如何正确使用Java序列化?
前言
什么是序列化:将对象编码成一个字节流,这样一来就可以在通信中传递对象了。比如在一台虚拟机中被传递到另一台虚拟机中,或者字节流存储到磁盘上。
“关于Java的序列化,无非就是简单的实现Serializable接口”这样的说法只能说明停留在会用的阶段,而我们想要走的更远往往就需要了解更多的东西,比如:为什么要实现序列化?序列化对程序的安全性有啥影响?如何避免多余的序列化?.....
本文主要参考资料《Effective Java》,其中代码除了只作部分说明,不能运行外,剩余代码都是亲自实践过的!
一、序列化代价
虽然实现Serializable很简单,但是为了序列化而付出的长期开销往往是实实在在的。实现Serializable接口而付出的最大代价是,一旦一个类被发布,就大大降低了“改变这个类的实现”的灵活性。
问:这个灵活性具体是指什么呢?
即一旦类实现了Serializable接口,并且这个类被广泛地使用,往往必须永远支持这种序列化形式,如果使用默认的序列化形式,那么这种序列化形式将永远地束缚在该类最初的内部表示法上,换句话说,一旦接受了默认的序列化形式,这个类中私有的和包级私有的实例域都变成导出的API的一部分,这显然是不符合的。这也就是实现序列化往往需要考虑到的几个代价,具体请往下看!
1、可能会导致InvalidClassException异常
如果没有显式声明序列版本UID,对对象的需求进行了改动,那么兼容性将会遭到破坏,在运行时导致InvalidClassException。比如:增加一个不是很重要的工具方法,自动产生的序列版本UID也会发生变化,则会出现序列版本UID不一致的情况。所以最好还是显式的增加序列版本号UID。
对User JavaBean实现Serializable接口,增加固定的序列版本号
public class User implements Serializable {
/** 显示增加序列版本UUID,自动生成UUID可能会导致InvalidClassException */
private static final long serialVersionUID = 1L;
public User(int id, String name) {
this.id = id;
this.name = name;
}
private int id;
private String name;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "User{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
}
使用ObjectOutputStream与ObjectInputStream流控制序列与反序列
/**
* @author jian
* @date 2019/4/5
* @description 测试序列化
*/
public class SeriablizableTest { public static void main(String[] args) {
User user = new User(1, "lijian");
serializeUser(user);
deserializeUser(); } /**
* 使用writeObject方法序列化
*
* @param user
*/
private static void serializeUser(User user) {
ObjectOutputStream outputStream = null;
try {
// 创建对象输出流, 包装一个其它类型目标输出流,如文件流
outputStream = new ObjectOutputStream(new FileOutputStream("D:\\user.txt"));
// 通过对象输出流的writeObject方法将对象user写入流中
outputStream.writeObject(user);
System.out.println("user序列化成功!");
} catch (IOException e) {
e.printStackTrace();
} finally {
if (outputStream != null) {
try {
outputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
} private static void deserializeUser() {
User user = null;
Employee employee = null;
ObjectInputStream inputStream = null;
try {
// 创建对象输出流, 包装一个其它类型目标输出流,如文件流
inputStream = new ObjectInputStream(new FileInputStream("D:\\user.txt"));
// 通过对象输出流的writeObject方法将对象user写入流中
user = (User)inputStream.readObject();
System.out.println("user反序列化成功:" + user);
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
finally {
if (inputStream != null) {
try {
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
} }
}
输出结果:先看user.txt文件中二进制文件流(因为txt打不开二进制流,所以是乱码)
之后再看控制台中,反序列化输出的User{id=1, name='lijian'},说明整个过程序列化成功!

之后去掉固定的序列版本号UID,让其自动生成,同时增加age属性(或者手动修改UID为2L)
private static final long serialVersionUID = 2L;
只进行反序列化将会报错: java.io.InvalidClassException
public static void main(String[] args) {
User user = new User(1, "lijian");
// serializeUser(user);
deserializeUser();
}

2、增加了出现Bug和安全漏洞的可能性
序列化机制是一种语言之外的对象创建机制,反序列化机制都是一个“隐藏的构造器”,具备与其他构造器相同的特点,正式因为反序列化中没有显式构造器,所以很容易就会忽略:不允许攻击者访问正在构造过程中的对象内部信息。换句话说,序列化后的字节流可以被截取进行伪造,之后利用readObject方法反序列会不符合要求甚至不安全的实例。

3、随着类发行新的版本,测试负担也会增加。
一个可序列化的类被修订时,需要检查是否“在新版本中序列化一个实例,可以在旧版本中反序列化”,如果一个实现序列化的类有很多的子类或者是被修改时,就不得不加以测试。
二、序列化的缺陷
1、序列化是保存对象的状态,也就是不会关心static静态域,静态域不会被序列化。如User中count静态域。
public class User implements Serializable {
private static final long serialVersionUID = 1L;
private static int count = 1;
public User(int id, String name) {
// 约束条件name不能为null
if (name == null || StringUtils.isEmpty(name)) {
throw new NullPointerException("name is null");
}
this.id = id;
this.name = name;
}
public User(){};
private int id;
private String name;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getCount() {
return count;
}
public void setCount(int count) {
User.count = count;
}
@Override
public String toString() {
return "User{" +
"id=" + id +
", name='" + name + '\'' +
", count=" + count +
'}';
}
private void readObject(ObjectInputStream inputStream)
throws IOException, ClassNotFoundException {
inputStream.defaultReadObject();
// 约束条件name不能为null
if (name == null || StringUtils.isEmpty(name)) {
throw new NullPointerException("name is null");
}
}
}
赋值count为20:
public static void main(String[] args) {
User user = new User();
user.setName("Lijian");
user.setId(1);
user.setCount(20);
serializeUser(user);
deserializeUser();
}
序列化-反序列化
/**
* 使用writeObject方法序列化
*
* @param user
*/
private static void serializeUser(User user) {
ObjectOutputStream outputStream = null;
try {
// 创建对象输出流, 包装一个其它类型目标输出流,如文件流
outputStream = new ObjectOutputStream(new FileOutputStream("D:\\user.txt"));
// 通过对象输出流的writeObject方法将对象user写入流中
outputStream.writeObject(user);
System.out.println("user序列化成功!");
} catch (IOException e) {
e.printStackTrace();
} finally {
if (outputStream != null) {
try {
outputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
} private static void deserializeUser() {
User user = null;
ObjectInputStream inputStream = null;
try {
// 创建对象输出流, 包装一个其它类型目标输出流,如文件流
inputStream = new ObjectInputStream(new FileInputStream("D:\\user.txt"));
// 通过对象输出流的writeObject方法将对象user写入流中
user = (User)inputStream.readObject();
// User静态变量初始化为0,不会被反序列化
System.out.println("user反序列化成功!");
System.out.println("id:" + user.getId());
System.out.println("name:" + user.getName());
System.out.println("count:" + user.getCount());
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
finally {
if (inputStream != null) {
try {
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
} }
控制它输出:count明明被赋值为20,但是反序列化后输出为0,说明static是不会参数序列化的,跟transient类似。最终在反序列化过程中会被初始化为默认值(基本数据类型为0,对象引用为null,boolean为false)

2、在序列化对象时,如果该对象中有引用对象域名,那么也要要求该引用对象是可实例化的。如序列化User实例,其中引用了Employee实例,那么也需要对Employee进行可序列化操作,否则会报错: java.io.NotSerializableException
User增加对Employee引用:
/** 对外引用其它对象,如果序列化该实例,则该对象实例也必须能实例化(implement Serializable) */
public Employee employee = new Employee(1, "Java programmer");
Employee不实现序列化:
public class Employee{
private int code;
private String position;
public int getCode() {
return code;
}
public void setCode(int code) {
this.code = code;
}
public String getPosition() {
return position;
}
public void setPosition(String position) {
this.position = position;
}
public Employee(int code, String position) {
this.code = code;
this.position = position;
}
@Override
public String toString() {
return "Employee{" +
"code=" + code +
", position='" + position + '\'' +
'}';
}
}
测试类:
/**
* @author jian
* @date 2019/4/5
* @description 测试序列化
*/
public class SeriablizableTest { public static void main(String[] args) {
User user = new User(1, "lijian");
serializeUser(user);
deserializeUser(); } /**
* 使用writeObject方法序列化
*
* @param user
*/
private static void serializeUser(User user) {
ObjectOutputStream outputStream = null;
try {
// 创建对象输出流, 包装一个其它类型目标输出流,如文件流
outputStream = new ObjectOutputStream(new FileOutputStream("D:\\user.txt"));
// 通过对象输出流的writeObject方法将对象user写入流中
outputStream.writeObject(user);
System.out.println("user序列化成功!");
} catch (NotSerializableException e) {
System.out.println("user引用employee对象域序列化失败");
} catch (IOException e) {
e.printStackTrace();
} finally {
if (outputStream != null) {
try {
outputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
} private static void deserializeUser() {
User user = null;
Employee employee = null;
int id = 0;
ObjectInputStream inputStream = null;
try {
// 创建对象输出流, 包装一个其它类型目标输出流,如文件流
inputStream = new ObjectInputStream(new FileInputStream("D:\\user.txt"));
// 通过对象输出流的writeObject方法将对象user写入流中
user = (User)inputStream.readObject();
System.out.println("user引用employee对象域反序列化成功");
System.out.println("user反序列化成功:" + user);
} catch (WriteAbortedException e) {
System.out.println("user引用employee对象域反序列化失败");
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
finally {
if (inputStream != null) {
try {
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
} }
}
控制台输出结果:

要解决这样的问题,要么将 Employee implement Serializable ,要么对Employee对象实例transient修饰: public transient Employee employee = new Employee(1, "Java programmer"); 。但是需要注意的是序列化过程会对transient修饰的域初始化为默认值(对象引用为null,基本数据类型为0,boolean为false),所以执行以上代码会出现 java.lang.NullPointerException
3、默认序列化的过程可能消耗大量内存空间和时间,甚至可能会引起栈溢出:因为第二条的原因,如果一个类中大量存在引用对象域,并且都需要实现序列化,那么整个序列化过程可能会很消耗时间,在通信传输过程中更是如此,同时序列化后的字节流需要足够大的内存。
三、提高序列化的安全性
1、编写readObject提供安全性与约束性
即使确定了默认的序列化形式是合适的,通常还必须提供一个readObject方法以保证约束关系和安全性。readObject方法相当于另一个共有构造器(可以认为是用“字节流作为唯一参数”的构造器),跟其它构造器一样,它也要求同样的所有主要事项:构造器必须检查参数的有效性,必要时对参数进行保护性拷贝等。readObject如果没有做到,那么对于攻击者来说违反这个类的约束条件相对就比较简单了,如果对一个人工仿造的字节流(人工修改从实例序列后的字节流)时,readObject产生的对象会违反所属类的约束条件。
1)为了解决这个问题,User中需要提供了readObject方法,该方法首先调用defalutReadObject,然后检查被反序列化之后的对象的有效性,如果有效性检查失败,readObject方法就会抛出InvalidObjectException异常,使反序列过程不能成功。
private void readObject(ObjectInputStream inputStream)
throws IOException, ClassNotFoundException {
inputStream.defaultReadObject();
}
User中的构造器中已对参数name约束为不能为null
public User(int id, String name) {
// 约束条件name不能为null或空
if (name == null || StringUtils.isEmpty(name)) {
throw new NullPointerException("name is null or empty");
}
this.id = id;
this.name = name;
}
2)那么readObject中也应该对其name进行约束,否则人工伪造的字节流很容易通过readObject构造出没有任何约束的对象实例,造成安全隐患。
private void readObject(ObjectInputStream inputStream)
throws IOException, ClassNotFoundException {
inputStream.defaultReadObject(); // 约束条件name不能为null或空
if (name == null || StringUtils.isEmpty(name)) {
throw new NullPointerException("name is null or empty");
}
}
尽管以上两种修正已经有效地避免攻击者创建无效的User实例,但是还有一种情况通过伪造字节流可以创建可变的User实例:比如User中增加Date对象引用birthday私有域,然后通过附加伪造字节流指向该birthday引用,攻击者从ObjectInputStream中读取User实例,然后读取附加后面的恶意Date引用,通过该Date引用就可以能够访问User对象内部私有Date域所引用的对象,从而改变User实例。
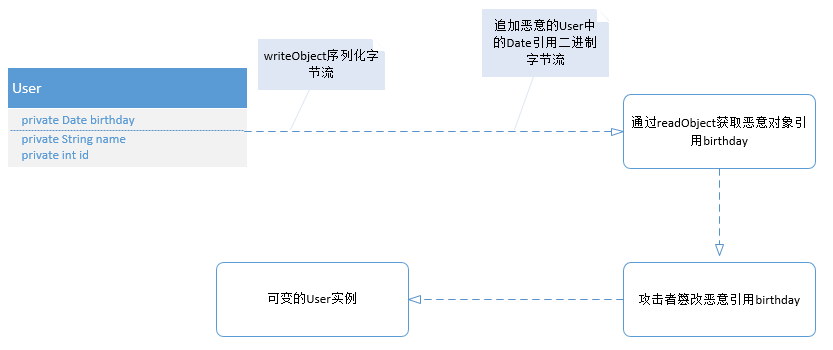
代码如下:
public class MutableUser {
public User user;
public Date birthday;
public MutableUser(){
try {
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream out = new ObjectOutputStream(bos);
// 字节流有效的User实例开头,然后附加额外的引用
out.writeObject(new User(new Date()));
// 假设这是恶意的二进制,即附加恶意对象引用Date
byte[] ref = {0x71, 0, 0x7e, 0 ,5};
bos.write(ref);
// 攻击者从ObjectInputStream中读取User实例,然后读取附加在后面的“恶意编制对象引用Date”
ObjectInputStream in = new ObjectInputStream(new ByteArrayInputStream(bos.toByteArray()));
user = (User) in.readObject();
birthday = (Date) in.readObject();
} catch (Exception e) {
}
}
public static void main(String[] args) {
MutableUser mutableUser = new MutableUser();
User user = mutableUser.user;
Date birthday = mutableUser.birthday;
// 攻击者修改User内部birthday私有域,年份更改为2018
birthday.setTime(2018);
System.out.println(user);
}
}
注:以上代码运行不了,只会加以解释说明而已,具体可以查看《Effective Java》中的代码举例
为了解决此问题,提出第三个安全措施
3)当一个对象被反序列化时,客户端不应该拥有对象的引用,如果哪个域包含了这样的对象引用,如果包含了私有的域(组件),就必须要保护性拷贝(非final域):当User对象在客户端MutableUser反序列化时,客户端拥有 了不该拥有的User私有域Date引用birthday,所以应该在readObject对birthday进行拷贝:
private void readObject(ObjectInputStream inputStream)
throws IOException, ClassNotFoundException {
inputStream.defaultReadObject();
// 保护性拷贝birthday
birthday = new Date(birthday.getTime());
// 约束条件name不能为null
if (name == null || StringUtils.isEmpty(name)) {
throw new NullPointerException("name is null");
}
}
总结:
1)使用readObject其实就跟正常无参数的构造器一样,该满足的约束需要满足,同时必要时进行保护性拷贝。
2)反序列化过程最终会调用readObject方法,如下是一个异常栈的调用关系(代码中故意让readObject方法抛异常):deserialize---->ObjectInputStream.readObject----->ObjectInputStream.readObject0----->......User.readObject

2、使用readResolve增强单例
但是如果Sinleton类实现了序列化,那么它不再是一个Singleton,无论该类使用了默认的序列化形式,还是自定义的序列化形式,还是是否提供显式的readObject方法都没关系。任何一个readObject方法,不管是显式还是默认的,它都会返回一个新建的实例,这个新建的实例不同于该类初始化时创建的实例。
简单的Singleton:
public class Singleton {
private static Singleton INSTANCE= new Singleton();
private Singleton(){};
.....
}
readResolve特性允许使用readObject创建实例代替另一个实例,如果一个类定义了readResolve方法,并且具备正确的声明,那么在反序列化的之后,新建的readResolve方法就会被调用,然后返回的对象引用将被返回,取代新建的对象。
public class Singleton implements Serializable {
private static Singleton INSTANCE= new Singleton();
private Singleton(){};
private Object readResolve(){
return INSTANCE;
}
}
如何正确使用Java序列化?的更多相关文章
- Java序列化与反序列化
Java序列化与反序列化是什么?为什么需要序列化与反序列化?如何实现Java序列化与反序列化?本文围绕这些问题进行了探讨. 1.Java序列化与反序列化 Java序列化是指把Java对象转换为字节序列 ...
- [转] Java序列化与反序列化
原文地址:http://blog.csdn.net/wangloveall/article/details/7992448 Java序列化与反序列化是什么?为什么需要序列化与反序列化?如何实现Java ...
- Java 序列化的高级认识
序列化 ID 问题 情境:两个客户端 A 和 B 试图通过网络传递对象数据,A 端将对象 C 序列化为二进制数据再传给 B,B 反序列化得到 C. 问题:C 对象的全类路径假设为 com.inout. ...
- 【Java】Java 序列化的高级认识
如果你只知道实现 Serializable 接口的对象,可以序列化为本地文件.那你最好再阅读该篇文章,文章对序列化进行了更深一步的讨论,用实际的例子代码讲述了序列化的高级认识,包括父类序列化的问题.静 ...
- 深入理解JAVA序列化
如果你只知道实现 Serializable 接口的对象,可以序列化为本地文件.那你最好再阅读该篇文章,文章对序列化进行了更深一步的讨论,用实际的例子代码讲述了序列化的高级认识,包括父类序列化的问题.静 ...
- Java序列化小结
title: Java序列化小结 date: 2017-05-06 20:07:59 tags: 序列化 categories: Java基础 --- Java序列化就是将一个对象转化成一串二进制表示 ...
- 输入和输出--java序列化机制
对象的序列化 什么是Java对象的序列化? 对象序列化的目标是将对象保存到磁盘上,或允许在网络中直接传输对象.对象序列化机制允许把内存中的Java对象转换成与平台无关的二进制流,从而保存或者传输.其他 ...
- java基础(十)-----Java 序列化的高级认识
将 Java 对象序列化为二进制文件的 Java 序列化技术是 Java 系列技术中一个较为重要的技术点,在大部分情况下,开发人员只需要了解被序列化的类需要实现 Serializable 接口,使用 ...
- Java序列化总结
什么是序列化? 序列化是将对象的状态信息转化为可以存储或传输的形式的过程.在序列化期间,对象将其当前状态写入到临时或持久性存储区.以后可以通过存储区中读取或反序列化对象的状态重新创建对象. 为什么要序 ...
随机推荐
- golang ntp协议客户端
NTP(Network Time Protocol,网络时间协议)是由RFC 1305定义的时间同步协议,用来在分布式时间服务器和客户端之间进行时间同步.NTP基于UDP报文进行传输,使用的UDP端口 ...
- 929. Unique Email Addresses
929. Unique Email Addresses Easy 22766FavoriteShare Every email consists of a local name and a domai ...
- 已知一个字符串S 以及长度为n的字符数组a,编写一个函数,统计a中每个字符在字符串中的出现次数
import java.util.Scanner; /** * @author:(LiberHome) * @date:Created in 2019/3/6 21:04 * @description ...
- 《JavaScript DOM编程艺术》学习笔记(一)
这本书是我听说学习前端基础入门书籍,于是就开始看了,大概是从5月10号开始看的吧,一直看到现在,差不多要看完了,书是挺厚的...286页,不过比起JAVASCRIPT权威指南来说还是差多了,权威指南才 ...
- MyEclipse 10 报错记录
1. js文件:右键 >> MyEclipse >> Exclude From Validation 2. Servlet 警告:Window ==> Preferenc ...
- 模仿bootstrap做的 js tooltip (添加鼠标跟随功能)
主要思路: 使用jquery hover方法,当进入时显示tooltip,移出时隐藏tooltip当设定为鼠标跟随时,使用mousemove事件显示tooltip根据tooltip显示位置设置,计算t ...
- [Swift]LeetCode291. 单词模式 II $ Word Pattern II
Given a pattern and a string str, find if strfollows the same pattern. Here follow means a full matc ...
- [Swift]LeetCode293. 翻转游戏 $ Flip Game
You are playing the following Flip Game with your friend: Given a string that contains only these tw ...
- CentOS随笔——Service与防火墙关闭
Service后台服务管理 基本语法 service 服务名 start 开启服务 service 服务名 stop 关闭服务 service 服务名 restart 重启服务 service 服务名 ...
- Python - Python2与Python3的区别、转换与兼容
区别 Python2.x与Python3.x版本区别:http://www.runoob.com/python/python-2x-3x.html 示例解读Python2和Python3之间的主要差异 ...