Chinese word segment based on character representation learning 论文笔记
|
论文名和编号 |
摘要/引言 |
相关背景和工作 |
论文方法/模型 |
实验(数据集)及 分析(一些具体数据) |
未来工作/不足 |
是否有源码 |
|||
|
问题 |
原因 |
解决思路 |
优势 |
||||||
|
基于表示学习的中文分词 编号:1001-9081(2016)10-2794-05 |
1.为提高中文分词的准确率和未登录词识别率。 |
1.分词后计算机才能得知中文词语的确切边界,进而理解文本中所包含的语义信息。中文分词是中文自然语言处理的一项基础性工作,是中文信息处理技术发展的技术瓶颈。 |
1.使用skip-gram模型将文本中的词映射为高维向量空间中的向量;其次用K-means聚类算法将词向量聚类,并将聚类结果作为条件随机场(CRF)模型的特征进行训练;最后基于该语言模型进行分词和未登录词识别。 |
1.在未利用外部知识的条件下,分词的F值和OOV识别率分别达到了95.67%和94.78%,证明将此地聚类特征加入到条件随机场模型中能有效提高中文短文本的分词性能。 |
1.中文分词和未登录词识别都可以看作一个序列标记任务来完成,应用广泛的序列标注模型主要有隐马尔科夫模型(HMM)、最大熵马尔可夫模型(MEMM)和条件随机场模型(CRF)等。其中CRF比HMM和MEMM更能灵活地选择特征和控制训练数据地拟合程度。但是传统地CRF模型的使用难以避免“词汇鸿沟”,因为其大多使用基于词袋模型的特征表示,另外低频词也容易导致训练不足,及过拟合现象。 2.2006年Hinton等提出深度学习后,从大量未标记文本中学习字的方法已经被证实是对识别未登录词、命名实体识别、词性标注和依存分析有效的了。 |
1.简要说明:先从大量未标记的微博语料中学习中文字符的语义向量,基于这些语义向量作K-means聚类,同时对中文字符进行布朗聚类,然后再将这些字的表示特征应用于CRF模型中进行有监督的中文分词。 2.具体框架:先用空格将原始文本全部分开,然后利用word2vec对处理后的预料进行学习以得到字符的向量表示。接着利用K-means聚类算法得到字的一种聚类类别。最后将两种不同的聚类结果最为CRF的特征训练语言模型。 |
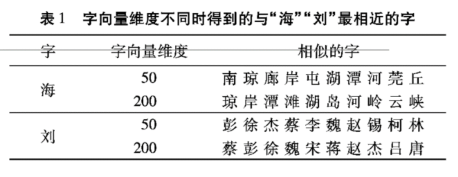
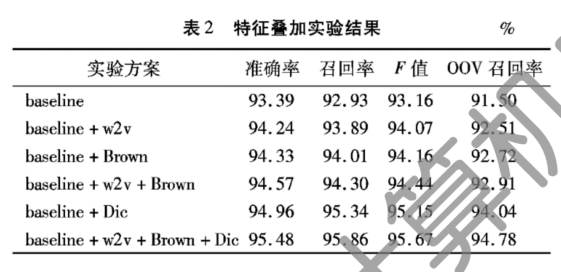
1.数据:采用NLPCC2015中文微博文本分词任务所提供的训练(1.96MB,共10000个句子,215567个词)及测试(662KB,共5000个句子,106843个词)语料。 2.如图2,测试了利用word2vec训练得到的不同维度的字向量以及K-means聚类类别数不同的情况下对分词结果的影响,以分词结果F值为参考。当向量维度d=200,K-means聚类类别数k=400时分词效果较好,F值达到94.07%。F值随着字向量维度d值的增大而趋于平滑,意味着随着向量维度的增加,向量所表示的字的语义信息更为全面和准确,聚类特征表现得更良好。 同时从聚类结果也可看出,党字向量维度增大时,聚类结果中各类别所包含的字的语义表现得更为相近。如表1,当字向量维度较大时,类别内部的字之间的相似度更好,语义更相关。 3.图3对比了布朗聚类与字向量分别为200维和300维时K-means聚类在类别数不同时对分词结果的影响。当类别数k=200时,布朗聚类对分词结果的影响达到峰值,其后分词效果随着k值的增加而递减。整体而言,当类别数k值较小时,布朗聚类效果比K-means聚类效果更好,随着k值的增大,布朗聚类的效果比K-means聚类的效果下降的更快。 4.综上,仅加入字向量的K-means聚类特征时,在d=200,k=400时分词效果达到最佳,仅加入字的布朗聚类特征时,在k=200时CRF分词效果达到最佳。 5.相对于baseline结果,两种不同的字表示方法的加入均对分词结果有积极作用,且布朗聚类优于K-means聚类,两者共同使用时效果优于只使用任意一种的效果,最高值达到94.44%,OOV召回率达到92.91%,相对baseline分别提升了1.28%和1.41%,说明两种不同聚类表示提供了不同的信息,弥补了各自部分的缺点。 6.引用词典知识也可降低未登录词和交叠歧义对分词结果的影响,词典中的词均来源于NLPCC提供的已有正确标记序列的微博语料。结果显示,引用词典特征后,F值和OOV召回率比baseline分别提高了1.99%和2.54%,说明了词典引入的重要性。同时,在引入词典特征的基础上再叠加使用两种字的表示特征后,F值和OOV召回率相比仅加入词典特征再次提高了0.52%和0.74%,体现了字表示对中文分词结果的改善作用。 |
1.对语料中不同长度的字块进行表示学习,如2-gram字块和3-gram字块,将其加入到CRF型中,通过多长度的表示学习来提高分词准确率。 2.增加外部知识学习,扩大语料库,进行开放测试并提升其分词效果。 |
无 |


Chinese word segment based on character representation learning 论文笔记的更多相关文章
- Hierarchical Attention Based Semi-supervised Network Representation Learning
Hierarchical Attention Based Semi-supervised Network Representation Learning 1. 任务 给定:节点信息网络 目标:为每个节 ...
- Deep Learning论文笔记之(八)Deep Learning最新综述
Deep Learning论文笔记之(八)Deep Learning最新综述 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感觉看完 ...
- Deep Learning论文笔记之(六)Multi-Stage多级架构分析
Deep Learning论文笔记之(六)Multi-Stage多级架构分析 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些 ...
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现(转)
Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文, ...
- Deep Learning论文笔记之(一)K-means特征学习
Deep Learning论文笔记之(一)K-means特征学习 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感 ...
- Deep Learning论文笔记之(三)单层非监督学习网络分析
Deep Learning论文笔记之(三)单层非监督学习网络分析 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感 ...
- Spectral Norm Regularization for Improving the Generalizability of Deep Learning论文笔记
Spectral Norm Regularization for Improving the Generalizability of Deep Learning论文笔记 2018年12月03日 00: ...
- [CVPR 2017] Semantic Autoencoder for Zero-Shot Learning论文笔记
http://openaccess.thecvf.com/content_cvpr_2017/papers/Kodirov_Semantic_Autoencoder_for_CVPR_2017_pap ...
- Correlation Filter in Visual Tracking系列二:Fast Visual Tracking via Dense Spatio-Temporal Context Learning 论文笔记
原文再续,书接一上回.话说上一次我们讲到了Correlation Filter类 tracker的老祖宗MOSSE,那么接下来就让我们看看如何对其进一步地优化改良.这次要谈的论文是我们国内Zhang ...
随机推荐
- scala的reduce
spark 中的 reduce 非常的好用,reduce 可以对 dataframe 中的元素进行计算.拼接等等.例如生成了一个 dataframe : //配置spark def getSparkS ...
- Socket网络编程知识点
静态方法 与类无关,不能访问类里的任何属性和方法类方法 只能访问类变量属性@property 把一个方法变成一个静态属性, flight.status @status.s ...
- 【MongoDb入门】15分钟让你敢说自己会用MongoDB了
一.MongDB是什么呢,我该如何下手呢? MongoDB是一个基于分布式文件存储的数据库.由C++语言编写.旨在为WEB应用提供可扩展的高性能数据存储解决方案. 如果小伙伴你的机器上还没有安装Mon ...
- 『Island 基环树直径』
Island(IOI 2008) Description 你准备浏览一个公园,该公园由 N 个岛屿组成,当地管理部门从每个岛屿 i 出发向另外一个岛屿建了一座长度为 L_i 的桥,不过桥是可以双向行走 ...
- java基础(五)-----关键字static
在Java中并不存在全局变量的概念,但是我们可以通过static来实现一个“伪全局”的概念,在Java中static表示“全局”或者“静态”的意思,用来修饰成员变量和成员方法,当然也可以修饰代码块. ...
- Javascript 链式操作以及流程控制
春节过后,感觉过年吃的油腻的食品转化的脂肪都长到 脑子去了. 根本转不动啊 上班第一天 实在是写不动代码了, 顺手打开多天为看的 收件箱,查看查看邮件,看看春节期间 风云变幻的前端圈又有哪些大事发生. ...
- 从锅炉工到AI专家(4)
手写数字识别问题 图像识别是深度学习众多主流应用之一,手写数字识别则是图像识别范畴简化版的入门学习经典案例.在TensorFlow的官方文档中,把手写数字识别"MNIST"案例称为 ...
- .NET快速信息化系统开发框架 V3.2 -> WinForm“组织机构管理”界面组织机构权限管理采用新的界面,操作权限按模块进行展示
对于某些大型的企业.信息系统,涉及的组织机构较多,模块多.操作权限也多,对用户或角色一一设置模块.操作权限等比较繁琐.我们可以直接对某一组织机构进行权限的设置,这样设置后,同一组织机构的用户就可以拥有 ...
- MySQL 索引及查询优化总结
本文由云+社区发表 文章<MySQL查询分析>讲述了使用MySQL慢查询和explain命令来定位mysql性能瓶颈的方法,定位出性能瓶颈的sql语句后,则需要对低效的sql语句进行优化. ...
- JVM(四)垃圾回收的实现算法和执行细节
全文共 1890 个字,读完大约需要 6 分钟. 上一篇我们讲了垃圾标记的一些实现细节和经典算法,而本文将系统的讲解一下垃圾回收的经典算法,和Hotspot虚拟机执行垃圾回收的一些实现细节,比如安全点 ...