java 源码编译
Java语言的“编译期”其实是一段“不确定”的操作过程,因为它可能是指一个前端编译器(叫“编译器的前段”更准确)——把*.java文件转变成*.class文件的过程;
也可能是虚拟机的后端运行期编译器(JIT)把字节码转变成机器码的过程;还可能是指静态提前编译器(AOT编译器)直接把*.java文件编译成本地机器码的过程。
Javac编译器
Javac编译器不像HotSpot虚拟机那样使用C++语言实现,它本身就是一个又java语言编写的程序。java虚拟机并没有对如何把Java源码文件转变为Class文件
的编译过程进行十分严格的定义,这导致Class编译在某种程度上与具体JDK实现相关。从Sun javac来看,编译过程大致可以分为3个过程,分别是:
- 解析与填充过程
- 插入式注解处理i的注解处理过程
- 分析与字节码生成过程
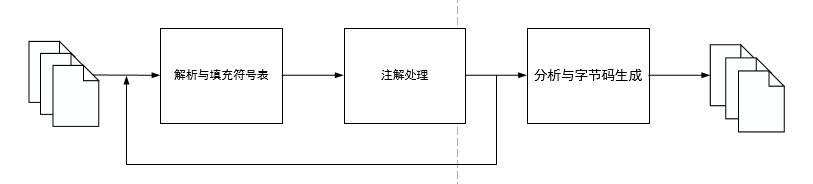
Javac的编译过程
解析与填充过程
解析步骤包括了经典程序编译原理中的词法分析和语法分析两个过程
1、词法、语法分析
词法分析是将源代码的字符流转变为标记(Token)集合,单个字符是程序编写过程的最小元素,而标记则是编译过程的最小元素。关键字、变量名、字面量、运算符
都可以成为标记。如“int a = b + 2” 这句代码包含了6个标记。在Javac源码中,词法分析过程由com.sun.tools.javac.parser.Scanner类来实现。
词法分析是根据Token序列构造抽象语法树的过程,抽象语法树(Abstract Syntax Tree AST)是一种用来描述程序代码语法结构的树形表示方式,语法树的每一个节点
都代表着程序中的一个语法结构,例如包、类型、修饰符、运算符、接口、返回值甚至代码注释都可以是一个语法结构。

在Javac源码中,语法分析过程由com.sun.tools.javac.parser.Parser类实现,这个阶段产出的抽象语法树由com.sun,tools.javac.tree.JCTree类表示,经过这个步骤之后
编译器基本不会对源码文件进行操作了,后续操作都建立在抽象语法树之上。
2、填充符号表
符号表,是由一组符号地址和符号信息构成的表格,符号表中所登记的信息在编译的不同阶段都要用到。在语义分析中,符号表所登记的内容将用于语义检查和产生中间
代码。在目标代码生成阶段,对符号名进行地址分配时,符号表是地址分配的依据。在javac源代码中,填充符号表的过程有com.sun.tools.javac.com.Enter类实现,此过程的
出口就是一个待处理列表,包含了每一个编译单元的抽象语法树的顶级节点,以及package-info.java的顶级节点
注解处理器
注解与普通的Java代码一样,是在运行期间发挥作用的。插入式注解处理器在编译期间对注解进行处理,我们可以把它看做是一组编译器的插件,在这些插件里面,可以读取,
修改、添加抽象语法树中的任意元素。如果这些插件在处理注解期间对语法树进行了修改,编译器就将回到解析及填充符号表的过程重新处理,直到所有插入式注解处理器都没有
再对语法树进行修改为止,每一次循环称为一个Round。
语义分析与字节码生成
语法分析之后,编译器获得了程序代码的抽象语法树表示,语法树能表示一个结构正确的源程序的抽象,但无法保证源程序是符合逻辑的。而语义分析的主要任务是对结构上
正确的源程序进行上下文有关性质的审查。
1、标注检查
Javac的编译过程中,语义分析过程分为标注检查以及数据及控制流分析两个步骤。标注检查步骤检查的内容包括诸如变量使用前会否已经被声明、变量与复制之间的数据
类型是否能够匹配等。在标注检查步骤中,还有一个重要的动作称为常量折叠,如果我们在代码中写了如下定义:
int a = 1 + 2;
那么在语法树上仍然能看到字面量 “1”、“2”以及操作符“+”,但是在经过常量折叠之后,它们将会被折叠为字面量“3”。如图:

由于编译期间进行了常量折叠,所以代码里面定义“a=1+2”比起直接定义“a=3”,不会增加程序运行期哪怕一个CPU指令运算符。
2、数据及控制流分析
数据及控制流分析是对程序上下文逻辑更进一步的验证,它可以检查出诸如程序局部变量在使用前是否有复制、方法的每条路径是否都有返回值、是否所有的受检查
异常都被正确处理等问题。编译器的数据及控制流分析与类加载时的数据及控制流分析的目的基本上是一致的,但校验范围有所区别,有一些校验项只有在编译器或运行
期才能进行。
//方法一带有final修饰
public void foo(final int arg) {
final int var = 0;
//do something
} //方法二没有final修饰
public void foo(int arg) {
int var=0;
//do something
}
第一个方法的参数和局部变量定义使用了final修饰符,而第二种方法则没有,在代码编写时程序肯定会受到final修饰符的影响,不能再改变arg和var变量的值,但是这两段代码
编译出来的Class文件是没有任何一点区别的。局部变量与字段是有区别的,它在常量池中没有CONSTANT_Fieldref_info的符号引用,自然没有访问标志(Access_Flags)的
信息,甚至连名称都不会保留下来(取决于编译时的选项),自然在class文件中不可能知道一个局部变量是不是声明为final了,因此,将局部变量声明为final,对运行期是没有
什么影响的,变量的不变性仅仅由编译器在编译期间保障。
3、语法糖
语法糖,也称为糖衣语法,指在计算机语言中添加某种语法,这种语法对语言功能并没有影响,但是更方便程序员使用。通常来说,使用语法糖能够增加成的可读性,从
而减少程序代码出错的机会。Java中最常用的语法糖主要是泛型、变长参数、自动装箱、拆箱等。虚拟机运行时不支持这些语法,它们在编译阶段还原回简单的基础语法结构,
这个过程称为解语法糖。
4、字节码生成
字节码生成是Javac编译过程的最后阶段,字节码生成阶段不仅仅是把前面各个步骤所生成的信息(语法树、符号表)转化成字节码写到磁盘中,编译器还进行了少量的
代码添加和转换工作。
例如,实例构造器<init>()方法和类构造器<clinit>()方法就是在这个阶段添加到语法树之中的(注意,这里的实例构造器并不是指默认构造函数,如果用户代码中没有
任何构造函数,那编译器将会添加一个没有参数的、访问行与当前类一直的默认构造函数,这个工作在填充符号表阶段就已经完成),这两个构造函数的产生过程实际上是一个
代码收敛的过程,编译器会把语句块、变量初始化、调用父类的实例构造器(仅仅是实例构造器,<clinit>()方法中无需调用父类的<clinit>(),虚拟机会自动保证父类构造器的执行
但在<clinit>()方法中经常会生成调用java.lang.Object的<init>()方法的代码)等操作收敛到<init>()和<clinit>到方法之中,并且保证一定是按照先执行父类的实例构造器,然后初始化
变量,最后执行语句块的顺序进行。
Java语法糖的味道
几乎每种语言或多或少都提供过一些语法糖来方便程序员的代码开发,这些语法糖虽然不会提供实质性的功能改进,但是它们或能提高效率,或能提升语法的严谨性,或能减少编码
出错的机会。它可以看做是编译器实现的一些“小把戏”,这些“小把戏”可能使效率提升,但是我们也应该去了解这些“小把戏”的真实世界。
泛型与类擦除
泛型的本质是参数化类型的应用,也就是说所操作的数据类型被指定为一个参数。这种参数类型可以用在类、接口和方法的创建中,分别称为泛型类、泛型接口、泛型方法。
Java语言中的泛型它只在源码中存在,在编译后的字节码文件中,就已经替换为原来的原生类型了,并且在相应的地方插入了强制类型代码,因此,对于运行期的Java语言来说
ArrayList<int>与ArrayList<String>就是同一个类,所以泛型技术实际上是java语言的一颗语法糖,Java语言中的泛型实现方法称为类型擦除,基于这种方法实现的泛型称为伪泛型。
可以通过Signature、LocalVariableTable等新的属性用于解决伴随泛型而来的参数的识别问题,Signature是其中最重要的一个属性,它的作用就是存储一个方法在字节码层面的
特性签名,这个属性中保存的参数类型并不是原生类型,而是包括了参数化类型信息。Signature属性的出现我们还可以得出结论,擦除法所谓的擦除,仅仅是对方法的Code属性
中的字节码进行了擦除,实际上元数据还是保留了泛型信息,这也是我们能通过反射手段获得参数化类型的根本依据。
自动装箱、拆箱与遍历循环
自动装箱、拆箱在编译之后被转化成了对应的包装和还原方法。如Integer.valueOf()与Integer.intValue()方法。而边儿循环则把代码还原成了迭代器的实现,这也是为何遍历循环
需要被遍历的类实现Iterator接口的原因。最后看变长参数,它在调用的时候变成了一个数组类型的参数,在变长参数出现之前,就是使用数组来完成类似功能。
注意:包装类的“==”运算在不遇到算数运算的情况下不会自动拆箱,以及它们equals()方法不处理数据转型的关系。
条件编译
许多程序设计语言都提供了条件编译的途径,如C、C++中使用预处理器指示符(#ifdef)来完成条件编译。C、C++的预处理器最初的任务是解决编译时的代码依赖关系,而在
语言中并没有使用预处理器,因为java语言天然的编译方式(编译器并非一个个地编译Java文件,而是将所有编译单元的语法树顶级节点输入到待处理列表后再进行编译,因此各个
文件之间能够相互提供符号信息)。无须使用预处理器。那java语言是否有办法实现条件编译呢?当然可以,方法就是使用条件为常量的if语句。如下代码:
public static void main(String[] args) {
if(true) {
System.out.println("block1");
} else {
System.out.println("block2");
}
}
上述代码编译后Class文件的反编译结构:
public static void main(String[] args) {
System.out.println("block1");
}
只能使用条件为常量的if语句才能达到上述效果。如果使用常量与其他带有条件判断能力的语句搭配,则可能在控制流分析中提示错误,被拒绝编译。
Java语言中的条件编译的实现也是java语言的一颗语法糖,Java语言还有不少其他的语法糖,如内部类、枚举、断言、try语句中定义和关闭资源等。
解释器与编译器
Java程序最初是通过解释器进行解释执行的,当虚拟机发现某个方法或代码块的运行特别频繁时,就会把这些代码认为“热点代码”。为了提高热点代码的执行效率,
在运行时,虚拟机将会把这些代码编译成与本地平台相关的机器码,并进行优化完成这个任务的编译器称为即使编译器。
解释器与编译器两者各有优势:当程序需要迅速启动和执行的时候,解释器可以首先发挥作用,省去编译的时间,立即执行。在程序运行后,随着时间的推移,编译器发挥
作用,把越来越多的代码编译成本地代码之后,可以获取更高的执行效率。当程序运行环境中内存资源限制较大,可以使用解释执行节约内存,反之可以使用编译执行来提升效率。
HotSpot虚拟机中内置了两个即时编译器,分别成为Client Compiler和Server Compiler,简称为C1编译器和C2编译器。目前主流的HotSpot虚拟机,默认采用解释器与其中的
一个编译器直接配合的方式。程序使用哪个编译器,取决于虚拟机运行的模式,HotSpot虚拟机会根据自身版本与宿主机器的硬件性能自动选择运行模式,用户可以使用“-client”或
“-server”参数去强制指定虚拟机运行在Client模式或Server模式。
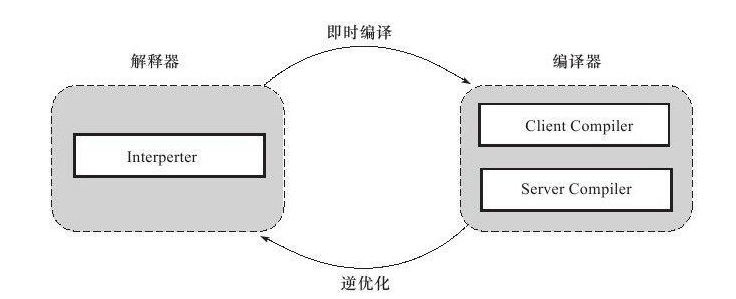
由于即时编译器编译本地代码需要占用程序运行时间,要编译出优化程度更高的代码所花费时间可能较长;而且想要编译出优化程度更高的代码,解释器可能还要替编译器收集
性能监控信息,这对解释执行的速度有影响。为了在程序启动相应速度与运行效率之间达到最佳平衡,HotSpot虚拟机还会逐渐启用分层编译的策略。
编译对象与触发条件
在运行过程中会被即时编译的“热点代码”有两类,即:
- 被多次调用的方法
- 被多次执行的循环体
对于第一种情况,由于是由方法调用触发的编译,因此编译器理所当然地会以整个方法作为编译对象,这种编译也是虚拟机中标准的JIT编译方式。而后一种情况,尽管
编译动作是循环体所触发的,但编译器依然以这个方法作为编译对象。这种编译方式因为编译发生在方法执行过程之中,因此形象地称之为栈上替换。
编译优化技术
Java程序员有一个共识,以编译方式执行本地代码比解释方式更快,之所以有这样的共识,除去虚拟机解释执行字节码时额外消耗时间的原因外,还有一个重要原因就是
虚拟机设计团队把对代码的所有优化措施都集中在了即时编译器之中了。因此编译器产生的本地代码会比Javac产生的字节码更加优秀。
java 源码编译的更多相关文章
- JVM之---Java源码编译机制
Sun JDK中采用javac将Java源码编译为class文件,这个过程包含三个步骤: 1.分析和输入到符号表(Parse and Enter) Parse过程所做的工作有词法和语法分 ...
- Android反编译(一)之反编译JAVA源码
Android反编译(一) 之反编译JAVA源码 [目录] 1.工具 2.反编译步骤 3.实例 4.装X技巧 1.工具 1).dex反编译JAR工具 dex2jar http://code.go ...
- 源码编译OpenJdk 8,Netbeans调试Java原子类在JVM中的实现(Ubuntu 16.04)
一.前言 前一阵子比较好奇,想看到底层(虚拟机.汇编)怎么实现的java 并发那块. volatile是在汇编里加了lock前缀,因为volatile可以通过查看JIT编译器的汇编代码来看. 但是原子 ...
- 自己动手实现springboot运行时执行java源码(运行时编译、加载、注册bean、调用)
看来断点.单步调试还不够硬核,根本没多少人看,这次再来个硬核的.依然是由于apaas平台越来越流行了,如果apaas平台选择了java语言作为平台内的业务代码,那么不仅仅面临着IDE外的断点.单步调试 ...
- 【JDK命令行 一】手动编译Java源码与执行字节码命令合集(含外部依赖引用)
写作目标 记录常见的使用javac手动编译Java源码和java手动执行字节码的命令,一方面用于应对 Maven 和 Gradle 暂时无法使用的情况,临时生成class文件(使用自己的jar包):另 ...
- Android stdio Apktool源码编译
Android Apktool源码编译 标签(空格分隔): Android Apktool 源码编译 需求 习惯NetBeans调试smali需要用Apktool反编译apk,需要用-d的参数才能生成 ...
- Hadoop源码编译过程
一. 为什么要编译Hadoop源码 Hadoop是使用Java语言开发的,但是有一些需求和操作并不适合使用java,所以就引入了本地库(Native Libraries)的概念,通 ...
- 如何阅读Java源码 阅读java的真实体会
刚才在论坛不经意间,看到有关源码阅读的帖子.回想自己前几年,阅读源码那种兴奋和成就感(1),不禁又有一种激动. 源码阅读,我觉得最核心有三点:技术基础+强烈的求知欲+耐心. 说到技术基础,我打个比 ...
- Apache Spark源码走读之9 -- Spark源码编译
欢迎转载,转载请注明出处,徽沪一郎. 概要 本来源码编译没有什么可说的,对于java项目来说,只要会点maven或ant的简单命令,依葫芦画瓢,一下子就ok了.但到了Spark上面,事情似乎不这么简单 ...
随机推荐
- 业务与IT技术
最近听一个同事又再次提问关于业务比技术重要,是真的吗? 今天我们再来看一下. 一,什么是业务? 业务意指某种有目的的工作或工作项目.技术可以指人类对机器.硬件或人造器皿的运用,但它也可以包含 ...
- nginx+uwsgi部署django项目
1.django项目部署前需要生成admin的静态资源文件 (1)生成admin的静态资源文件 # 关闭debug模型 DEBUG = False # 允许所有域名访问 ALLOWED_HOSTS = ...
- windows10下安装kali子系统
写在前面 为什么我会想到在窗下装一个卡利 作为一个小白,平时做CTF题的时候,有时会用到python2.7环境(比如一些脚本需要,还有窗户下用的SqlMap的话,好像只支持在python2.7,之前被 ...
- java网络爬虫基础学习(一)
刚开始接触java爬虫,在这里是搜索网上做一些理论知识的总结 主要参考文章:gitchat 的java 网络爬虫基础入门,好像要付费,也不贵,感觉内容对新手很友好. 一.爬虫介绍 网络爬虫是一个自动提 ...
- 017_python常用小技巧
一.进行十六进制运算 print(hex(int("6500000001", 16) - int("640064c6e7",16))) 0xff9b391a
- Elastic Stack-Elasticsearch使用介绍(六)
一.前言 很久没有更新博客,实在对不住大家.从10月份假期以后我就开始优化程序,来应对双11,这段时间确实很忙,不好意思.好在优化效果还不错,我负责的模块在双11期间没有任何大问题,整体效果还 ...
- ABP之启动配置
ASP.NET Boilerplate提供了在StartUp中配置其模块的基础设施和模型. 配置ASP.NET Boilerplate 配置ABP是在模块的PreInitialize 方法中做的,如下 ...
- AtCoder Grand Contest 032-B - Balanced Neighbors (构造)
Time Limit: 2 sec / Memory Limit: 1024 MB Score : 700700 points Problem Statement You are given an i ...
- Windows之常用命令
1. 重启/关机 shutdown命令 #关机 shutdown -s -t -f #重启 shutdown -r -t //30秒之后,重启 00是立即 #注销 shutdown -l -t #休眠 ...
- dataTable tab栏切换时错位解决办法
做后台管理类网站肯定要写列表,首选dataTable,功能强大 最近在做一个tab栏切换时发现了一个很诡异的事情:表头错位了! 主要时因为当table被隐藏后,table的header宽度会计算错乱, ...