-memory-avro.sources.exec-source.type=exec
exec-memory-avro.sources.exec-source.command=tail - F /home/hadoop/data.log exec-memory-avro.sinks.avro-sink.type=avro
exec-memory-avro.sinks.avro-sink.hostname=hadoop000
exec-memory-avro.sinks.avro-sink.port= exec-memory-avro.channels.memory-channel.type = memory exec-memory-avro.source.exec-memory.channels=memory-channel
exex-memory-avro.sinks.avro-sinks.channel = memory-channel #第二个conf文件内容如下:avro-memory-logger.conf
avro-memory-logger.source = avro-source
avro-memory-logger.sink = logger-sink
avro-memory-logger.channels = memory-channel avro-memory-logger.source.exec-source.type=avro
avro-memory-logger.source.exec-source.bind=hadoop000
avro-memory-logger.source.exec-source.port= avro-memory-logger.sinks.logger-sink.type=logger avro-memory-logger.channels.memory-channel.type = memory avro-memory-logger.source.avro-memory.channels=memory-channel
avro-memory-logger.sinks.logger-sinks.channel = memory-channel启动两个对应的conf文件:
bin/flume-ng agent --name avro-memory-logger -c $FLUME_HOME/conf --conf-file avro-memory-logger.conf
bin/flume-ng agent --name exec-memory-logger -c $FLUME_HOME/conf --conf-file exec-memory-logger.conf
- 案例一的需求:从指定网络端口采集数据输出到控制台
学习笔记:分布式日志收集框架Flume的更多相关文章
- 分布式日志收集框架Flume
分布式日志收集框架Flume 1.业务现状分析 WebServer/ApplicationServer分散在各个机器上 想在大数据平台Hadoop进行统计分析 日志如何收集到Hadoop平台上 解决方 ...
- 在.NET Core中使用Exceptionless分布式日志收集框架
一.Exceptionless简介 Exceptionless 是一个开源的实时的日志收集框架,它可以应用在基于 ASP.NET,ASP.NET Core,Web Api,Web Forms,WPF, ...
- 分布式日志收集系统 —— Flume
一.Flume简介 Apache Flume 是一个分布式,高可用的数据收集系统.它可以从不同的数据源收集数据,经过聚合后发送到存储系统中,通常用于日志数据的收集.Flume 分为 NG 和 OG ( ...
- 日志收集框架flume的安装及简单使用
flume介绍 Flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统. Flume可以采集文件,socket数据包等各种形式源数据,又可以将采集到的数据输出到HDFS.hbase.h ...
- 分布式日志收集之Logstash 笔记(一)
(一)logstash是什么? logstash是一种分布式日志收集框架,开发语言是JRuby,当然是为了与Java平台对接,不过与Ruby语法兼容良好,非常简洁强大,经常与ElasticSearch ...
- asp.Net Core免费开源分布式异常日志收集框架Exceptionless安装配置以及简单使用图文教程
最近在学习张善友老师的NanoFabric 框架的时了解到Exceptionless : https://exceptionless.com/ !因此学习了一下这个开源框架!下面对Exceptionl ...
- C#实现多级子目录Zip压缩解压实例 NET4.6下的UTC时间转换 [译]ASP.NET Core Web API 中使用Oracle数据库和Dapper看这篇就够了 asp.Net Core免费开源分布式异常日志收集框架Exceptionless安装配置以及简单使用图文教程 asp.net core异步进行新增操作并且需要判断某些字段是否重复的三种解决方案 .NET Core开发日志
C#实现多级子目录Zip压缩解压实例 参考 https://blog.csdn.net/lki_suidongdong/article/details/20942977 重点: 实现多级子目录的压缩, ...
- Net Core免费开源分布式异常日志收集框架Exceptionless
asp.Net Core免费开源分布式异常日志收集框架Exceptionless安装配置以及简单使用图文教程 https://www.cnblogs.com/yilezhu/p/9193723.htm ...
- 【转】asp.Net Core免费开源分布式异常日志收集框架Exceptionless安装配置以及简单使用图文教程
最近在学习张善友老师的NanoFabric 框架的时了解到Exceptionless : https://exceptionless.com/ !因此学习了一下这个开源框架!下面对Exceptionl ...
随机推荐
- iOS 底层解析weak的实现原理(包含weak对象的初始化,引用,释放的分析)
原文 很少有人知道weak表其实是一个hash(哈希)表,Key是所指对象的地址,Value是weak指针的地址数组.更多人的人只是知道weak是弱引用,所引用对象的计数器不会加一,并在引用对象被释放 ...
- AngelToken揭秘区块链之四大链
区块链,有着各种不同,与之相对应的就是内涵和功能.在区块链领域经常出现的四大链有:公有链.私有链.联盟链.许可链,这些链又分别可以为区块链干什么呢? 公有链(Public Blockchain) 是指 ...
- NullPointerException空指针异常——没有事先加载布局文件到acitivy——缺少:setContentView(R.layout.activity_setup_over);
空指针异常: 04-27 01:13:57.270: E/AndroidRuntime(4942): FATAL EXCEPTION: main04-27 01:13:57.270: E/Androi ...
- 解决MyEclipse启动慢,使用卡顿问题
卡顿原因: 1.启动的服务和插件过多,导致启动和运行缓慢,电脑配置较差的直接会卡死没有响应 2.软件运行内存设置不足,导致没有足够的空间运行软件,致使软件卡顿 解决方法: windows --> ...
- 5ci
- docker开发实践
一:docker的定义和使用场景: Docker是一个开源的引擎,可以轻松的为任何应用创建一个轻量级的.可移植的.自给自足的容器.开发者在笔记本上编译测试通过的容器可以批量地在生产环境中部署,包括VM ...
- 我只想要Linux的IP地址
大家都知道ifconfig 可以查看centos的ip地址,但是我如果只要ip地址该怎么办呢?首先上ifconfig [root@centos ~]# ifconfig eth0 eth0 Link ...
- windows+nginx负载测试
系统:windows2003nginx版本:1.7.3(官方推荐版本 #父节点 http upstream cluster_1{ ip_hash;#能较好地把同一个客户端的多次请求分配到同一台服务器处 ...
- quartz任务调度框架与spring整合
Quartz是什么? Quartz 是一种功能丰富的,开放源码的作业调度库,可以在几乎任何Java应用程序集成 - 从最小的独立的应用程序到规模最大电子商务系统.Quartz可以用来创建简单或复杂的日 ...
- left join on 后and 和 where 的区别
SELECT * FROM student a LEFT JOIN sc b ON a.Sid = b.Sid AND a.Sname="赵雷" 结果:(left join 左连接 ...