python简单爬虫 用lxml库解析数据
目标:爬取湖南大学2018年本科招生章程
url:http://admi.hnu.edu.cn/info/1026/2993.htm
页面部分图片:

使用工具:
- Python3.7
- 火狐浏览器
- PyCharm
步骤:
1.打开浏览器的开发者工具查看页面元素

2.html代码如下:
<div class="page-content"> <p class="vsbcontent_start"><strong>第一章</strong><strong> </strong><strong>总则</strong></p>
<p>第一条 为保证学校本科生招生工作顺利进行,切实维护学校和考生的合法权益,根据《中华人民共和国教育法》、《中华人民共和国高等教育法》和教育部继续推进高校招生“阳光工程”的有关规定,按照教育部“依法治招”的要求,为贯彻落实公平竞争、公正选拔的原则,进一步规范学校招生工作,确保招生工作顺利进行,特制定本章程。</p>
<p>第二条 学校全称为湖南大学,部标代码为10532,英文名称为“Hunan University”。</p>
<p>第三条 湖南大学是一所直属中华人民共和国教育部的国有公办全日制普通高等学校,也是国家“双一流”建设高校。</p>
<p>第四条 学校位于全国历史文化名城湖南省省会长沙市,学校地址:湖南省长沙市岳麓山;分南校区、财院校区两个校区。邮政编码:410082。</p>
<p>第五条 学校普通本科层次的招生包括普通类、自主招生、国家专项计划、高校专项计划、保送生、高水平艺术团、高水平运动队、艺术类、内地西藏班、内地新疆高中班、少数民族预科班、新疆协作计划。</p>
<p>第六条 学校依据教育部颁布的本年度《教育部关于做好普通高校招生工作的通知》和《普通高等学校招生工作规定》,全面贯彻实施高校招生“阳光工程”,本着公平、公正、公开的原则,综合衡量考生的德智体美情况,择优选拔。</p>
<p><strong>第二章</strong><strong> </strong><strong>组织机构及其职责</strong></p>
<p>第七条<a></a>湖南大学招生工作领导小组是学校招生工作的领导机构,研究招生简章与章程的制定等重要事项。湖南大学招生与就业指导处是学校组织和实施本科招生工作的常设机构,负责本科招生的日常工作。学校充分发挥招生委员会在民主监督、决策咨询等方面的作用</p>
<p>第八条 学校纪委办(监察处)负责监督招生政策的贯彻落实以及招生录取的公开、公平、公正,维护学校和考生的合法权益。</p>
<p><strong>第三章</strong><strong> </strong><strong>招生专业及招生计划</strong></p>
<p>第九条 学校根据优化生源结构、促进区域和城乡入学机会更加公平、保持数量基本稳定的原则,结合国家政策要求,统筹考虑各省考生人数、往年生源报考情况、就业市场需求与行业分布等因素,确定分省分专业来源计划。</p>
<p>第十条 学校招生与就业指导处将分省来源计划按要求及时报送到各有关省(自治区、直辖市)普通高校招生办公室备案,并通过相关渠道向社会公布。</p>
<p>第十一条 按照教育部的有关规定,将招生总计划的1%作为预留计划,用于平衡各省(自治区、直辖市)生源质量及解决同分考生的录取矛盾问题。</p>
<p><strong>第四章</strong><strong> </strong><strong>考试与考核</strong></p>
<p>第十二条 湖南大学是经教育部批准面向全国招收高水平艺术团和高水平运动队的高校,学校组织高水平艺术团和高水平运动队项目测试。通过测试,确定入选资格考生名单,并报教育部和有关省(自治区、直辖市)的普通高校招生办公室备案。</p>
<p>第十三条 湖南大学是经教育部批准面向全国招收保送生的高校,学校组织对保送生进行综合考核,根据考核成绩,确定保送生拟录取考生名单,并报教育部和有关省(自治区、直辖市)的普通高校招生办公室备案。</p>
<p>第十四条 湖南大学是经教育部批准进行自主招生试点的高校,按照报考专业考核,报考专业包括数学类(理)、电子科学与技术(应用物理学)(理)、化学(理)、生物技术(理)、机械类(工程力学)(理)、汉语言文学(文)、历史学(文)、英语(文理兼招)八个专业,此类考生录取入学后不得转专业。根据考核成绩,确定自主招生入选资格考生名单,并报教育部和有关省(自治区、直辖市)的普通高校招生办公室备案。</p>
<p>第十五条 湖南大学是经教育部批准面向全国实施高校专项计划招生考试的高校,根据考核成绩,确定高校专项计划入选资格考生名单,并报教育部和有关省(自治区、直辖市)的普通高校招生办公室备案。</p>
<p>第十六条 港澳台华侨考生考核按照教育部相关要求执行。</p>
<p><strong>第五章</strong><strong> </strong><strong>录取规则</strong></p>
<p>第十七条 在高考成绩达到同批次录取控制分数线的考生中,学校调阅考生档案的比例原则上控制在105%以内。</p>
<p>第十八条 对于实行非平行志愿的省(自治区、直辖市),按照顺序志愿投档的批次,在第一志愿考生生源不足的情况下,学校可接收非第一志愿考生,按照高考成绩择优录取。若符合条件的非第一志愿考生生源仍不足,将征集志愿。按照平行志愿投档的批次,未完成的计划也将征集志愿。征集志愿后生源仍不足,则从生源省份调出剩余的招生计划。</p>
<p>第十九条 对于符合学校录取标准的考生,学校按照实考分排队顺序进行录退。学校不设专业志愿分数级差,遵循分数优先的原则确定录取专业。</p>
<p>同一专业录取时,若考生实考分相同,按相关科目成绩择优录取,其中文史类考生依次比较语文、数学、外语,理工类考生依次比较语文、数学、外语。若单科成绩完全相同,学校将使用预留计划录取。<a></a>对于上海考生,按照上海市教育考试院提供的考生的同分数排位进行录取。</p>
<p>所有专业志愿都无法满足的考生,如果服从专业调剂,按照剩余招生计划调剂到其他专业。所有专业志愿都无法满足又不服从调剂的考生,作退档处理。</p>
<p>第二十条 对于江苏省考生,除江苏省招生工作文件内容明确规定外,考生进档后的排序方法采用等级级差法,选测科目中每取得一个A+、A等级,分别加上3分、1分的等级级差分,专业安排参照第十九条。两门选测科目最低等级要求均为B+。</p>
<p>第二十一条 学校各专业招生无男女生比例限制。</p>
<p>第二十二条 除特殊注明的专业外,学校对考生身体健康状况的要求按《普通高等学校招生体检工作指导意见》和《湖南大学招生体检工作实施细则》及有关补充规定执行。</p>
<p>第二十三条 报考学校英语专业的考生限其参加全国统考的外语语种为英语,其他专业不限考生应试外语语种,但学校以英语作为基础外语安排教学。</p>
<p>第二十四条 对于报考建筑学、城乡规划、工业设计专业的考生,要求具有一定美术基础。</p>
<p>第二十五条 获得自主招生入选资格的考生必须参加2018年全国普通高等学校招生统一考试,考生专业志愿须填报本人获得学校自主招生入选资格的专业。按照《湖南大学2018年自主招生简章》予以录取。</p>
<p>第二十六条 获得高校专项计划招生录取入选资格的考生必须参加2018年全国普通高等学校招生统一考试。按照《湖南大学2018年高校专项计划招生简章》予以录取。</p>
<p>第二十七条 艺术类(播音与主持艺术、广播电视编导)考生的专业考试成绩以生源所在省(自治区、直辖市)组织的联考成绩为准,且专业联考成绩须达到考生所在省份联考成绩合格线,学校优先录取第一志愿考生。录取规则如下:</p>
<p>播音与主持艺术:对于高考投档成绩(只含全国性高考加分)达到生源所在省份普通类一本线(自主招生参考线)分数90%及以上的考生,按照其专业联考成绩从高到低择优录取。专业联考成绩相同时,优先录取高考实考成绩(不含高考加分)高者;高考实考成绩(不含高考加分)、专业联考成绩均相同时,依次按语、外、数单科成绩从高到低择优录取。</p>
<p>广播电视编导:对于高考投档成绩(只含全国性高考加分)达到生源所在省份普通类一本线(自主招生参考线)分数95%及以上的考生,按照其高考实考成绩(不含高考加分)从高到低择优录取。高考实考成绩(不含高考加分)相同时,优先录取专业联考成绩高者;高考实考成绩(不含高考加分)、专业联考成绩均相同时,依次按语、外、数单科成绩从高到低择优录取。</p>
<p>第二十八条 保送生的招生录取按国家有关规定执行。</p>
<p>第二十九条 港澳台华侨考生录取按照教育部中国普通高等学校联合招收港澳台华侨学生招生录取办法执行。</p>
<p>第三十条 新生入校后,学校针对各类录取学生开展入学资格复查工作。凡复查不合格的新生,将按照有关规定进行处理,直至取消入学资格。</p>
<p><strong>第六章</strong><strong> </strong><strong>收费标准及其他</strong></p>
<p>第三十一条 根据国家有关规定,学生入学时必须按学校规定的缴费方式、时间缴纳学杂费。学校经湖南省物价局、湖南省财政厅和湖南省教育厅批准,实行学分制收费,按年学费标准预收。具体学费标准将在湖南大学招生信息网和入学须知上公布。</p>
<p>第三十二条 学校对新生入学设有“绿色通道”。家庭经济特别困难的新生,可持乡(镇)以上人民政府证明向学校学生工作部申请办理学费缓交手续;还可根据国家有关规定申请国家助学贷款。</p>
<p>第三十三条 凡通过全国普通高等学校统一招生考试录取的学生,德、智、体考核合格,符合学校本科生培养方案和培养目标要求的,由学校统一颁发湖南大学全日制普教本科毕业证书。符合学士学位授予条件的,授予相应学位。</p>
<p><strong>第七章</strong><strong> </strong><strong>附则</strong></p>
<p>第三十四条 本章程通过教育部阳光高考平台和湖南大学招生信息网向社会发布,对于各种媒体节选公布的章程内容,如理解有误,以学校公布的完整的招生章程为准。</p>
<p>第三十五条 招生咨询与申诉电话:0731-88823560、88823067、88823760,传真:0731-88823070,电子邮箱:admi@hnu.edu.cn,湖南大学招生信息网网址:http://admi.hnu.edu.cn。举报平台:湖南大学纪委微信公众号(微信号:hndxjwjcc)。</p>
<p>第三十六条 本章程解释权属于湖南大学。</p>
<p class="vsbcontent_end">第三十七条 本章程自公布之日起施行。学校原政策、规定即时废止;如遇国家法律、法规、规章和上级有关政策变化,以变化后的规定为准。</p> </div>
3.打开PyCharm,新建一test1.py文件
导入requests模块和lxml库
此时可以运行项目,如果报错,说明没有安装模块。
import requests
from lxml import etree
4.定义url和headers
url = 'http://admi.hnu.edu.cn/info/1026/2993.htm' # url:统一资源定位符=协议部分+网址+文件地址部分
headers = { # 请求头
# 告诉HTTP服务器, 客户端使用的操作系统和浏览器的名称和版本.
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92'
' Safari/537.36',
}
5.发送请求并解析HTML对象
response = requests.get(url, headers=headers) # 请求获取获取html
html = etree.HTML(response.content.decode('utf-8')) # 解析对象
6.据观察,每条数据都存在一个<p>标签内,所以决定创建一个列表,迭代出每个p标签的文本
从“第一章”的位置开始(此处为第一个p标签)
获取该标签的XPath:
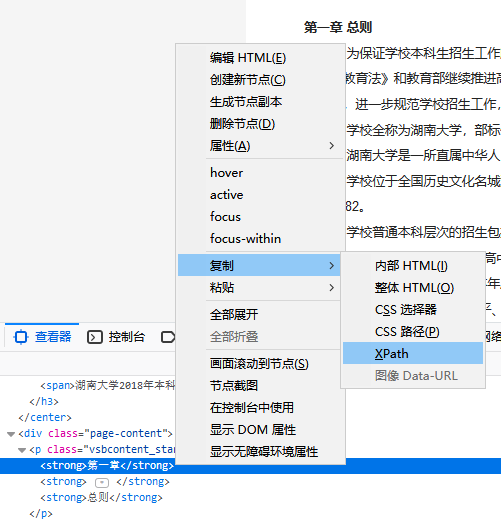
XPath为:/html/body/div[4]/div/p[1]/strong[1] (文本是加粗的,被放在一个strong标签里)
可知,同级的其它所有p标签的XPath为:div[4]/p
7.获取所有p标签,返回一个列表
p = html.xpath("//div[4]/div/p") # 使用xpath定位到相应节点,返回一个列表
dep = [] # 新建一个列表,用来存储每一条数据
for i in p:
data = { # 数据字典
''.join(i.xpath('.//strong//text()')), # join() 方法用于将序列中的元素以指定的字符连接生成一个新的字符串。定位到strong标签(即为每个章节的头部)
''.join(i.xpath('.//text()')) # text()方法为获取文本
}
print(data)
dep.append(data) ,# 将数据字典添加到dep列表中
8.将dep列表存储在一个txt文件中
# 数据存储
with open('湖南大学招生章程.txt', 'w', encoding='utf-8') as f: # 使用with open()创建对象f,命名为湖南大学招生章程,格式为.txt,‘w’表示获得写权限,encoding为编码方式
for i in dep:
f.write(str(i)+'\n') # 调用write()方法写入
9.全部代码
import requests
from lxml import etree url = 'http://admi.hnu.edu.cn/info/1026/2993.htm' # url:统一资源定位符=协议部分+网址+文件地址部分
headers = { # 请求头
# 告诉HTTP服务器, 客户端使用的操作系统和浏览器的名称和版本.
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92'
' Safari/537.36',
} # 发送请求并解析HTML对象
response = requests.get(url, headers=headers) # 请求获取获取html
html = etree.HTML(response.content.decode('utf-8')) # 解析对象 p = html.xpath("//div[4]/div/p") # 使用xpath定位到相应节点 dep = []
for i in p:
data = {
''.join(i.xpath('.//strong//text()')), # join() 方法用于将序列中的元素以指定的字符连接生成一个新的字符串。
''.join(i.xpath('.//text()'))
}
print(data)
dep.append(data) # 数据存储
with open('湖南大学招生章程.txt', 'w', encoding='utf-8') as f: # 使用with open()创建对象f
for i in dep:
f.write(str(i)+'\n')
10.运行结果

txt文件新建在同一个目录下

python简单爬虫 用lxml库解析数据的更多相关文章
- python简单爬虫 用lxml解析页面中的表格
目标:爬取湖南大学2018年在各省的录取分数线,存储在txt文件中 部分表格如图: 部分html代码: <table cellspacing="0" cellpadding= ...
- Python简单爬虫入门三
我们继续研究BeautifulSoup分类打印输出 Python简单爬虫入门一 Python简单爬虫入门二 前两部主要讲述我们如何用BeautifulSoup怎去抓取网页信息以及获取相应的图片标题等信 ...
- Python简单爬虫入门二
接着上一次爬虫我们继续研究BeautifulSoup Python简单爬虫入门一 上一次我们爬虫我们已经成功的爬下了网页的源代码,那么这一次我们将继续来写怎么抓去具体想要的元素 首先回顾以下我们Bea ...
- GJM : Python简单爬虫入门(二) [转载]
感谢您的阅读.喜欢的.有用的就请大哥大嫂们高抬贵手"推荐一下"吧!你的精神支持是博主强大的写作动力以及转载收藏动力.欢迎转载! 版权声明:本文原创发表于 [请点击连接前往] ,未经 ...
- Python 简单爬虫案例
Python 简单爬虫案例 import requests url = "https://www.sogou.com/web" # 封装参数 wd = input('enter a ...
- Python简单爬虫入门一
为大家介绍一个简单的爬虫工具BeautifulSoup BeautifulSoup拥有强大的解析网页及查找元素的功能本次测试环境为python3.4(由于python2.7编码格式问题) 此工具在搜索 ...
- GJM : Python简单爬虫入门 (一) [转载]
版权声明:本文原创发表于 [请点击连接前往] ,未经作者同意必须保留此段声明!如有侵权请联系我删帖处理! 为大家介绍一个简单的爬虫工具BeautifulSoup BeautifulSoup拥有强大的解 ...
- Python 网络爬虫的常用库汇总
爬虫的编程语言有不少,但 Python 绝对是其中的主流之一.下面就为大家介绍下 Python 在编写网络爬虫常常用到的一些库. 请求库:实现 HTTP 请求操作 urllib:一系列用于操作URL的 ...
- Python简单爬虫
爬虫简介 自动抓取互联网信息的程序 从一个词条的URL访问到所有相关词条的URL,并提取出有价值的数据 价值:互联网的数据为我所用 简单爬虫架构 实现爬虫,需要从以下几个方面考虑 爬虫调度端:启动爬虫 ...
随机推荐
- 利用Java手写简单的httpserver
前言: 在看完尚学堂JAVA300中讲解如何实现一个最简单的httpserver部分的视频之后, 一.前置知识 1.HTTP协议 当前互联网网页访问主要采用了B/S的模式,既一个浏览器,一个服务器,浏 ...
- spring boot 2使用Mybatis多表关联查询
模拟业务关系:一个用户user有对应的一个公司company,每个用户有多个账户account. spring boot 2的环境搭建见上文:spring boot 2整合mybatis 一.mysq ...
- WindowsService(Windows服务)开发步骤
https://www.cnblogs.com/moretry/p/4149489.html
- threejs 草场足球运动视角(三)
这次要模拟的场景如下图:就是在绿草地上足球的运动,并且视角会随着足球的运动发生变化,同时整个草地的视角也会旋转. 接下来,我们就对各个元素进行分析: 1,草地 用PlaneGeometry在三维空间里 ...
- Windows下安装Anaconda
Windows下安装Anaconda Anaconda介绍 Anaconda指的是一个开源的Python发行版本,其包含了conda.Python等180多个科学包及其依赖项.因为包含了大量的科学 ...
- crop image 需要的基础知识
refer : https://www.youtube.com/watch?v=R7dObDtw1aA https://www.shuxuele.com/algebra/trig-finding-an ...
- DB9针和DB25针串口的引脚定义
<设备监控技术详解>第3章串口设备监控,本章着力介绍串口交换机和串口联网方式.本节为大家介绍标准25针串口的引脚定义. 作者:李瑞民来源:机械工业出版社 3.3 串口线的制作和转换 串口的 ...
- 金蝶K3常用数据表
金蝶K3WISE常用数据表 K3Wise 14.2 清空密码update t_User set FSID=') F ", ,P T #8 *P!D &D 80!N &@ &l ...
- ElasticSearch改造研报查询实践
背景: 1,系统简介:通过人工解读研报然后获取并录入研报分类及摘要等信息,系统通过摘要等信息来获得该研报的URI 2,现有实现:老系统使用MSSQL存储摘要等信息,并将不同的关键字分解为不同字段来提供 ...
- 非阻塞模式(ioctlsocket)
//Server.cpp #include <stdio.h> #include <winsock2.h> //winsock.h (2种套接字版本) #pragma comm ...