大数据 - hadoop基础概念 - HDFS
Hadoop之HDFS的概念及用法
1、概念介绍
Hadoop是Apache旗下的一个项目。他由HDFS、MapReduce、Hive、HBase和ZooKeeper等成员组成。
HDFS是一个高度容错的分布式文件系统。他能够提高吞吐量的数据访问,适合存储海量的大文件。
HDFS由四部分构成:HDFS client、NameNode、DataNode、Secondary NameNode。
2、NameNode
用于维护集群内元数据,也就是保存文件存储位置,集群存储方式为一个大文件存储在多个服务器中,而且为了维护健壮性,一个文件有多个备份,这些备份位置都需要存储在NameNode中。
。。。待编辑
a
sdf
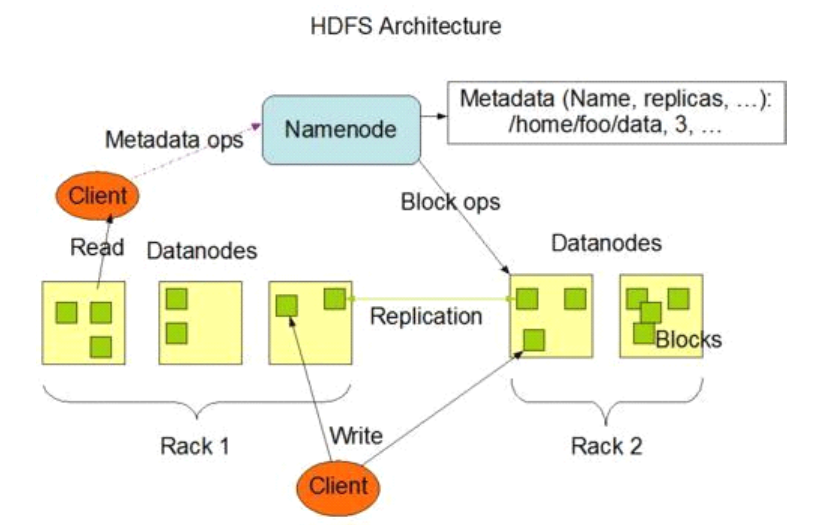
2、操作(此版本为Hadoop2.7,网上说的另一种editlog和fsimage的存储方式为更早版本)
a) 启动HDFS
从fsimage文件中读取元数据信息到内存中。
b) 读文件
1. 扫描HDFS中的元素据信息。客户端访问NameNode,NameNode把DataNode存放数据的位置等信息(存储的元数据信息),从内存中取来。
2. 客户端下载文件。客户端根据NameNode提供的元数据信息,与DataNode简历RPC通信,进行IO操作。
c) 写文件
1. 客户端与NameNode建立通信。判断存储空间的剩余量,判断所存放的文件的存放分布方式。
2. NameNode元数据信息落盘。生成一个editlog文件,保存元数据信息和元数据的操作。
3. 客户端与DadaNode建立通信。进行IO操作
d) NameNode数据固化
NameNode在空闲的时候,会把editlog中的元数据信息和操作信息,合并到fsimage(二进制信息,读写快速)文件中。
每次HDFS启动时,NameNode都会把未合并到fsimage中的数据信息,合并过去。
SecondartNameNode通过RPC通信,把editlog中的元数据信息和操作信息,合并到fsimage文件中,并推送给NameNode。
大数据 - hadoop基础概念 - HDFS的更多相关文章
- 大数据Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
微信公众号[程序员江湖] 作者黄小斜,斜杠青年,某985硕士,阿里 Java 研发工程师,于 2018 年秋招拿到 BAT 头条.网易.滴滴等 8 个大厂 offer,目前致力于分享这几年的学习经验. ...
- 大数据-hadoop生态之-HDFS
一.HDFS初识 hdfs的概念: HDFS,它是一个文件系统,用于存储文件,通过目录树定位文件,其次,他是分布式的,由很多服务器联合起来 实现功能,集群中的服务器各有各自的角色 HDFS设计适合一次 ...
- 大数据Hadoop基础入门到精通
1.hadoop前世今生: 1) 搜索引擎:网络爬虫+索引服务器(生成索引+检索) 2) Doung Cutting 3) Nutch a.分布式存储 b.分布式计算 4)GFS论文 doung c ...
- 我要进大厂之大数据Hadoop HDFS知识点(1)
01 我们一起学大数据 老刘今天开始了大数据Hadoop知识点的复习,Hadoop包含三个模块,这次先分享出Hadoop中的HDFS模块的基础知识点,也算是对今天复习的内容进行一次总结,希望能够给想学 ...
- 云计算分布式大数据Hadoop实战高手之路第七讲Hadoop图文训练课程:通过HDFS的心跳来测试replication具体的工作机制和流程
这一讲主要深入使用HDFS命令行工具操作Hadoop分布式集群,主要是通过实验的配置hdfs-site.xml文件的心跳来测试replication具体的工作和流程. 通过HDFS的心跳来测试repl ...
- Hadoop基础概念介绍
基于YARN的配置信息, 参见: http://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-yarn/ hadoop入门 - 基础概念 ...
- 大数据Hadoop——初识Hadoop
Hadoop简介 官方网站: http://hadoop.apache.org/ 中文网站: http://hadoop.apache.org/docs/r1.0.4/cn/ Hadoop设计来源 ...
- 14周事情总结-机器人-大数据hadoop
14周随着考试的进行,其他该准备的事情也在并行的处理着,考试内容这里不赘述了 首先说下,关于机器人大赛的事情,受益颇多,机器人的制作需要机械和电控两方面 昨天参与舵机的测试,遇到的问题:舵机不动 排查 ...
- 成都大数据Hadoop与Spark技术培训班
成都大数据Hadoop与Spark技术培训班 中国信息化培训中心特推出了大数据技术架构及应用实战课程培训班,通过专业的大数据Hadoop与Spark技术架构体系与业界真实案例来全面提升大数据工程师 ...
随机推荐
- img标签和 background 属性的使用分析
在网页布局中引入图片,最常用的两个就是 img 标签和 background 属性了.但何时使用 img 标签,何时使用 backround 背景图像呢? <img> 标签定义 HTML ...
- nginx日志相关运维操作记录
在分析服务器运行情况和业务数据时,nginx日志是非常可靠的数据来源,而掌握常用的nginx日志分析命令的应用技巧则有着事半功倍的作用,可以快速进行定位和统计. 1)Nginx日志的标准格式(可参考: ...
- spiflash
1.SPI Flash (即SPI Nor Flash)是Nor Flash的一种:2.NOR Flash根据数据传输的位数可以分为并行(Parallel)NOR Flash和串行(SPI)NOR F ...
- docker 安装redis , 让宿主机可以访问
1, docker 拉去最新版本的redis docker pull redis #后面可以带上tag号, 默认拉取最新版本 2, docker安装redis container 安装之前去定义我们的 ...
- Spvmn测试环境搭建及其安全性讨论
一.说明 这几天都在做设备的协议分析,然后看到有个叫Spvmn的不懂要怎么操作才能触发其操作过程,问了测试部的同事说也没有测试文档,自己研究了一下这里做个记录. 按我现在理解,各厂商有自己的私有协议. ...
- MyBatis动态创建表
转载请注明出处:https://www.cnblogs.com/Joanna-Yan/p/9187538.html 项目中业务需求的不同,有时候我们需要动态操作数据表(如:动态建表.操作表字段等).常 ...
- C++文件输入和创建
#include <fstream> //头文件 ifstream inf; ofstream ouf; inf.open("zy4.txt", ios::out); ...
- java中的多线程入门
进程:一个进程包括由操作系统分配的内存空间,包含一个或多个线程.一个线程不能独立的存在,它必须是进程的一部分.一个进程一直运行,直到所有的非守护线程都结束运行后才能结束. 而多线程的好处就是效率高,充 ...
- REST(Representational state transfer)的四个级别以及HATEOAS介绍
Rest RES(Representational state transfer):表现层状态转移.其实它省略了主语,「表现层」其实指的是「资源」的「表现层」,所以通俗来讲就是:资源在网络中以某种表现 ...
- css3动画怎样能从下往上慢慢升上去
<!DOCTYPE html><html><head> <style> div { width:100px; height:100px; backgro ...