Pandas常用功能总结
1.读取.csv文件
df2 = pd.read_csv('beijingsale.csv', encoding='gb2312',index_col='id',sep='\t',header=None)
参数解析见:https://www.cnblogs.com/datablog/p/6127000.html
index_col用于指定用作行索引的列编号或者列名,sep用于指定文件的分隔符(默认是以,作为分隔符),header=None 不用文件的的第一行作为列索引
文件读取之后生成的是一个DataFrame
文件的输出
把DataFrame中的值输出到csv文件中
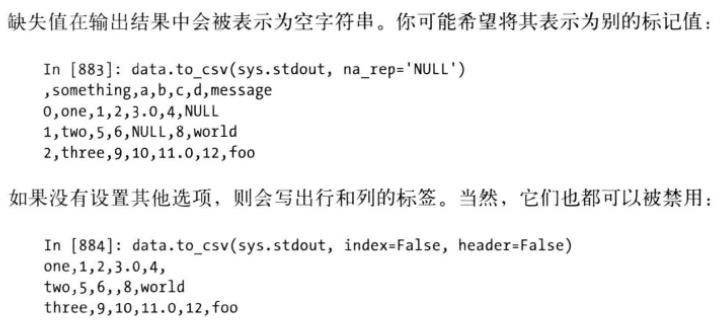
Index=False指定输出文件没有行索引,header=False指定输出文件没有列索引
2.复制DataFrame中的某些列
agg_df2=agg_df[['USRID','V1']].copy()
对原来DataFrame中的['USRID','V1']进行复制,生成一个只包含['USRID','V1']的新DataFrame
3.为DataFrame中的某一列赋值
data['num']=1 //索引名为num的列,里面的元素将全部变为1
4.把某一列设置为索引
train_data=train_data.set_index('USRID')
5.向DataFrame中添加列
df['sale_time'] = df2['dealDate']注意df与df2的索引要相等
6.删除DataFrame中某一列
df.drop(['sale_time'], axis=1, inplace=True)注意这里的axis=1表明删除DataFrame中的列,axis=0是删除某一行。inplace=True表明操作后取代原来的DataFrame
7.取出DataFrame中某一列满足某一条件的所有行
aa=frame[frame['a']==1] #frame['a']==1返回的是True,False值再进一步根据此进行选择
8.把DataFrame的值作为训练数据向ndarray的转换
data=np.array(frame)
9.pd.merge()的合并操作
一般用于一个读取的是数据另一个文件读取的是标签,按照用户唯一的编号进行合并
frame = pd.DataFrame({"a":[9,2,5,1],"b":[4,7,-3,2],"c":[6,5,8,3]})
frame2 = pd.DataFrame({"a":[9,5,2,1],"d":[4,7,-3,2]})
frame3=pd.merge(frame,frame2,on=["a"])
默认的是inner内连接,on指定按哪一或哪些列进行合并,内连接一般用于合并的两个DataFrame所指定的合并列大小相同的情况
Pandas的merge其how参数解析
具体参考:
https://www.cnblogs.com/yuanninesuns/p/7942867.html
Pandas的merge用于对两个DataFrame进行


How参数可取四个值,left,right,inner,outer,
Left即为以左边的df其on的那一列作为最后连接的键值,right是以右边的,默认的是inner即为df1和df2都存在的才留下来,以为on那一列取交集,outer是对df1和df2的on那一列存在的都留下来,是对on那一列取并集。
10.pd.sort_values()的用法
它是按照某一数值列对整个DataFrame进行排序,注意有个inplace参数默认为False设置为True则直接取代原来的,用法如下:
df.sort_values(by='col2',inplace=True)
11.pd.reset_index()的用法
其作用是重置索引使得索引从0开始,一般用于sort_values()之后,因为排序之后索引会乱,用法如下:
df.reset_index(inplace=True,drop=True)
注意这两个参数,设置inplace=True直接替代原来的DataFrame,设置drop=True则把原来的索引删除,否则原来的索引会以index为列名成为DataFrame中的一列。
12.去除重复值drop_duplicates()的用法
用于去除DataFrame中的重复值,具体用法如下:
df.drop_duplicates(['col1','col2'],inplace=True,keep='first')
第一个参数的设定['col1','col2']即为删除这两列的值都相等的数据,这时需要注意keep这个参数,其默认为first即为若相等则保留第一个元素,若把其设置为last则为若相等则保留最后一个元素,若设置为None则为存在相等的都删除,inplace=True则为直接替代原来的DataFrame
13.删除DataFrame()中所有存在空值的行
DataFrame.dropna()
14. Pandas的head()和tail
head()默认是取前五行元素,head(n)取前n行
tail()默认是取后五行元素,tail(n)取后n行
15. pandas的groupby和agg以及reset_index和sort_values函数
例如:
import pandas as pd
data=[
[1,2,3,4],[1,4,7,8],[2,8,9,4]
]
df=pd.DataFrame(data,columns=['a','b','c','d'])
df2=df[['a','b','c']]
print(df2)
print(df2.groupby('a')['b'].agg('sum').reset_index().sort_values('a'))
groupby是按照某些列进行分组把分组列相同的归为一组,注意它返回的不再是DataFrame类型的数据
agg函数是应用例如sum,mean,std这些聚合函数
reset_index可以还原索引,不管原来的索引是什么,从新变为默认的整型索引,它一般和agg()连用
sort_values()按值进行排序,其中有个axis参数默认是0即为按列进行排序,若axis参数的值设为1则是按行进行排序。
上面的案例是按照a列进行分组取分组后的a,b列,对每个分组的b列执行求和操作,然后重置索引,最后再按照a列的值进行排序操作
16.Pandas读取数据之后如何根据标签列快速判断数据是否均衡?
print(train_data['Survived'].value_counts())
17.Pandas中填充DataFrame的nan值
df=DataFrame(np.arange(16).reshape((4,4)),columns=['a','b','c','d'],index=['one','two','three','four'])
df.ix[1]=np.nan
print df
print df.fillna(df.mean())
df.mean()是把nan值用每一列的均值填充,例如这列填充two行使用one,three,four行的值之和除以3.
18.Pandas中loc iloc ix的用法以及区别
1)loc()按照行索引选取行
例如:
data = [[1,2,3],[4,5,6]]
index = ['e','f']
columns=['a','b','c']
df = pd.DataFrame(data=data, index=index, columns=columns)
print(df.loc['e'])
输出行索引为e的这一行的值
若为:
data = [[1,2,3],[4,5,6]]
index = [1,2]
columns=['a','b','c']
df = pd.DataFrame(data=data, index=index, columns=columns)
print(df.loc[1])
这里的行索引只能用1,2不能再用e,f
获取多行索引以上两种情况用如下方法:
df.loc[1:]
df.loc[‘e’:]
获取某些行某些列
df.loc[1,['b','a']]
2)iloc()通过行号以及列号的索引获取数据
例如:
data = [[1,2,3],[4,5,6]]
index = ['e','f']
columns=['a','b','c']
df = pd.DataFrame(data=data, index=index, columns=columns)
df.iloc[1]获取行号为1的数据
print(df.iloc[1,[1]])获取行列号都为1的数据。
print(df.iloc[:,[1]])获取所有行列号为1的数据。
注意:这个函数只能通过行列号索引获取数据
3)ix()是以上两者的结合,获取行列时既可以通过行列的索引也可以通过行列的标签。
df.ix[:,df.ix[0]>2.5]
先选取第0行的值大于2.5的列,再选取所有行这些列的元素
19.Pandas中基于DataFrame的apply()
Apply()即为在DataFrame的行、列以及整个DataFrame上应用某一函数。具体见http://blog.csdn.net/y12345678904/article/details/72757912
# Define function to extract titles from passenger names
def get_title(name):
title_search = re.search(' ([A-Za-z]+)\.', name)
# If the title exists, extract and return it.
if title_search:
return title_search.group(1)
return ""# Create a new feature Title, containing the titles of passenger namesfor dataset in full_data:
dataset['Title'] = dataset['Name'].apply(get_title)
例如对pandas的某一文本列进行处理
def word_cut(df):
return ' '.join([con for con in jieba.cut(''.join(list(df['content']))) if not con in stopwords])
df['content']=df.apply(word_cut,axis=1)
给其传的是整个df,其主要目的是对df['content']中的内容进行分词处理,因为jieba.cut()接收的数据是字符串,所以要做相应的转换。
Pandas常用功能总结的更多相关文章
- Pandas常用功能
在使用Pandas之前,需要导入pandas库 import pandas as pd #pd作为pandas的别名 常用功能如下: 代码 功能1 .DataFrame() 创建一个DataFr ...
- Pandas常用基本功能
Series 和 DataFrame还未构建完成的朋友可以参考我的上一篇博文:https://www.cnblogs.com/zry-yt/p/11794941.html 当我们构建好了 Series ...
- NumPy和Pandas常用库
NumPy和Pandas常用库 1.NumPy NumPy是高性能科学计算和数据分析的基础包.部分功能如下: ndarray, 具有矢量算术运算和复杂广播能力的快速且节省空间的多维数组. 用于对整组数 ...
- Pandas常用数据结构
Pandas 概述 Pandas(Python Data Analysis Library)是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的.Pandas 纳入了大量库和一些标准的数 ...
- Python常用功能函数总结系列
Python常用功能函数系列总结(一) 常用函数一:获取指定文件夹内所有文件 常用函数二:文件合并 常用函数三:将文件按时间划分 常用函数四:数据去重 Python常用功能函数系列总结(二) 常用函数 ...
- WebStorm 常用功能的使用技巧分享
WebStorm 是 JetBrain 公司开发的一款 JavaScript IDE,使用非常方便,可以使编写代码过程更加流畅. 本文在这里分享一些常用功能的使用技巧,希望能帮助大家更好的使用这款强大 ...
- AVA正则表达式4种常用功能
正则表达式在字符串处理上有着强大的功能,sun在jdk1.4加入了对它的支持 下面简单的说下它的4种常用功能: 查询: String str="abc efg ABC"; Str ...
- [转]WebPack 常用功能介绍
概述 Webpack是一款用户打包前端模块的工具.主要是用来打包在浏览器端使用的javascript的.同时也能转换.捆绑.打包其他的静态资源,包括css.image.font file.templa ...
- FastReport.Net 常用功能总汇
一.常用控件 文本框:输入文字或表达式 表格:设置表格的行列数,输入数字或表达式 子报表:放置子报表后,系统会自动增加一个页面,你可以在此页面上设计需要的报表.系统在打印处理时,先按主报表打印,当碰到 ...
随机推荐
- (七) UVC框架分析
title: UVC框架分析 date: 2019/4/23 19:50:00 toc: true --- UVC框架分析 源码的位置在drivers\media\video\uvc,查看下Makef ...
- mysql删除多个重复数据,多个字段添加唯一性索引
需求:删除station_id.ab_data_time.item_code_id.data_cycle.ab_value 字段重复的记录 #查询重复的数据 select b.id,b.station ...
- JAVA中循环删除list中元素的方法总结【转】
印象中循环删除list中的元素使用for循环的方式是有问题的,但是可以使用增强的for循环,然后今天在使用时发现报错了,然后去科普了一下,再然后发现这是一个误区.下面就来讲一讲..伸手党可直接跳至文末 ...
- DirectX11--深入理解与使用缓冲区资源
前言 在Direct3D 11中,缓冲区属于其中一种资源类型,它在内存上的布局是一维线性的.根据HLSL支持的类型以及C++的使用情况,缓冲区可以分为下面这些类型: 顶点缓冲区(Vertex Buff ...
- ClassLoader那事儿
ClassLoader是什么 ClassLoader中文类加载器,java编写出来的是.java文件,然后编译成.class文件,而ClassLoader就是把class文件加载到jvm内存中:但jv ...
- Ireport5.0.1 从java后台接收list集合
作为ireport新手,开始使用时总有很多问题,说一下今天解决的一个问题,就是怎样从java后台接收list集合并显示出列表. 1.首先要在主dataset中的Paramerters 中创建参数lis ...
- (八)python中的函数
一.聊聊函数 1.什么是函数? 上学时我记得最简单的是 F=x+y 这是一个简单的函数,看看python 中的格式 def test(): #函数定义 def 万年不变 print("> ...
- Java(13) 抽象和封装
一.简述从现实世界中抽象出类的步骤 第一:找出分类(分析出类) 第二:找出类的特征(分析类的相关属性) 第三:找出类的行为(分析类的方法) 二.常量(经常出现的变量值) 2.1 语法: public ...
- 2018-2019 20165237网络对抗 Exp4 恶意代码分析
2018-2019 20165237网络对抗 Exp4 恶意代码分析 实验目标 1.1是监控你自己系统的运行状态,看有没有可疑的程序在运行. 1.2是分析一个恶意软件,就分析Exp2或Exp3中生成后 ...
- Linux 使用 arp-scan 检查是否存在IP地址冲突
如果前期没有做好IP地址规划,即使有IP地址统一不小心也会犯错!推荐服务器IP地址使用要登记明细,上次机房批量部署服务器,就将已再用的IP又分配给另一台服务器,还好对业务没有造成大的影响. 那么在给服 ...