mongodb细讲
一、 关系型数据库(sql)
1.建表



二、非关系型数据库(nosql 98提出的概念)
1.不用建库建表数据直接存入就可

优缺点:
关系型:节约资源(学生姓名和课程名不重复出现),开发不方便(需先建库建表,外键等)
非关系型:浪费资源(学生姓名和课程名重复出现),开发方便(不需要建库建表,数据直接存)
开发常用关系型,爬虫常用非关系型
三、Ubuntu安装: sudo apt-get install mongodb
Centos安装:sudo yum install mongodb
四、mongodb基本操作:
1.启动:sudo service mongodb start
2.停止:sudo service mongodb stop
3.重启:sudo service mongodb restart
4.进入客户端:mongo
出现上图代表正确进入
5.退出客户端:exit、ctrl + c
6.默认端口:27017
7.默认配置文件位置:/etc/mongod.conf
8.默认日志位置:/var/log/mongodb/mongod.log
9.查看帮助命令:mongod -help (或进入mongo直接 help)
10.关于database的基本命令:
a.查看所有的库:show database、 show databases、show dbs
b.使用一个库:use 库名
c.查看当前库名:db
d.切换数据库:use 库名
e.删除当前数据库:db.dropDatabase()
f.第一次向数据库中加入数据时,数据库自动创建。
11.关于集合的基本命令:
a.不用手动创建集合,向不存在的集合第一次加入数据时,集合会自动创建出来

如图集合会自动创建
b.手动创建集合:
db.createCollection('stu')
db.createCollection(name, options)
db.createCollection('stu', {capped:true, size:10})
参数capped:默认为false表示不设置上限,当值为true表示设置上限,参数size当capped为true时,需要指定此参数,表示上限大小,单位为字节,如果数据超过上限,会将之前的数据覆盖。
c.查看集合:show collections
d.删除集合:db.集合名.drop()
12.数据类型:
ObjectId:文档id
String 字符串,必须是有效的utf-8
Boolean 存储一个布尔值 true false
Integer 整数 32位或64位取决于服务器
Double 浮点型
Arrays 数组,列表,多个值存储到一个键
Object 一个值就是一个文档
Null 存储Null值
Timestamp 时间戳,表示从1970.1.1到现在的总秒数
Date 存储当前的日期或时间
ObjectId 是一个12字节的十六进制数,前四个字节是当前的时间戳,接下来三个字节是机器的id,接下来的两个字节是mongodb的服务进程id最后三个字节是简单增量值
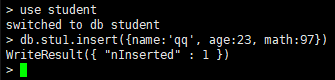
13.数据插入:
db.集合名.insert(数据)
db 指的是本数据库
集合名 相当于mysql中的表 例:
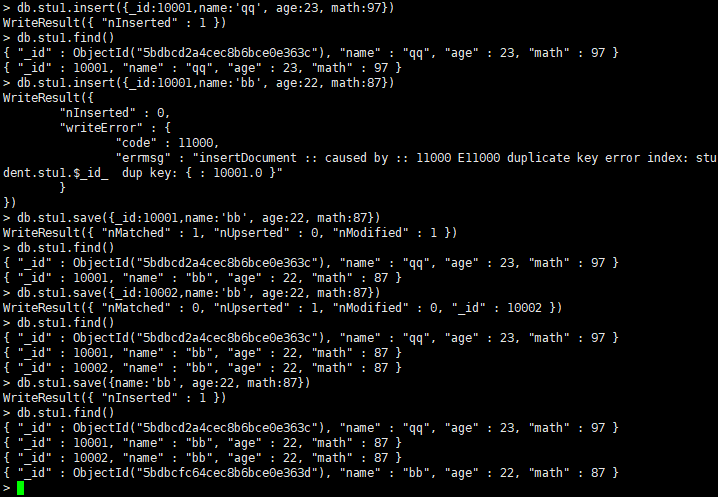
14.保存:
db.集合名.save(数据)
如果_id不存在,则添加数据,如果_id存在,则修改数据
例:
15.简单查询:
db.集合名.find() 例:

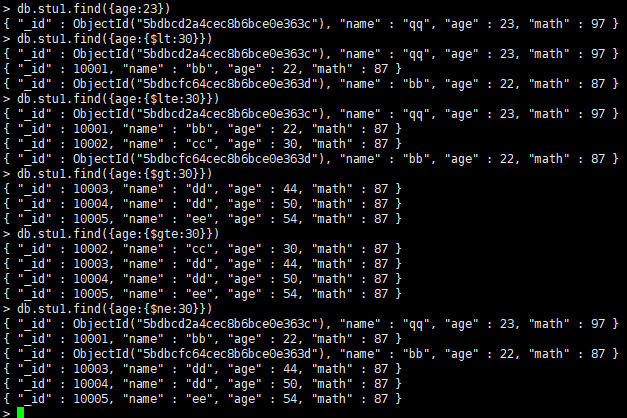
16.复杂查询:
比较运算符(等于(默认)、小于($lt)、小于等于($lte)、大于($gt)、大于等于($gte)、不等于($ne))
例:
逻辑运算符:
and:直接写多个条件

or:使用 $or,值为一个数组,数组中每个元素为json

组合使用

$in 范围之内
$nin 不在范围之内

17.排序:
db.集合名.find().sort({字段:1}) 参数1位升序,-1位降序
升序 db.stu1.find().sort({math:1})
降序 db.stu1.find().sort({math:-1})
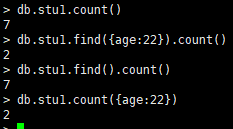
18.统计个数
方法count()用于统计结果集中文档条数
db.集合名.find().count()
db.集合名.count({条件})
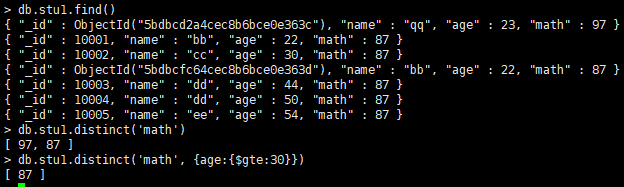
19.消除重复
方法distinct()对数据进行去重
db.集合名.distinct('去重字段',{条件})
例:
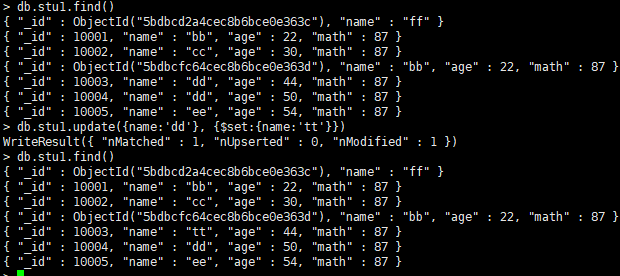
20.更新
db.集合名.update(<qurey>, <update>, {multi:<boolean>})
参数query:查询条件
参数update:更新操作符
参数multi:可选,默认值false,表示只更新找到的第一条记录;值为true,表示把满足条件的条件全部更新

可见这样更新有问题,应该这样:
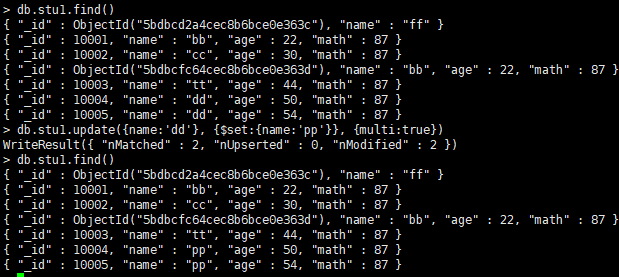
发现这样只会更新一条,若更新全部应:
21.删除
db.集合名.remove(<query>, {justOne:<boolean>})
参数query:可选,删除文档条件
参数justOne:可选,默认为false,表示删除多条;如果设置为true或1,则只删除一条
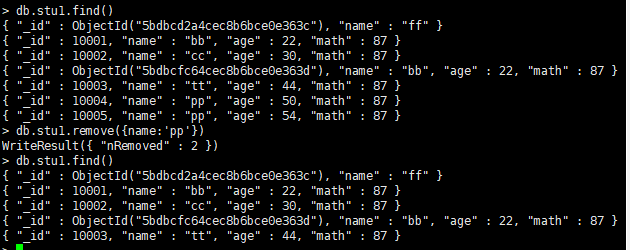
22.查询结果处理
查询结果格式化:
db.集合名.find(条件).pretty()
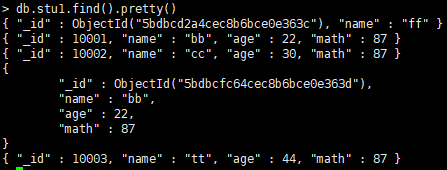
db.集合名.findOne(条件):只返回第一个结果
指定文档数量
方法limit() 用于读取指定数量的文档
db.集合名.find().limit(number)
方法skip() 用于跳过指定数量的文档
db.集合名.find().skip(number)
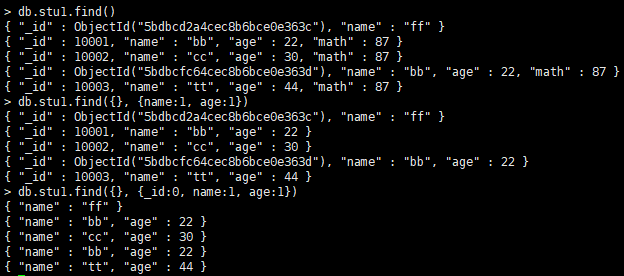
23.投影
在查询的返回结果中,只选择必要字段
db.集合名.find({}, {字段名1:1,字段名2:1})
参数为字段名,值1表示显示,值为0表示不显示
特殊:对于_id列默认是显示的,如果不显示需要明确设置为0
五、Mongodb聚合aggregate
聚合(aggregate)是基于数据处理的聚合管道,每个文档通过一个由多个阶段组成的管道,可以对每个阶段的管道进行分组、过滤等功能,然后经过一系列处理,输出响应结果。
常用管道如下:
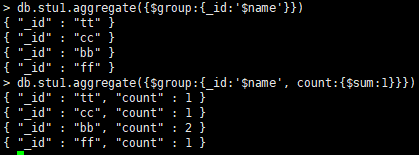
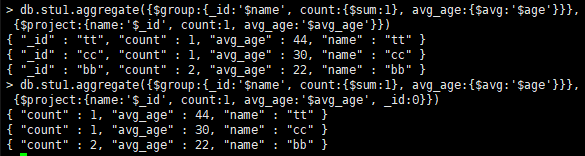
$group:将集合重的文档分组,可用于统计结果。

分组依据放在_id后面。
统计地址,统计每个地址的人数。例:
统计每个地址的平均年龄, 例:

group by null :将集合中所有文档分为一组,例:

$project 修改文档结构,如重命名、增加、删除字段创建计算结构,例:
$match:数据过滤(管道过滤不能用find)
(年龄大于20的人按名字分组,统计每个地址有多少人)

$sort:将输入文档排序后输出
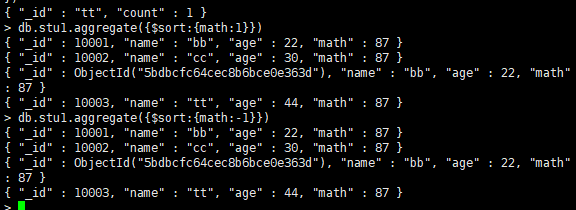
将数据按姓名分组,统计每个姓名的人数,并按降序排序:

$limit:限制集合管道返回的文档数,db.stu1.aggregate({$limit:2})
$skip:跳过指定数量的文档,并返回余下文档,db.stu1.aggregate({$skip:2})
db.stu1.aggregate({$skip:2}, {$limit:2})
六、常用表达式
$sum 计算综和,$sum:1 表示以一倍计数
$avg 计算平均值
$min 获取最小值
$max 获取最大值
七、索引:(提高查询速度)(唯一索引、普通索引、联合索引)
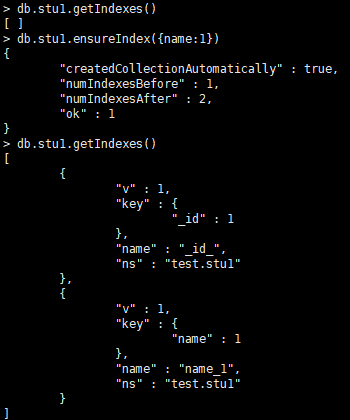
创建索引:
语法:db.集合.ensureIndex({属性:1}) 1表示升序,-1代表降序
查看当前集合所有索引:db.集合.getIndexes()
删除索引:
db.集合.dropIndex({索引名称:1})
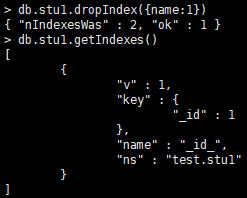
在默认情况下创建 的索引均不是唯一索引
创建唯一索引:db.集合.ensureIndex({'name':1}, {'unique':true})
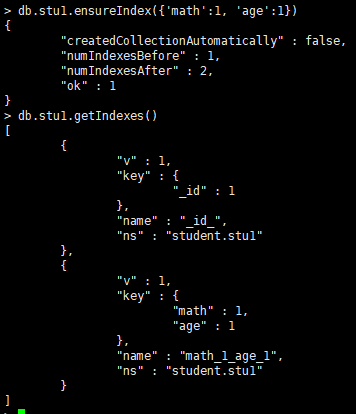
建立联合索引:db.集合.ensureIndex({'math':1, 'age':1})
八、数据库的备份和还原
备份语法:
远程备份:
mongodump -h dbhost -d dbname -o 路径
服务器IP地址 数据库名
mongodump -h 192.168.1.100:27017 -d test1 -o /home/test2
-h:服务器地址,指定端口号
-d:需要备份的数据库名称
-o:备份存放数据的位置,此目录放置备份的数据
本地备份:
mongodump -d dbname -o 路径
还原语法:
远程还原:
mongorestore -h dbhost -d dbname -o 路径
-h:服务器地址,指定端口号
-d:需要备份的数据库名称
-o:备份数据所在位置
mongorestore -h 192.168.1.100:27017 -d test2 -o /home/abc/day8/studentback/student
本机还原:
mongorestore -d student2 /home/abc/day8/studentback/student
mongodb细讲的更多相关文章
- JProfiler远程监控Linux上Tomcat的安装过程细讲(步骤非常详细!!!)
JProfiler远程监控Linux上Tomcat的安装过程细讲(步骤非常详细!!!) 1.文件准备: 服务器:CentOS Linux release 7.3.1611 (Core) Apa ...
- JavaScript基础细讲
JavaScript基础细讲 JavaScript语言的前身叫作Livescript.自从Sun公司推出著名的Java语言之后,Netscape公司引进了Sun公司有关Java的程序概念,将自己原 ...
- Celery定时任务细讲
Celery定时任务细讲 一.目录结构 任务所在目录 ├── celery_task # celery包 如果celery_task只是建了普通文件夹__init__可以没有,如果是包一定要有 │ ├ ...
- 细讲前端设置cookie, 储存用户登录信息
细讲前端设置cookie 引言 正文 一.设置cookie 二.查看cookie 三.删除cookie 四.封装cookie操作 结束语 引言 我们都知道如果想做一个用户登录并使浏览器保存其登录信息, ...
- 学到了林海峰,武沛齐讲的Day19 迭代细讲
在家加1个月学了8day的课 出差6天看了8day的课..说明再忙也是可以挤挤多学习的. 广州出差最后两天没学习.一天做车,一天做公司的事...4天就过去了. 老师讲的包子和鸡蛋需求不好...讲的有 ...
- MySQL高级部分理论知识细讲
文章目录 一.数据库分区.分表.分库.分片 YesOk ,大家好 ,我是小刘,许久不见,甚是想念 ,小刘今天来带大家学习 分库分表的基础知识 1.1 单机数据库的瓶颈 单个表数据量越大,读写锁,插入操 ...
- 转载:JProfiler远程监控LINUX上的Tomcat过程细讲
来源于xuwanbest的博客 所谓"工欲善其事,必先利其器",好的工具确能起到事半工倍的作用.我用到的最多的就两个JConsole 和JProfiler .JConsole监 ...
- 细讲encodeURI和encodeURIComponent以及escape的区别与应用
首先,我们都知道这三个东西都是用来编码的 先来说encodeURI()和encodeURIComponent() 这两个是在转换url时候用来编码解码用的. 有编码就会有解码, 解码就是decodeU ...
- Java文件上传细讲
什么是文件上传? 文件上传就是把用户的信息保存起来. 为什么需要文件上传? 在用户注册的时候,可能需要用户提交照片.那么这张照片就应该要进行保存. 上传组件(工具) 为什么我们要使用上传工具? 为啥我 ...
随机推荐
- gitLib操作笔录《一》:创建分支,切换分支,提交分支到远程,以及基本代码clone与更新提交到远程操作指令
git 操作经验注:master表示的是主线,origin 表示远程源 创建分支:git checkout -b < branch_name >或 < master >切换分支 ...
- 导入Maven 工程pom.xml首行报错解决方法
1.利用IDE导入一个Maven工程,但是pom.xml文件首行报错,发现是maven版本需要升级 2.在pom.xml文件 增加配置 <properties> <maven-jar ...
- Django实例
更新:今年8月在深圳和嵩天老师居然见面了,很开心.嵩天老师很和蔼. =========== 今天看了嵩天老师的视频,感觉讲的很好,于是看着视频自己做了一个初步的实例认识. 步骤1,新建一个Web框架 ...
- C#获取变更过的DataTable记录的实现方法
本文实例讲述了C#获取变更过的DataTable记录的实现方法,是一个非常实用的功能!具体实现方法如下: 首先DataTable可以看做是一个物理表的内存式存储,每一个DataRow都有一个属性叫做R ...
- 如何使用post请求下载文件
使用get请求下载文件非常简便,但是get请求的url有长度和大小的限制,所以当请求参数非常多时无法满足需求,所以改成post请求const res = await fetch('xxxxxxxxx' ...
- spring自动注入是单例还是多例?单例如何注入多例?
单例和多例的区别 : 单例多例需要搞明白这些问题: 1. 什么是单例多例: 2. 如何产生单例多例: 3. 为什么要用单例多例 4. 什么时候用单例, ...
- 【C++】满二叉树问题
/* 给出一棵满二叉树的先序遍历,有两种节点:字母节点(A-Z,无重复)和空节点(#).要求这个树的中序遍历.输出中序遍历时不需要输出#. 满二叉树的层数n满足1<=n<=5. Sampl ...
- Web开发——Photoshop(PSD格式截取)
Step1 将截取到的图片,存储为Web所用格式. Step2 在右上角选择存储格式为:PNG-24(PNG-8可能会出现白边).
- Mac苹果电脑没有声音怎么办
有时候 Mac 从睡眠状态恢复之后没有声音,这是 Mac OS X 系统的一个 Bug.这是因为 Mac OS X 的核心音频守护进程「coreaudiod」出了问题,虽然简单的重启电脑就能解决,但是 ...
- 召回率(Recall),精确率(Precision),平均正确率
https://blog.csdn.net/yanhx1204/article/details/81017134 摘要 在训练YOLO v2的过程中,系统会显示出一些评价训练效果的值,如Recall, ...