Pytorch学习笔记(一)---- 基础语法
书上内容太多太杂,看完容易忘记,特此记录方便日后查看,所有基础语法以代码形式呈现,代码和注释均来源与书本和案例的整理。
# -*- coding: utf-8 -*-# All codes and comments from <<深度学习框架Pytorch入门与实践>># Code url : https://github.com/zhouzhoujack/pytorch-book# lesson_1 : Basic code syntax of PT(Pytorch)import torch as timport numpy as np# 1.The version of torchprint(t.__version__) # version is 1.0.1# 2.The defination of tensorx = t.Tensor(5, 3) # 构建 5x3 矩阵,只是分配了空间,未初始化x = t.Tensor([[1,2],[3,4]])# 3.Initialize tensor by [0,1] uniform distributionx = t.rand(5, 3)print(x, x.size()[0]) # torch.Size 是tuple对象的子类,因此它支持tuple的所有操作,如x.size()[0]# 4.Additionx = t.rand(5, 3)y = t.rand(5, 3)print("first method: ", x + y)print("second method: ", t.add(x,y))result = t.Tensor(5, 3) # 加法的第三种写法:指定加法结果的输出目标为result,预先分配空间t.add(x, y, out=result) # 结果存到resultprint("thid method: ", result) # 函数名后面带下划线_ 的函数会修改Tensor本身。x.add_(y)会改变x,但x.add(y)返回一个新的Tensor,x不变# 5.Tensor <-> Numpya = t.ones(5)b = a.numpy()print(b) # array([1., 1., 1., 1., 1.], dtype=float32)a = np.ones(5)b = t.from_numpy(a)print(b) # tensor([1., 1., 1., 1., 1.], dtype=torch.float64)# 6.Get specific index from a tensora = t.rand(5)scalar = a[0]print(scalar,scalar.size()) # 0-dim tensorprint(scalar.item()) # 使用scalar.item()能从中取出python对象的数值# 7.Autograd# 在Tensor上的所有操作,autograd都能为它们自动提供微分# 使得Tensor使用autograd功能,只需要设置tensor.requries_grad=True.# Variable正式合并入Tensor, Variable本来实现的自动微分功能,Tensor就能支持# Variable主要包含三个属性:# data:保存Variable所包含的Tensor# grad:保存data对应的梯度,grad也是个Variable,而不是Tensor,它和data的形状一样。# grad_fn:指向一个Function对象,这个Function用来反向传播计算输入的梯度x = t.ones(2, 2, requires_grad=True) # 为tensor设置 requires_grad 标识,代表着需要求导数y = x.sum()y.backward() # 反向传播,计算梯度print(x.grad) # tensor([[ 1., 1.],[ 1., 1.]])x.grad.data.zero_() # grad在反向传播过程中是累加的,每一次运行反向传播,梯度都会累加之前的梯度,所以反向传播之前需把梯度清零。print(x.grad) # tensor([[ 0., 0.],[ 0., 0.]])
新建Tensor的几种方法
| 函数 | 功能 |
|---|---|
| Tensor(*sizes) | 基础构造函数 |
| tensor(data,) | 类似np.array的构造函数 |
| ones(*sizes) | 全1Tensor |
| zeros(*sizes) | 全0Tensor |
| eye(*sizes) | 对角线为1,其他为0 |
| arange(s,e,step) | 从s到e,步长为step |
| linspace(s,e,steps) | 从s到e,均匀切分成steps份 |
| rand/randn(*sizes) | 均匀/标准正态分布 |
| normal(mean,std)/uniform(from,to) | 正态分布/均匀分布 |
| randperm(m) | 随机排列 |
Backward()详解
对上面的y.backward() 运行原理还不是很熟悉,特此记录一下:
backward()函数用于反向求导数,使用链式法则求导,当自变量为不同变量形式时,求导方式和结果有变化。
1.scalar标量

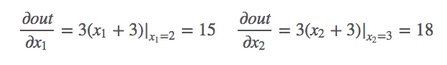
import torch as tfrom torch.autograd import Variablea = Variable(t.FloatTensor([2, 3]), requires_grad=True) # 这里为一维标量b = a + 3c = b * b * 3out = c.mean()out.backward()print(a.grad) # tensor([15., 18.])
2.张量
# y1 = x1^2 y2 = x2^3# dy1/dx1 | x1=2 = 2*x1 = 2*2 =4# dy2/dx2 | x2=3 = 3*x2*x2 = 27m = Variable(t.FloatTensor([[2, 3]]), requires_grad=True) # 注意这里有两层括号,非标量n = Variable(t.zeros(1, 2))n[0, 0] = m[0, 0] ** 2n[0, 1] = m[0, 1] ** 3n.backward(t.Tensor([[1, 1]]),retain_graph=True) # 这里[[1, 1]]作为梯度的系数看待print(m.grad) # tensor[[4,27]]
3.链式求导(还有疑问)
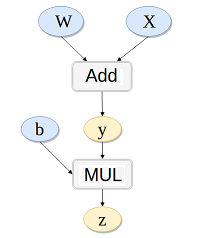
z = (w+x)Tb 其中:dz/dx = dz/dw= z, dz/db = w+x = y , dz/dy = b
# y = x*w# z = y + b# k.backward(p)接受的参数p必须要和k的大小一样,x.grad = p*dk/dxw = Variable(t.randn(3), requires_grad=True)x = Variable(t.randn(3), requires_grad=True)b = Variable(t.randn(3), requires_grad=True)y = w + xz = y.dot(b)y.backward(b,retain_graph=True)print(x.grad,w.grad,b) # x.gard=w.gard=b
参考资料
Backward()详解:http://www.mamicode.com/info-detail-2167311.html
Pytorch学习笔记(一)---- 基础语法的更多相关文章
- Java学习笔记之---基础语法
Java学习笔记之---基础语法 一. Java中的命名规范 (一)包名 由多个单词组成时,所有字母小写(例如:onetwo) (二)类名和接口 由多个单词组成时,所有单词首字母大写(例如:OneTw ...
- Hive学习笔记:基础语法
Hive基础语法 1.创建表 – 用户表 CREATE [EXTERNAL外部表] TABLE [IF NOT EXISTS 是否存在] HUserInfo ( userid int comment ...
- 【C语言C++编程学习笔记】基础语法,第一个简单的实例编程入门教程!
C语言/C++编程学习:一个简单的实例 让我们来看一个简单的C语言程序.从下面的程序可以看出编写C语言程序的一些基本特征. 如果你能知道该程序将会在显示器上显示一些内容,那说明你还是知道一些的! ...
- PHP学习笔记01——基础语法
<!DOCTYPE html> <html> <?php // 1.使用$加变量名来表示变量,php是弱类型语言,不要求在使用变量前声明,第一次赋值时变量才被创建 $a ...
- 01-Python学习笔记-基础语法
Python标识符 -d 在解析时显示调试信息 -O 生成优化代码 ( .pyo 文件 ) -S 启动时不引入查找Python路径的位置 - ...
- java学习笔记之基础语法(一)
1.java语言基础由关键字.标识符.注释.常量和变量.运算符.语句.函数和数组等组成. 2.1关键字 定义:被java语言赋予了特殊含义的单词 特点:关键字中所有的字母都是小写. 2.2用于定义数据 ...
- Java学习笔记之基础语法(顺序,条件,循环语句)
顺序结构:自上而下 条件分支选择结构: if条件语句 1,一旦某一个分支确定执行以后,其他分支就不会执行.if后面的条件必须是boolean类型 2,if 后面如果不加大括号,默认相邻的下一 ...
- Java学习笔记之基础语法(数据类型)
8种基本数据类型 整型: byte[1字节] short[2字节] int[4字节] long[8字节] 1,四种整型之间的区别:申 ...
- Python 学习笔记(基础语法 restful 、 Flask 和 Requests)
input 函数 #!/usr/bin/env python3 name = input("\n\n按下 enter 键后退出.") print(name) print() 在 p ...
- JavaWeb学习笔记——jsp基础语法
1.JSP注释 显式注释 <!-- 注释内容 --> 隐式注释,隐式注释在客户端无法看见 // /* */ <% 注释内容 %> 2.Scriptlet(小脚本程序) 所有嵌入 ...
随机推荐
- 关于使用tradingview插件的一些心得
1.禁用自带的一些功能 disabled_features: [ // 开启图表功能的字符串文字 允许将用户设置保存到本地存储 'header_symbol_search', // 头部搜索 &quo ...
- 12 Django Rest Swagger生成api文档
01-简介 Swagger:是一个规范和完整的框架,用于生成.描述.调用和可视化RESTful风格的Web服务.总体目标是使客户端和文件系统源代码作为服务器以同样的速度来更新.当接口有变动时,对应的接 ...
- ABP实践(1)-通过官方模板创建ASP.NET Core 2.x版本+vue.js单页面模板-启动运行项目
1,打开ABP官网下载模板页面 2,根据下图选择对应的选项及输入项目名 注:上图验证码下方的选择框打钩表示下载最新稳定版,不打钩表示下载最新版本(有可能是预览版) 3,解压下载的压缩包 解压之后是个a ...
- 【zabbix教程系列】三、zabbix 3.4 在centos 7 上安装详细步骤
一.环境准备 [root@ltt01 ~]# ip a : lo: <LOOPBACK,UP,LOWER_UP> mtu qdisc noqueue state UNKNOWN qlen ...
- Commons-DbUtils
<dependency> <groupId>commons-dbutils</groupId> <artifactId>commons-dbutils& ...
- react-redux的基本用法
注意:读懂本文需要具备redux基础知识, 注明:本文旨在说明如何在实际项目中快速使用react-redux,限于篇幅,本文对具体的原理并未做分析,请参考redux官网 我一直以为我写了一篇关于rea ...
- bugku web 管理员系统
页面是一个登陆表单,需要账号密码,首先f12查看源代码,发现有一段可疑的注释,明显是base64,解码得到test123,似乎是一个类似于密码的东西,既然是管理员,就猜测用户名是admin,填上去试一 ...
- python 第三方库的加载与虚拟机的登录
通过pip来安装python模块(pip方式仅需要联网即可,不需要下载其他文件即可实现扩展库哦的安装.升级和卸载).下载python3.5以上的版本(包括3.5),在我的电脑输入cmd进入命令提示符, ...
- python 多线程 ping
python 多线程 ping 多线程操作可按如下例子实现 #!/usr/bin/env python #encoding: utf8 import subprocess from threading ...
- ADRC-active disturbance rejection control-自抗扰控制器
ADRC自抗扰控制基本思想要点: 1.标准型与总扰动,扩张状态与扰动整体辨识,微分信号生成与安排过渡过程以及扰动的消减与控制量产生. ADRC主要构成: 1)跟踪微分器(TD)---the track ...