R语言学习——因子
变量可分为名义型变量、有序型变量或者连续型变量。名义型变量是没有顺序之分的类别变量,如糖尿病类型Diabetes(Type1、Type2),即使在数据中Type1编码为1而Type2编码为2,这也并不表示二者有序。有序变量表示一种顺序关系,而非数量关系,如病情S Status(poor、improved、excellent),显然病情为poor(较差)的病人的状态不如improved(病情好转)的病人,但我们并不知道相差多少。连续型变量可以呈现为某个范围内的任意值,并同时表示了顺序和数量,例如年龄,他能够表示14或者30这样的值以及期间的其他任意值,很清楚15岁的人比14岁的人年长1岁。
类别(名义型)变量和有序类别(有序型)变量在R中称为因子(factor)。因子在R中非常重要,它决定了数据的分析方式及如何进行视觉呈现。
函数factor()以一个整数向量的形式存储类别值,取值范围是[1...k](其中k是名义型变量中唯一值的个数),同时一个由字符串(原始值)组成的内部向量将映射到这些整数上,例如:
> diabetes<-c("Type1","Type2","Type1","Type2")
> diabetes<-factor(diabetes)
> diabetes
[1] Type1 Type2 Type1 Type2
Levels: Type1 Type2
语句diabetes<-factor(diabetes)将向量存储为(1,2,1,1),并在内部将其关联为1=Type1,和2=Type2(具体赋值顺序根据字母顺序而定)。针对向量diabetes 进行的任何分析都会将其作为名义型变量对待,并自动选择适合这一测量尺度的统计方法。
若果要表示有序向量,则需要为函数factor()指定参数ordered=TRUE。给定向量:
> status<-c("Poor","Improved","Excellent","Poor")
> status<-factor(status,ordered = T)
> status
[1] Poor Improved Excellent Poor
Levels: Excellent < Improved < Poor
语句status<-factor(status,ordered = T)将此向量编码为(3,2,1,3),并在内部将其关联为1=Excellent、2=Improved以及3=Poor。但这里对于字符型向量,因自水平默认以字母顺序创建,这对于因子status是有意义的,因为“Excellent”“Improved”“Poor”的排序方式恰好与逻辑顺序一致。如果“Poor”被编码为“Ailing”则顺序将为“Ailing”“Excellent”“Improved”,与逻辑不符;如果理想中的顺序是“Poor”“Improved”“Excellent”,则会出现类似问题。因此可以通过制定levels选项来覆盖默认排序。例如:
> status<-factor(status,ordered = T,levels=c("Poor","Improved","Excellent"))
> status
[1] Poor Improved Excellent Poor
Levels: Poor < Improved < Excellent
数值型变量可用levels和labels参数来编码成因子。如果男性编码被编码成1,女性被编码成2,则代码如下:
> sex<-c(1,2)
> sex<-factor(sex,levels=c(1,2),labels = c("Male","Female"))#注意标签的顺序必须与水平一致
> sex
[1] Male Female
Levels: Male Female
以下代码显示了普通因子与有序因子的不同是如何影响数据分析的
> patientID<-c(1,2,3,4)
> ge<-c(25,34,28,52)
> diabetes<-c("Type1","Type2","Type1","Type1")
> status<-c("Poor","Improved","Excellent","Poor")
> diabetes<-factor(diabetes)
> status<-factor(status,ordered = T)
> patientdata<-data.frame(patientID,age,diabetes,status)
> str(patientdata)#显示对象的结构
'data.frame': 4 obs. of 4 variables:
$ patientID: num 1 2 3 4
$ age : num 25 34 28 52
$ diabetes : Factor w/ 2 levels "Type1","Type2": 1 2 1 1
$ status : Ord.factor w/ 3 levels "Excellent"<"Improved"<..: 3 2 1 3
> summary(patientdata)#显示对象的统计概要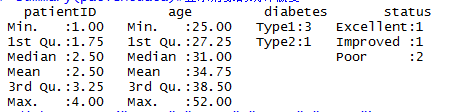
> diabetes2<-c("Type1","Type2","Type1","Type1")
> status2<-c("Poor","Improved","Excellent","Poor")
> patientdata2<-data.frame(patientID,age,diabetes2,status2)
> str(patientdata2)#显示对象的结构
'data.frame': 4 obs. of 4 variables:
$ patientID: num 1 2 3 4
$ age : num 25 34 28 52
$ diabetes2: Factor w/ 2 levels "Type1","Type2": 1 2 1 1
$ status2 : Factor w/ 3 levels "Excellent","Improved",..: 3 2 1 3
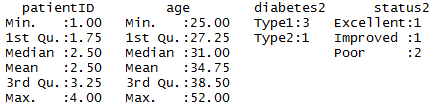
> summary(patientdata2)#显示对象的统计概要
> status<-factor(status,ordered = T,levels=c("Poor","Improved","Excellent"))
> patientdata<-data.frame(patientID,age,diabetes,status)
> str(patientdata)#显示对象的结构
'data.frame': 4 obs. of 4 variables:
$ patientID: num 1 2 3 4
$ age : num 25 34 28 52
$ diabetes : Factor w/ 2 levels "Type1","Type2": 1 2 1 1
$ status : Ord.factor w/ 3 levels "Poor"<"Improved"<..: 1 2 3 1
> summary(patientdata)#显示对象的统计概要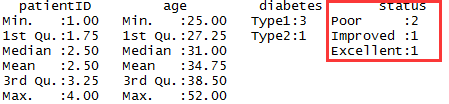
首先,以向量形式输入数据;然后,将diabetes和status分别指定为一个普通因子和一个有序型因子;最后,将数据合并为一个数据框。函数str(object)可以提供R中的某个对象(本例为数据框)的信息,它清楚的显示diabetes是一个因子,而status是一个有序型因子,以及此数据框在内部是如何进行编码的。函数summary()会区别对待各个变量,它显示了连续型变量age的最小值、最大值、均值和四分位数,并显示了类别型变量diabetes和status(各水平)的频数值。
R语言学习——因子的更多相关文章
- R语言学习 第四篇:函数和流程控制
变量用于临时存储数据,而函数用于操作数据,实现代码的重复使用.在R中,函数只是另一种数据类型的变量,可以被分配,操作,甚至把函数作为参数传递给其他函数.分支控制和循环控制,和通用编程语言的风格很相似, ...
- R语言学习笔记:因子
R语言中的因子就是factor,用来表示分类变量(categorical variables),这类变量不能用来计算而只能用来分类或者计数. 可以排序的因子称为有序因子(ordered factor) ...
- R语言学习4:函数,流程控制,数据框重塑
本系列是一个新的系列,在此系列中,我将和大家共同学习R语言.由于我对R语言的了解也甚少,所以本系列更多以一个学习者的视角来完成. 参考教材:<R语言实战>第二版(Robert I.Kaba ...
- R语言学习笔记之: 论如何正确把EXCEL文件喂给R处理
博客总目录:http://www.cnblogs.com/weibaar/p/4507801.html ---- 前言: 应用背景兼吐槽 继续延续之前每个月至少一次更新博客,归纳总结学习心得好习惯. ...
- R语言学习笔记(二)
今天主要学习了两个统计学的基本概念:峰度和偏度,并且用R语言来描述. > vars<-c("mpg","hp","wt") &g ...
- R语言学习笔记:小试R环境
买了三本R语言的书,同时使用来学习R语言,粗略翻下来感觉第一本最好: <R语言编程艺术>The Art of R Programming <R语言初学者使用>A Beginne ...
- R语言学习路线和常用数据挖掘包(转)
对于初学R语言的人,最常见的方式是:遇到不会的地方,就跑到论坛上吼一嗓子,然后欣然or悲伤的离去,一直到遇到下一个问题再回来.当然,这不是最好的学习方式,最好的方式是——看书.目前,市面上介绍R语言的 ...
- R语言学习笔记︱Echarts与R的可视化包——地区地图
笔者寄语:感谢CDA DSC训练营周末上完课,常老师.曾柯老师加了小课,讲了echart与R结合的函数包recharts的一些基本用法.通过对比谢益辉老师GitHub的说明文档,曾柯老师极大地简化了一 ...
- R语言学习 第八篇:常用的数据处理函数
Basic包是R语言预装的开发包,包含了常用的数据处理函数,可以对数据进行简单地清理和转换,也可以在使用其他转换函数之前,对数据进行预处理,必须熟练掌握常用的数据处理函数,本文分享在数据处理时,经常使 ...
随机推荐
- CentOS7 systemctl tomcat常用配置
开始配置tomcat 1.环境准备,安装java 在生产环境上,我一般使用oracle java,不使用openjdk,所以先卸载系统自带的openjdk yum remove java 下载orac ...
- Java基础12:深入理解Class类和Object类
更多内容请关注微信公众号[Java技术江湖] 这是一位阿里 Java 工程师的技术小站,作者黄小斜,专注 Java 相关技术:SSM.SpringBoot.MySQL.分布式.中间件.集群.Linux ...
- SpringCloud系列——Zuul 动态路由
前言 Zuul 是在Spring Cloud Netflix平台上提供动态路由,监控,弹性,安全等边缘服务的框架,是Netflix基于jvm的路由器和服务器端负载均衡器,相当于是设备和 Netflix ...
- .Net语言 APP开发平台——Smobiler学习日志:基于Access数据库的Demo
说明:该demo是基于Access数据库进行客户信息的新增.查看.编辑 新增客户信息和客户列表 Demo下载:https://github.com/comsmobiler/demo-videos 中 ...
- mongoDB连接数据库
package mongod; import java.util.List; import java.util.ArrayList; import org.bson.types.*; import c ...
- Java开发笔记(三十三)字符包装类型
正如整型int有对应的包装整型Integer那样,字符型char也有对应的包装字符型Character.初始化字符包装变量也有三种方式,分别是:直接用等号赋值.调用包装类型的valueOf方法.使用关 ...
- Apollo配置中心动态刷新日志级别
Apollo配置中心动态刷新日志级别 添加次配置后,当在apollo上面调整日志级别不需要重启服务器,马上就能生效 /** * 结合apollo动态刷新日志级别 * @author: nj * @da ...
- C# 消息队列-Microsoft Azure service bus 服务总线
先决条件 Visual Studio 2015或更高版本.本教程中的示例使用Visual Studio 2015. Azure订阅. 注意 要完成本教程,您需要一个Azure帐户.您可以激活MSDN订 ...
- Xamarin for Visual Studio下载后的文件路径
Xamarin for Visual Studio的下载很纠结,在官网上不知道如何下载?现在找到一个办法:可以先在网上找一个低版本的之后安装,然后利用VS更新.利用VS更新这里也遇到了问题,下载成功之 ...
- asp.net/wingtip/显示数据和详细信息
前边我们的工作处于wingtip工程基础建设阶段,先是建立了“数据访问层”,然后设计建设了“UI和导航”的框架,接下来要充实工程的内容,显示“数据和详细信息”. 一. 添加数据控件(Data Cont ...