正如上篇博文所说,在本节我将为大家带来StoreFlusher.finalizeWriter。。如果大家没有看过我的上篇博文《HBase之CF持久化系列(续1)》,那我希望大家还是回去看一下,要不然本节的很多内容大家可能看不懂。闲话不说,让我们来到正文。
首先来到方法StoreFlusher.finalizeWriter,如下图所示。
1.这里的入参writer不知道大家是否还记得,他就是在上一节中构建的StoreFileWriter。这里调用了writer.appendMetadata,将一些信息放入HFileWriterImpl.fileInfo。这里虽然不是很复杂,但从整体考虑,我还是会简单介绍一下。
2.然后调用了StoreFileWriter.close。在该方法内部,继续调用了成员变量writer.close方法(HFile.Writer)。该方法完成了文件目录结构的组成,作为本节的重点,我将在后面详细讲解。其实,HFileWriterImpl.close方法的调用,我在博文《HBase数据持久化之HRegion.flushcache即CF持久化》中已经介绍的比较简单,但是,在本节我会就该方法详细分析。


首先,我们来到方法StoreFileWriter.appendMetadata。这里的writer类型为HFileWriterImpl。
1.在HFileWriterImpl.appendFileInfo方法中调用了fileInfo.append,这里成员变量fileInfo的实际类型为HFile.FileInfo。
2.在HFile.FileInfo.append中调用了put方法,将入参作为key、value置于其成员变量map中。该map实际类型为SortedMap。
关于StoreFileWriter.appendMetadata的流程,我就简单介绍到这里,接下来我们来了解本节的重点StoreFileWriter.close。

在StoreFileWriter.close方法中主要调用了HFileWriterImpl.close。这个方法在博文《HBase数据持久化之HRegion.flushcache即CF持久化》中也简单介绍过。不过,在本节,我将详细介绍该方法的每一个知识点。
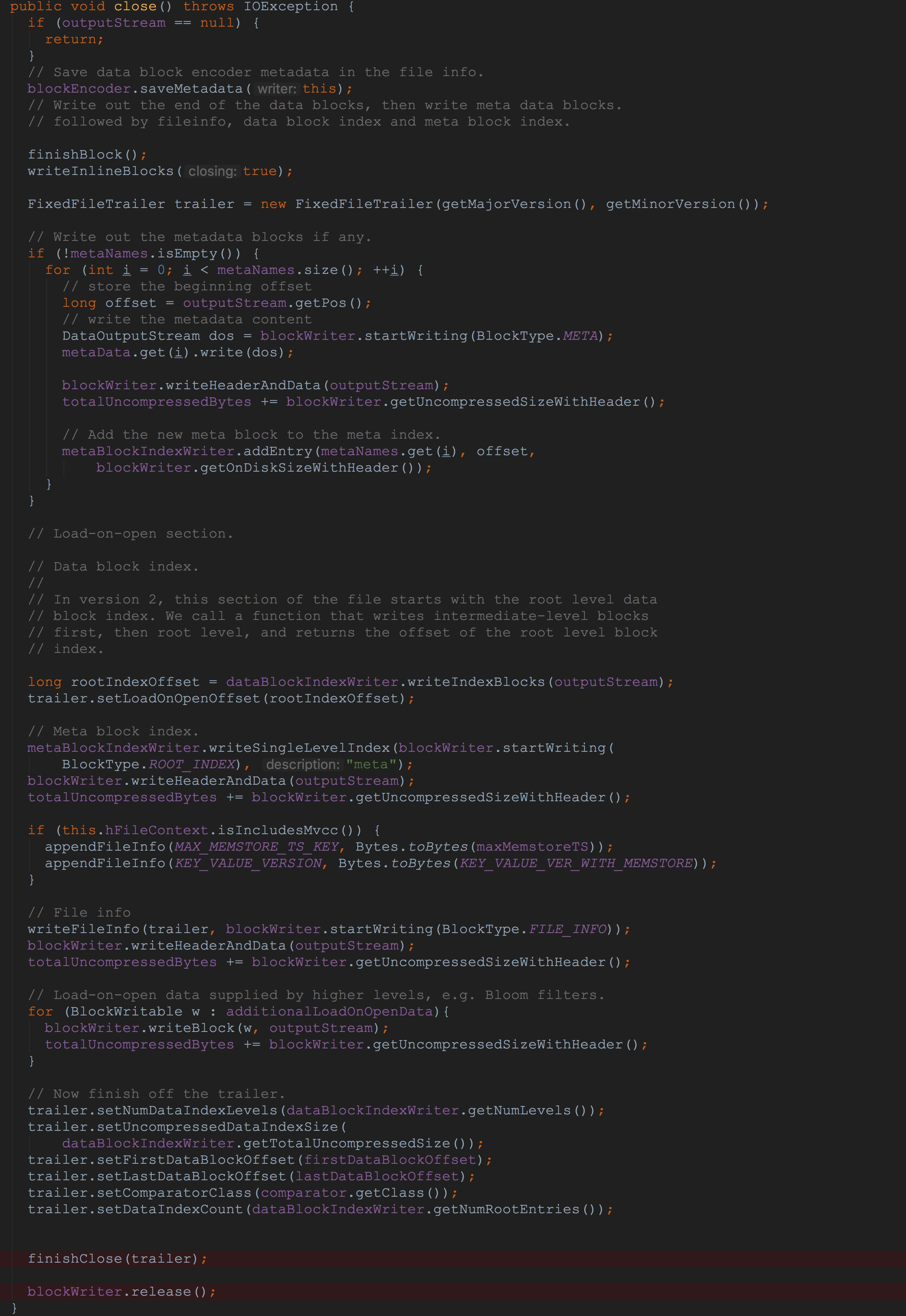
让我们来到方法HFileWriterImpl.close,如下图所示。
1.调用了blockEncoder.saveMetadata,这里的blockEncoder实际类型为NoOpDataBlockEncoder,而在NoOpDataBlockEncoder.saveMetadata方法中实现为空。
2.调用了方法finishBlock,该方法完成了成员变量blockWriter中的数据写入成员变量outputStream中,这里的outputStream就是在第一节中提到的通过反射机制调用DistributedFileSystem.create获得的文件输出流。并且,将获得的midPoint加入到dataBlockIndexWriter中,以便后期写入。
3.调用writeInlineBlocks方法,遍历成员变量inlineBlockWriters,将部分InlineBlockWriter中的信息写到成员变量outputStream中。由于这里的成员变量inlineBlockWriters中的数据比较少,而且,在后面的调用流程中也比较重要,因此,我在这里做简单讲解一下。
这里的成员变量inlineBlockWriters中一共有三个成员。首先是在HFileWriterImpl的构造方法中调用的finishInit中,在该方法内dataBlockIndexWriter被加入到inlineBlockWriters中。然后在StoreFileWriter的构造方法中初始化成员变量generalBloomFilterWriter中调用了BloomFilterFactory.createGeneralBloomAtWrite,该方法的最后一个入参是成员变量writer,也就是HFileWriterImpl。在该方法内部的最后,调用了writer.addInlineBlockWriter,将刚刚构造的CompoundBloomFilterWriter加入到writer的成员变量inlineBlockWriters中。然后,在StoreFileWriter的构造方法中初始化成员变量deleteFamilyBloomFilterWriter中调用了BloomFilterFactory.createGeneralBloomAtWrite,同样,将构造的CompoundBloomFilterWriter加入到writer的成员变量inlineBlockWriters中。
4.构造FixedFileTrailer,为了后面将信息塞入到FixedFileTrailer中。
5.由于常规的调用流程中方法metaNames.isEmpty()的返回值为true,因此,这里的循环我就不介绍了。
6.调用dataBlockIndexWriter.writeIndexBlocks将dataBlockIndexWriter中的信息写入到成员变量outputStream中。
7.调用方法metaBlockIndexWriter.writeSingleLevelIndex,
8.紧接着调用blockWriter.writeHeaderAndData,将上面写入到blockWriter.userDataStream中的数据写入到成员变量outputStream中。
9.将文件信息写入到blockWriter.userDataStream中,其内部调用了方法fileInfo.write。
10.紧接着调用blockWriter.writeHeaderAndData,将上面写入到blockWriter.userDataStream中的数据写入到成员变量outputStream中。
11.遍历additionalLoadOnOpenData,并且将其中的信息写入到成员变量outputStream中。
12.调用finishClose,其内部继续完善了trailer中的信息,然后调用trailer.serialize将trailer中的信息写入到成员变量outputStream中。
从上面的分析中,相信大家都明白了什么。没错,这里的流程就是首先将数据写入到blockWriter.userDataStream然后写入到成员变量outputStream中,这也是我在本节中的关键流程。

首先,让我们来到方法finishBlock。看过前面的大家应该都知道了。前面已经将cell信息添加到了HFileBlock.Writer.userDataStream或者说HFileBlock.Writer.baosInMemory。接下来就是如何将cell信息添加到HFileWriterImpl.outputStream中。
1.调用blockWriter.writeHeaderAndData将cell信息写入到HFileWriterImpl.outputStream中。
2.调用getMidpoint获得用于索引的cell的key
3.调用dataBlockIndexWriter.addEntry将索引信息添加到HFileBlockIndex.BlockIndexWriter的成员变量curInlineChunk中

接下来,让我们来到blockWriter.writeHeaderAndData,也就是HFileBlock.Writer.writeHeaderAndData,该方法比较简单,调用了方法finishBlockAndWriteHeaderAndData,该方法虽然简单,但还是值得一提。如下图所示。
1.调用了ensureBlockReady,将之前写入到HFileBlock.Writer.baosInMemory中的数据以及header写入到成员变量onDiskBlockBytesWithHeader中
2.调用out.write将onDiskBlockBytesWithHeader中的数据写入到输出流out中
3.调用out.write将onDiskChecksum中的数据写入到输出流out中
大家看都这里可能会有点模糊,没有关系,耐心看下去,我会在后面画图标示文件中存放的各类信息。

让我们来到ensureBlockReady,该方法调用了finishBlock,完成了将成员变量baosInMemory中的数据以及header写入到成员变量onDiskBlockBytesWithHeader
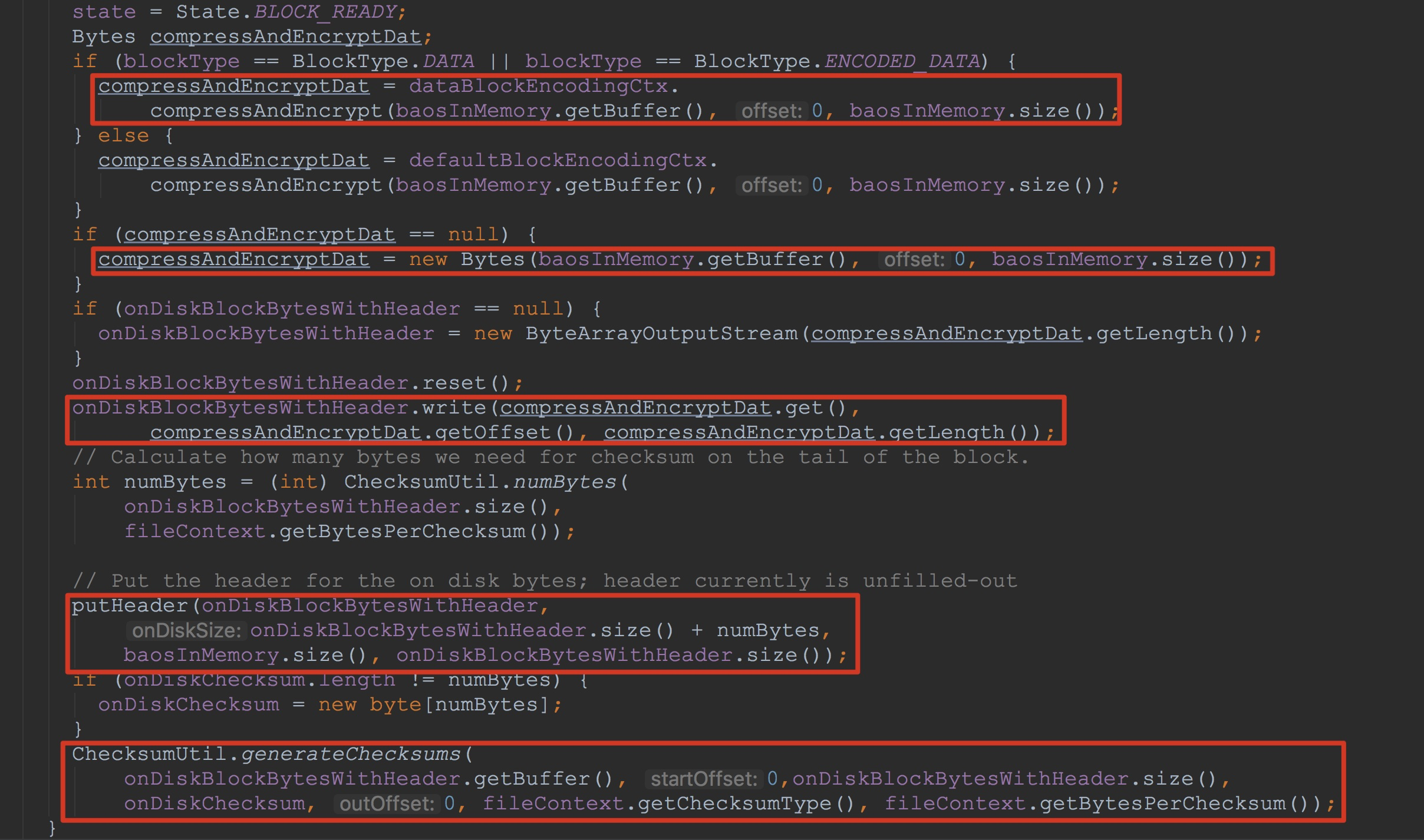
让我们通过代码来详细分析。这里,为了将finishBlock方法中的重点标示出来,我只截了该方法的重点片段。如下图所示。
1.调用dataBlockEncodingCtx.compressAndEncrypt,由于我们在默认情况下的为不加密的,因此,这里的返回为null。
2.将baosInMemory中的信息封装到Bytes中,然后赋给变量compressAndEncryptDat
3.重置onDiskBlockBytesWithHeader,避免上一次的写入对该次写入造成影响。接着调用onDiskBlockBytesWithHeader.write方法将上面刚刚初始化好的compressAndEncryptDat中的值写到其内部的成员变量buf中。
4.接下来调用putHeader方法,将onDiskBlockBytesWithHeader中的前33个字节,也就是存放header的位置填充(这些字节一开始是空置的,这一点在前一篇博文中提到过)。
5.为onDiskBlockBytesWithHeader中的所有数据生成校验和,然后校验并写入到onDiskChecksum中。
至于这里的onDiskBlockBytesWithHeader,如果在第一次调用的话,这里会将成员变量初始化,以后的话,之后调用其reset方法以实现重用。至于其使用的字节数不够存放的情况,在其write方法中会实现重新分配。
到此为止,finishBlock的完整流程就完毕了。简单地总结一下,其主要实现了两个功能:1.将成员变量blockWriter中的数据写入到成员变量outputStream中。2.将其中的索引添加到成员变量dataBlockIndexWriter中。
接下来,让我们来到方法writeInlineBlocks。如下图所示。关于成员变量inlineBlockWriters中的的三个成员我在上面已经介绍过了。其中的三个成员有两种类型,一种是HFileBlockIndex.BlockIndexWriter,另外一种便是CompoundBloomFilterWriter。

这里,我们首先来看第一种情况,也就是类型为HFileBlockIndex.BlockIndexWriter。如下图所示。这里比较简单,1.将成员curInlineChunk的值赋给成员变量rootChunk。2.将成员变量curInlineChunk置空。这也是为了将后面的索引块的写入。由于这里默认返回为false,因此,后面的流程我在这里就不介绍了。其实后面的几部我在后面也会介绍到。

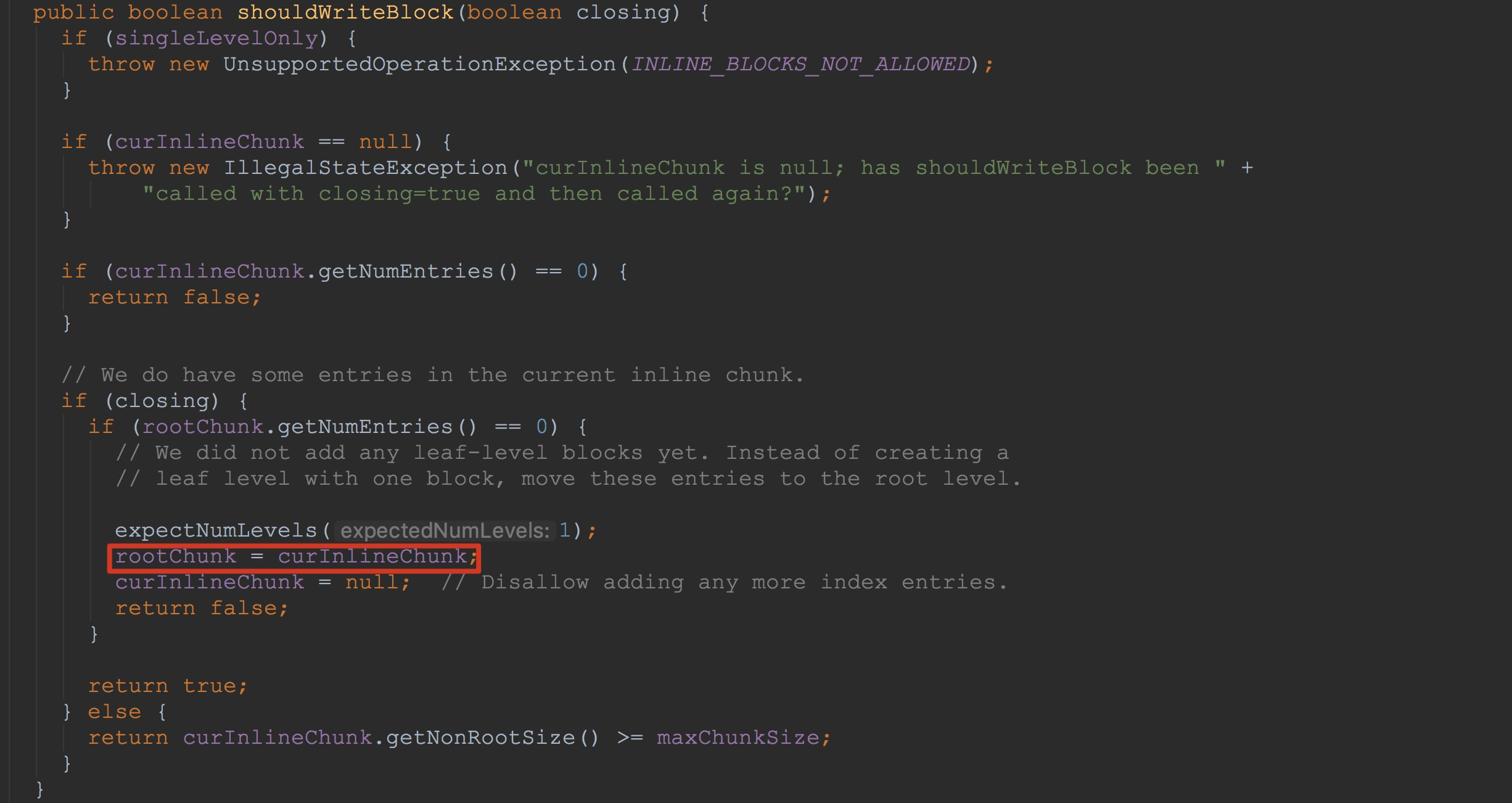
然后,让我们来到CompoundBloomFilterWriter。首先来看一下方法CompoundBloomFilterWriter.shouldWriteBlock。这里只是简单的调用了方法enqueueReadyChunk,然后调用方法readyChunks.isEmpty判断成员变量readyChunks是否为空。

接下来,让我们来看一下方法enqueueReadyChunk。如下图所示。
1.构建一个ReadyChunk用于存放存放当前chunk信息
2.将有关信息放入到刚刚构建的ReadyChunk中
3.将存储chunk信息的ReadyChunk放入到成员变量readyChunks中
4.将部分成员变量置空

在上面我已经介绍过,这里主要有两个CompoundBloomFilterWriter(这里我们就回到了StoreFileWriter类中)。看过上一节的大家应该都知道,在成员变量bloomContext中存放的generalBloomFilterWriter在调用StoreFileWriter.append将cell信息写入到了chunk中。而在另一个中并没有。因此,在写入generalBloomFilterWriter的情况下,这里的返回值为true。
接着,调用了方法CompoundBloomFilterWriter.writeInlineBlock。
1.将readyChunks队列中的header值取出,注意,这里并没有移除。
2.调用BloomFilterChunk.writeBloom方法,将存放在其中的信息写入到out流中。
在该方法后面,紧接着调用了blockWriter.writeHeaderAndData,将数据写出到了成员变量outputStream中。
然后调用了CompoundBloomFilterWriter.blockWritten。这里相对复杂,我在接下来讲解。

让我们来到方法CompoundBloomFilterWriter.blockWritten。如下图所示。这里将readyChunks队列中的header移除,并且,将其成员firstKey加入到内部成员变量bloomBlockIndexWriter中。

到此为止。这里的writeInlineBlocks就讲解完成了。
接下来构造了FFT,也就是FixedFileTrailer。
我们继续将流程往下推进,接下来就来到了方法dataBlockIndexWriter.writeIndexBlocks。如下图所示。这里的方法比较长,为了突出重点,我只截取了其中比较重要的地方。
首先,大家需要记得这里返回值rootLevelIndexPos(由于我这里只含root level的情况),这里是即将写入root level是的位置。
大家是否还记得上面讲解的finishBlock中调用了dataBlockIndexWriter.addEntry,接着调用了方法writeInlineBlocks将其中curInlineChunk的值赋给了rootChunk。这里将rootChunk中的数据写入到blockStream,然后再调用blockWriter.writeHeaderAndData将其写入到入参out中。
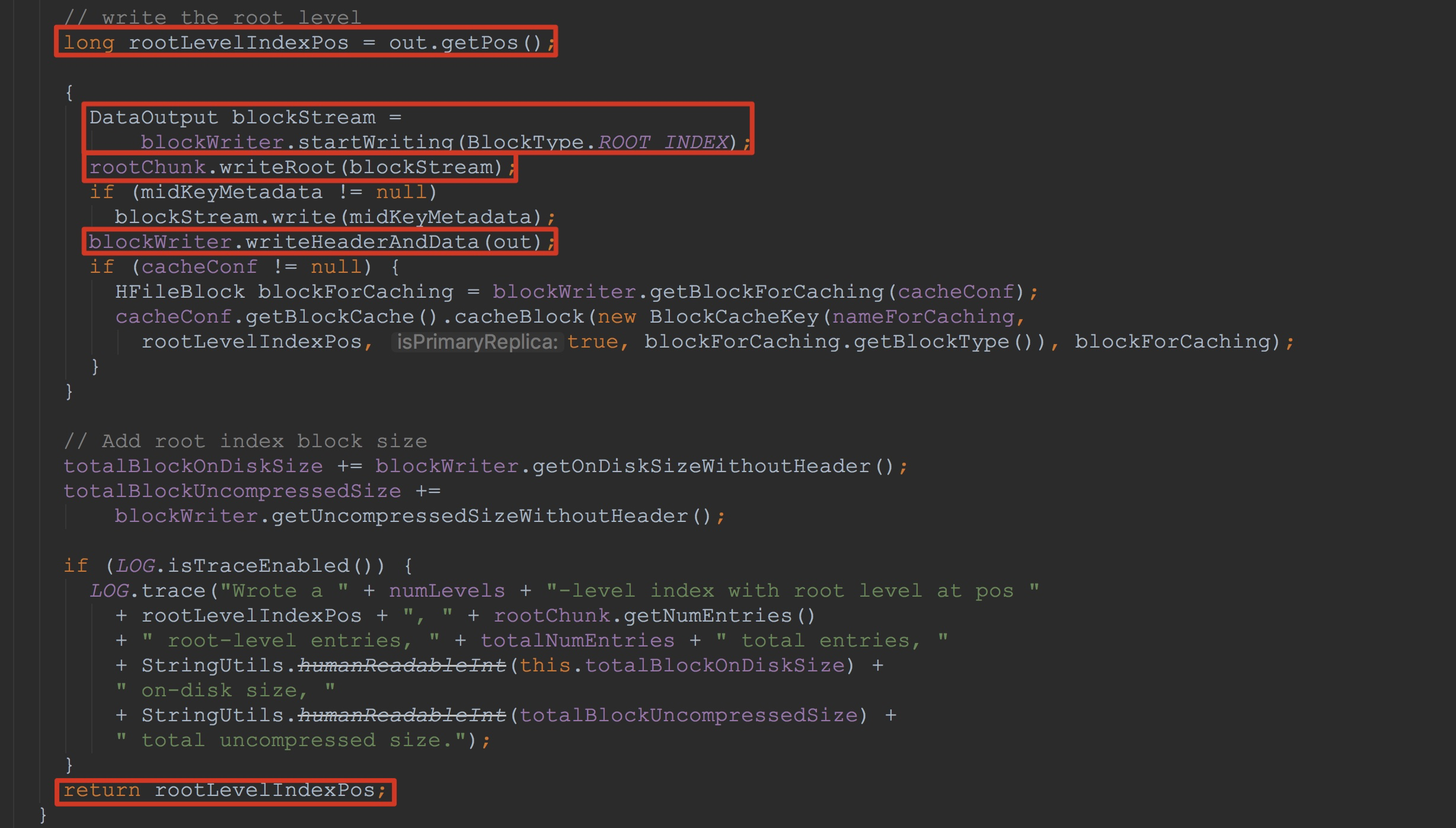
接着调用了metaBlockIndexWriter的一系列方法,这里的方法调用流程与上面大体一致,也并不复杂,我在这里就不介绍了。
我们接着往下走,来到方法writeFileInfo。
1.调用方法finishFileInfo完善成员变量fileInfo中的相关变量
2.调用fileInfo.write,将其成员变量map中的信息使用pb格式序列化后,写入到输出流中(这里的输出流并不是HFileWriterImpl.outputStream,而是blockWriter.startWriting的返回值)。
紧接着,就调用了blockWriter.writeHeaderAndData将刚刚的信息写入到输出流HFileWriterImpl.outputStream中。

然后,开始遍历additionalLoadOnOpenData,以将其中的值写入到成员变量outputStream中。
关于additionalLoadOnOpenData,我在之前没有提到过,这里简单介绍一下。
让我们回到StoreFileWriter.close,如下图所示。下面的两个方法我在之前没有提到过。由于两个方法比较相似,而且,在我们研究的这个场景中并没有DeleteFamily。
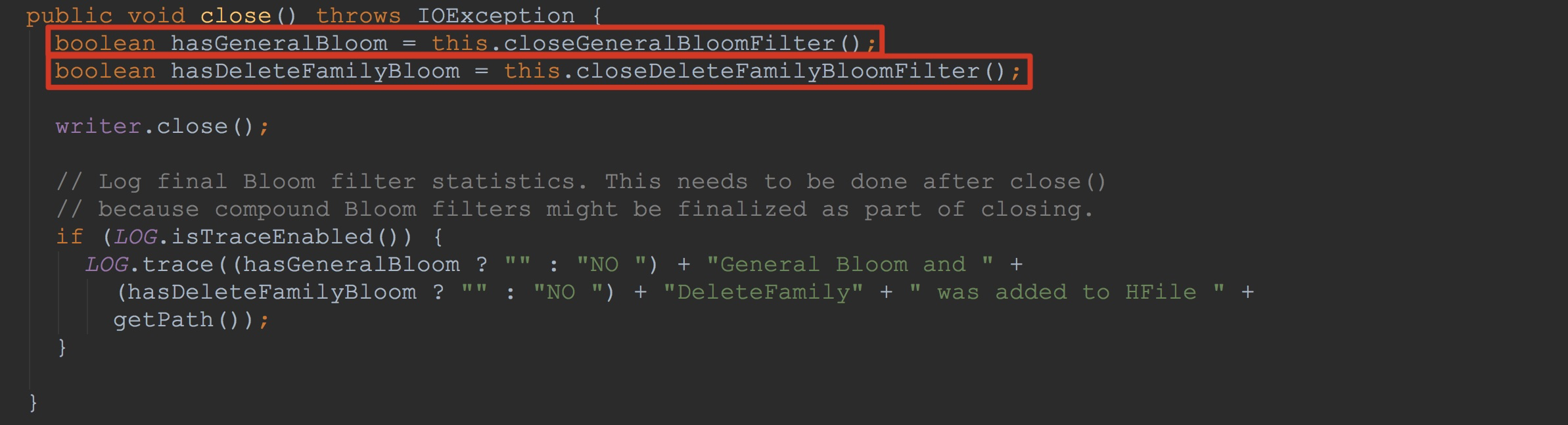
让我们来到方法StoreFileWriter.closeGeneralBloomFilter。这里调用了addGeneralBloomFilter,将入参generalBloomFilterWriter添加到上面提到的additionalLoadOnOpenData。
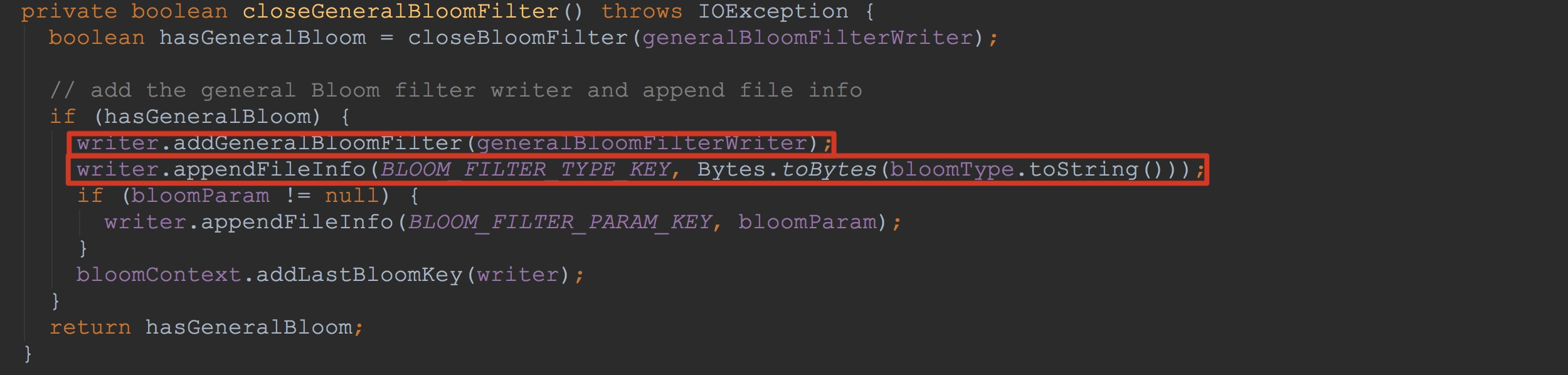
也就是说,遍历additionalLoadOnOpenData时,调用了blockWriter.writeBlock,而在该方法内部,调用了bw.writeToBlock,也就是下图所示的writeToBlock。

上面的bfw.getMetaWriter().write调用了CompoundBloomFilterWriter.MetaWriter.write方法,如下图所示。不知道大家是否还记得,在上面的writeInlineBlocks方法中,最后调用了bloomBlockIndexWriter.addEntry。而下图所示的bloomBlockIndexWriter也正是前面所述的bloomBlockIndexWriter。这里,再次将信息输出到out中。所不同的是,这里只是其索引值。大家可能对这里比较迷惑,为什么都一样。其实,他们都是StoreFileWriter.generalBloomFilterWriter。一次是在StoreFileWriter构造时调用BloomFilterFactory.createGeneralBloomAtWrite,将generalBloomFilterWriter加入到HFileWriterImpl.inlineBlockWriters(虽然这时generalBloomFilterWriter为null),另外一次就是StoreFileWriter.close调用时,间接调用到closeGeneralBloomFilter,然后将generalBloomFilterWriter加入到HFileWriterImpl.additionalLoadOnOpenData。
然后调用了bloomBlockIndexWriter.writeSingleLevelIndex。这个方法里面的相关调用流程我们在上面提到过,这里就不赘述了。

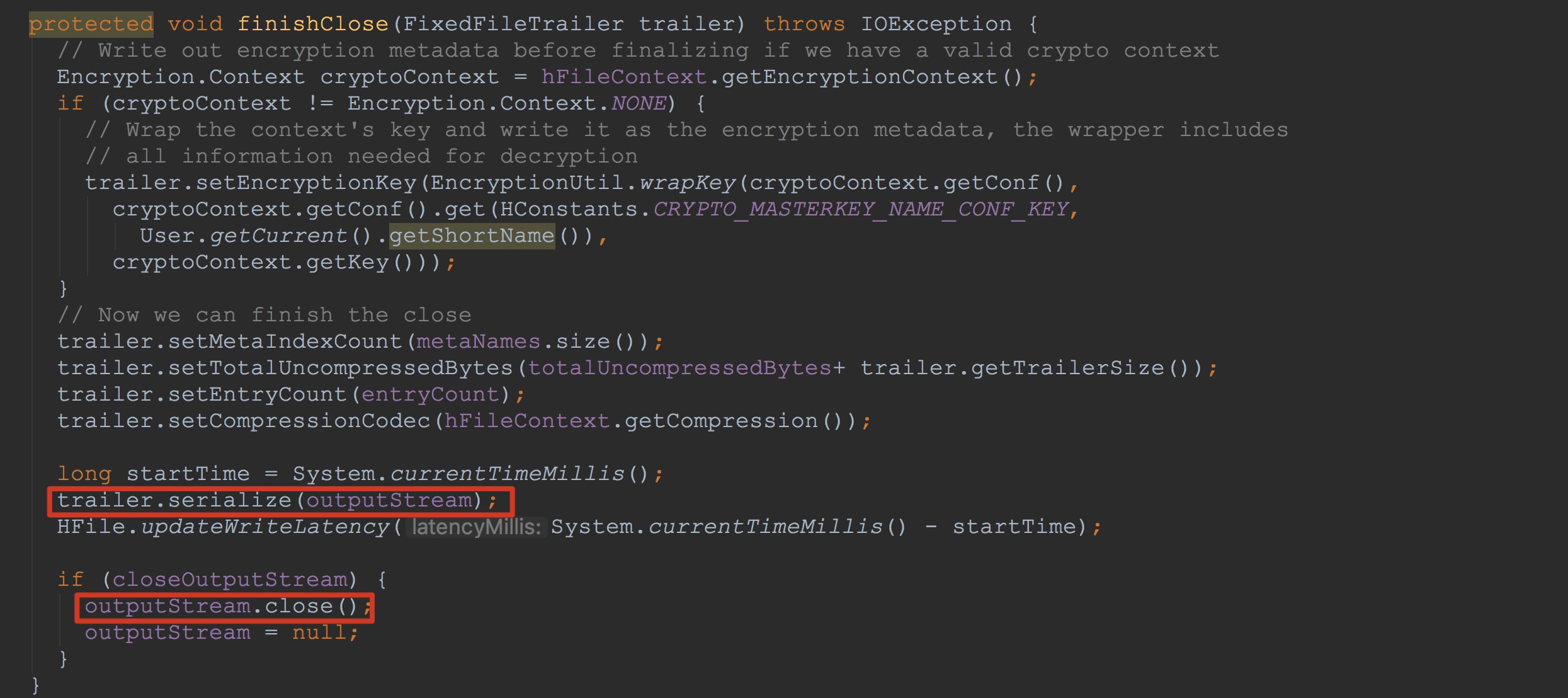
最后,调用了finishClose方法。如下图所示。
1.调用trailer.serialize,将使用PB序列化后的数据写入到输出流outputStream中,这里比较复杂,我在后面会详细介绍。
2.调用outputStream.close,将outputStream中的数据持久化到磁盘上。
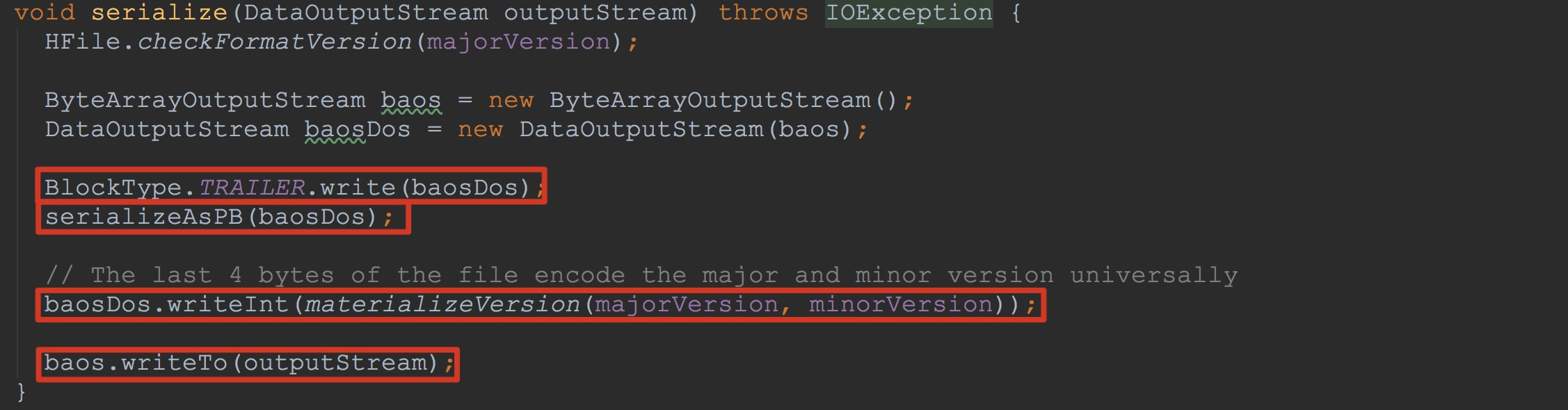
让我们来到FixedFileTrailer.serialize,如下图所示。
1.调用BlockType.TRAILER.write写入8个字节的magic值
2.调用方法serializeAsPB,将PB序列化的数据输出到baosDos中
3.编码主要版本和次要版本并且输出到baosDos
4.将baos中的内容输出到流outputStream中
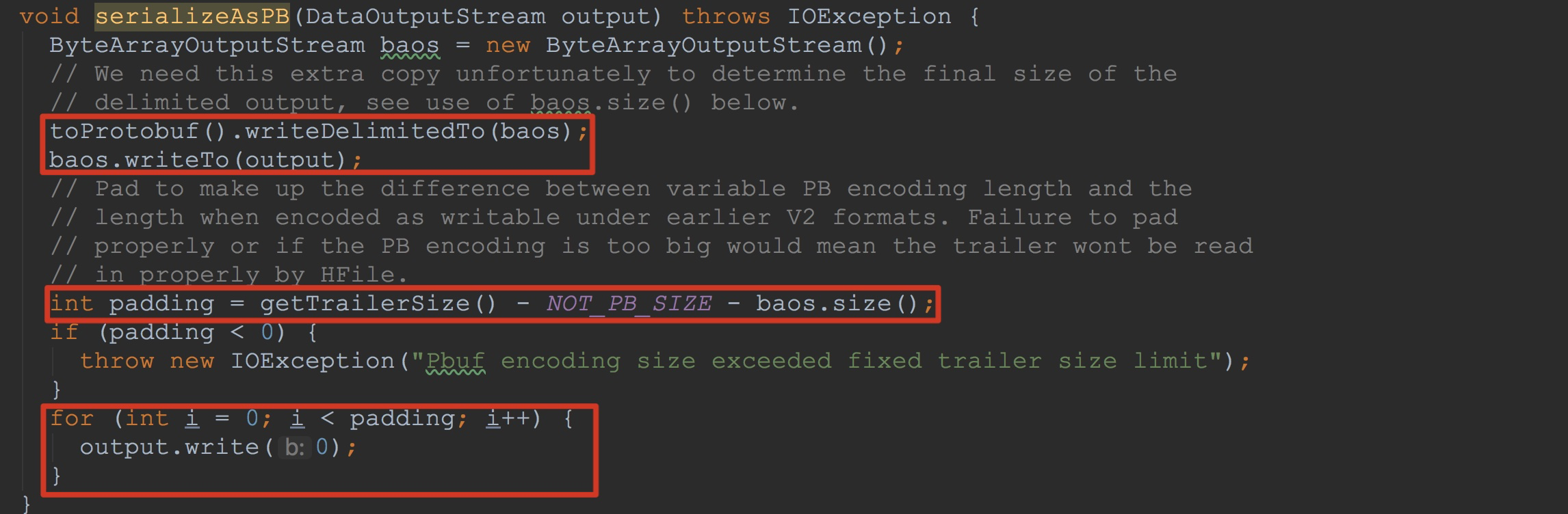
让我们来详细查看方法serializeAsPB。如下图所示。
1.调用toProtobuf().writeDelimitedTo 、baos.writeTo将FFT中的PB后信息写入到入参output中
2.计算padding块并且将其中内容填充为0
关于这里的公式getTrailerSize() - NOT_PB_SIZE - baos.size()大家可能有点模糊。我在这里简单介绍一下。
由于我这里是3.0版本,因此这里getTrailerSize的返回值是4096,然后NOT_PB_SIZE的固定值是12个字节,前面的8个字节是填充的magic值,后面4个字节是用来存放上面提到的——编码主要版本和次要版本。
以及上面调用baosDos.writeInt就是将其版本值写入。
到这里,本节的内容就讲解完成了。本节,我主要沿着上一节的内容,介绍了StoreFlusher.finalizeWriter。下一节,我会从方法HStore.validateStoreFile开始讲起。欢迎大家关注。
- HBase之CF持久化系列(续3——完结篇)
相信大家在看了该系列的前两篇文章就已经对其中的持久化有比较深入的了解.相对而言,本节内容只是对前两节的一个巩固.与持久化相对应的是打开文件并将其内容读入到内存变量中.而在本节,我就来介绍这一点. 本节 ...
- HBase之CF持久化系列(续1)
这一节本来打算讲解HRegion的初始化过程中一些比较复杂的流程.不过,考虑前面的博文做的铺垫并不够,因此,在这一节,我还是特意来介绍HBase的CF持久化.关于这个话题的整体流程性分析在博文< ...
- HBase编程 API入门系列之create(管理端而言)(8)
大家,若是看过我前期的这篇博客的话,则 HBase编程 API入门系列之put(客户端而言)(1) 就知道,在这篇博文里,我是在HBase Shell里创建HBase表的. 这里,我带领大家,学习更高 ...
- HBase编程 API入门系列之delete(客户端而言)(3)
心得,写在前面的话,也许,中间会要多次执行,连接超时,多试试就好了. 前面的基础,如下 HBase编程 API入门系列之put(客户端而言)(1) HBase编程 API入门系列之get(客户端而言) ...
- HBase编程 API入门系列之get(客户端而言)(2)
心得,写在前面的话,也许,中间会要多次执行,连接超时,多试试就好了. 前面是基础,如下 HBase编程 API入门系列之put(客户端而言)(1) package zhouls.bigdata.Hba ...
- HBase编程 API入门系列之HTable pool(6)
HTable是一个比较重的对此,比如加载配置文件,连接ZK,查询meta表等等,高并发的时候影响系统的性能,因此引入了“池”的概念. 引入“HBase里的连接池”的目的是: 为了更高的,提高程序的并发 ...
- Java 数据持久化系列之池化技术
在上一篇文章<Java 数据持久化系列之JDBC>中,我们了解到使用 JDBC 创建 Connection 可以执行对应的SQL,但是创建 Connection 会消耗很多资源,所以 Ja ...
- Java 数据持久化系列之 HikariCP (一)
在上一篇<Java 数据持久化系列之池化技术>中,我们了解了池化技术,并使用 Apache-common-Pool2 实现了一个简单连接池,实验对比了它和 HikariCP.Druid 等 ...
- HBase数据持久化之HRegion.flushcache即CF持久化
我们从HRegion.flushcache开始分析.由于这个过程还是比较复杂的,因此,在这一节,我们不会分析的太过详细,只是单单的介绍一下其大体流程,待大家有了整体的把握之后,我们将在下一节详细介绍其 ...
随机推荐
- elasticsearch 学习
docker run -p : -d elasticsearch #直接拉取运行 #指定条件搜索curl --request GET \ --url 'http://localhost:9200/im ...
- g_thread_init
NAME g_thread_init - 初始化线程系统 SYNOPSIS #include <glib.h> //in gthread.h void g_thread_init (GTh ...
- 用Count() > 0 来判断集合非空的问题
Linq 出现之前,我们通常使用下面的方式来判断集合是否非空,即集合包含元素: ]; ; var list = new List<string>(); ; var collection = ...
- C++ Json解析CJsonObject的详细使用
引用头文件: #include <string> #include <iostream> #include <fstream> #include <casse ...
- 《About Face 3:交互设计精髓》读书笔记(一)
第一章 目标导向设计 当今数字产品的创造过程 市场营销人员对于产品设计过程的贡献,通常局限于需求列表这些需求同用户的实际需要与期望无关,主要在于追赶竞争对手,按照任务清单管理IT资源,以及基于市场调查 ...
- VUE2+elementUI前端实现 三级省市联动select
html: <el-form-item label="选择地区:"> <el-select size="small" style=" ...
- Shell 编程注意点
(一)判断语句 [$# -lt 4 ]判断语句,格式[空格 比较对象1 比较符号 比较对象2] $# 启动脚本时携带参数个数;参数个数总数. $1 代表第一个参数. $? 最后一次执行名命令的退出状态 ...
- python学习笔记(6)
第6章 组合数据类型 组合类型的三种表达形式:集合.序列.字典 集合类型及操作 定义:集合是多个元素的无序组合 集合类型与数学中的集合概念一致 集合元素之间无序,每个元素唯一,不存在相同元素 集合元素 ...
- URI is not registered ( Setting | Project Settings | Schemas and DTDs )
URI is not registered ( Setting | Project Settings | Schemas and DTDs ) 在idea中,当初手动第一次写spring配置文件的时候 ...
- nginx连接数优化
一.一般来说nginx 配置文件中对优化比较有作用的为以下几项: 1. worker_processes 8; nginx 进程数,建议按照cpu 数目来指定,一般为它的倍数 (如,2个四核的cpu计 ...