Kubernetes部署ELK并使用Filebeat收集容器日志
本文的试验环境为CentOS 7.3,Kubernetes集群为1.11.2,安装步骤参见kubeadm安装kubernetes V1.11.1 集群
1. 环境准备
Elasticsearch运行时要求vm.max_map_count内核参数必须大于262144,因此开始之前需要确保这个参数正常调整过。
$ sysctl -w vm.max_map_count=262144
也可以在ES的的编排文件中增加一个initContainer来修改内核参数,但这要求kublet启动的时候必须添加了--allow-privileged参数,但是一般生产中不会给加这个参数,因此最好在系统供给的时候要求这个参数修改完成。
ES的配置方式
- 使用Cluster Update Setting API动态修改配置
- 使用配置文件的方式,配置文件默认在 config 文件夹下,具体位置取决于安装方式。
- elasticsearch.yml 配置Elasticsearch
- jvm.options 配置ES JVM参数
- log4j.properties 配置ES logging参数
- 使用Prompt方式在启动时输入
最常使用的配置方式为使用配置文件,ES的配置文件为yaml格式,格式要求和Kubernetes的编排文件一样。配置文件中可以引用环境变量,例如node.name: ${HOSTNAME}
ES的节点
ES的节点Node可以分为几种角色:
- Master-eligible node,是指有资格被选为Master节点的Node,可以统称为Master节点。设置
node.master: true - Data node,存储数据的节点,设置方式为
node.data: true。 - Ingest node,进行数据处理的节点,设置方式为
node.ingest: true。 - Trible node,为了做集群整合用的。
对于单节点的Node,默认是master-eligible和data,对于多节点的集群,就要仔细规划每个节点的角色。
2. 单实例方式部署ELK
单实例部署ELK的方法非常简单,可以参考我Github上的elk-single.yaml文件,整体就是创建一个ES的部署,创建一个Kibana的部署,创建一个ES的Headless服务,创建一个Kiana的NodePort服务,本地通过节点的NodePort访问Kibana。
[root@devops-101 ~]# curl -L -O https://raw.githubusercontent.com/cocowool/k8s-go/master/elk/elk-single.yaml
[root@devops-101 ~]# kubectl apply -f elk-single.yaml
deployment.apps/kb-single created
service/kb-single-svc unchanged
deployment.apps/es-single created
service/es-single-nodeport unchanged
service/es-single unchanged
[root@devops-101 ~]# kubectl get all
NAME READY STATUS RESTARTS AGE
pod/es-single-5b8b696ff8-9mqrz 1/1 Running 0 26s
pod/kb-single-69d6d9c744-sxzw9 1/1 Running 0 26s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/es-single ClusterIP None <none> 9200/TCP,9300/TCP 19m
service/es-single-nodeport NodePort 172.17.197.237 <none> 9200:31200/TCP,9300:31300/TCP 13h
service/kb-single-svc NodePort 172.17.27.11 <none> 5601:32601/TCP 19m
service/kubernetes ClusterIP 172.17.0.1 <none> 443/TCP 14d
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
deployment.apps/es-single 1 1 1 1 26s
deployment.apps/kb-single 1 1 1 1 26s
NAME DESIRED CURRENT READY AGE
replicaset.apps/es-single-5b8b696ff8 1 1 1 26s
replicaset.apps/kb-single-69d6d9c744 1 1 1 26s
可以看看效果如下:

3. 集群部署ELK
3.1 不区分集群中的节点角色
[root@devops-101 ~]# curl -L -O https://raw.githubusercontent.com/cocowool/k8s-go/master/elk/elk-cluster.yaml
[root@devops-101 ~]# kubectl apply -f elk-cluster.yaml
deployment.apps/kb-single created
service/kb-single-svc created
statefulset.apps/es-cluster created
service/es-cluster-nodeport created
service/es-cluster created
效果如下

3.2 区分集群中节点角色
如果需要区分节点的角色,就需要建立两个StatefulSet部署,一个是Master集群,一个是Data集群。Data集群的存储我这里为了简单使用了emptyDir,可以使用localStorage或者hostPath,关于存储的介绍,可以参考Kubernetes存储系统介绍。这样就可以避免Data节点在本机重启时发生数据丢失而重建索引,但是如果发生迁移的话,如果想保留数据,只能采用共享存储的方案了。具体的编排文件在这里elk-cluster-with-role
[root@devops-101 ~]# curl -L -O https://raw.githubusercontent.com/cocowool/k8s-go/master/elk/elk-cluster-with-role.yaml
[root@devops-101 ~]# kubectl apply -f elk-cluster-with-role.yaml
deployment.apps/kb-single created
service/kb-single-svc created
statefulset.apps/es-cluster created
statefulset.apps/es-cluster-data created
service/es-cluster-nodeport created
service/es-cluster created
[root@devops-101 ~]# kubectl get all
NAME READY STATUS RESTARTS AGE
pod/es-cluster-0 1/1 Running 0 13s
pod/es-cluster-1 0/1 ContainerCreating 0 2s
pod/es-cluster-data-0 1/1 Running 0 13s
pod/es-cluster-data-1 0/1 ContainerCreating 0 2s
pod/kb-single-5848f5f967-w8hwq 1/1 Running 0 14s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/es-cluster ClusterIP None <none> 9200/TCP,9300/TCP 13s
service/es-cluster-nodeport NodePort 172.17.207.135 <none> 9200:31200/TCP,9300:31300/TCP 13s
service/kb-single-svc NodePort 172.17.8.137 <none> 5601:32601/TCP 14s
service/kubernetes ClusterIP 172.17.0.1 <none> 443/TCP 16d
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
deployment.apps/kb-single 1 1 1 1 14s
NAME DESIRED CURRENT READY AGE
replicaset.apps/kb-single-5848f5f967 1 1 1 14s
NAME DESIRED CURRENT AGE
statefulset.apps/es-cluster 3 2 14s
statefulset.apps/es-cluster-data 2 2 13s
效果如下
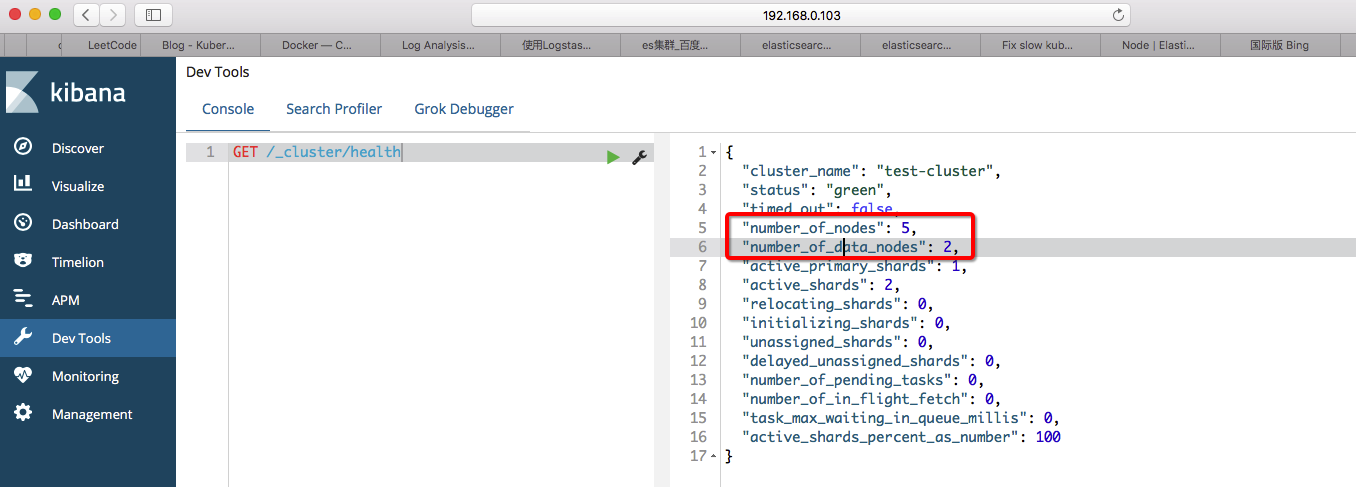
4. 使用Filebeat监控收集容器日志
使用Logstash,可以监测具有一定命名规律的日志文件,但是对于容器日志,很多文件名都是没有规律的,这种情况比较适合使用Filebeat来对日志目录进行监测,发现有更新的日志后上送到Logstash处理或者直接送入到ES中。
每个Node节点上的容器应用日志,默认都会在/var/log/containers目录下创建软链接,这里我遇到了两个小问题,第一个就是当时挂载hostPath的时候没有挂载软链接的目的文件夹,导致在容器中能看到软链接,但是找不到对应的文件;第二个问题是宿主机上这些日志权限都是root,而Pod默认用filebeat用户启动的应用,因此要单独设置下。
效果如下

具体的编排文件可以参考我的Github主页,提供了Deployment方式的编排和DaemonSet方式的编排。
对于具体日志的格式,因为时间问题没有做进一步的解析,这里如果有朋友做过,可以分享出来。
主要的编排文件内容摘抄如下。
kind: List
apiVersion: v1
items:
- apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-config
labels:
k8s-app: filebeat
kubernetes.io/cluster-service: "true"
app: filebeat-config
data:
filebeat.yml: |
processors:
- add_cloud_metadata:
filebeat.modules:
- module: system
filebeat.inputs:
- type: log
paths:
- /var/log/containers/*.log
symlinks: true
# json.message_key: log
# json.keys_under_root: true
output.elasticsearch:
hosts: ['es-single:9200']
logging.level: info
- apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: filebeat
labels:
k8s-app: filebeat
kubernetes.io/cluster-service: "true"
spec:
template:
metadata:
name: filebeat
labels:
app: filebeat
k8s-app: filebeat
kubernetes.io/cluster-service: "true"
spec:
containers:
- image: docker.elastic.co/beats/filebeat:6.4.0
name: filebeat
args: [
"-c", "/home/filebeat-config/filebeat.yml",
"-e",
]
securityContext:
runAsUser: 0
volumeMounts:
- name: filebeat-storage
mountPath: /var/log/containers
- name: varlogpods
mountPath: /var/log/pods
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
- name: "filebeat-volume"
mountPath: "/home/filebeat-config"
nodeSelector:
role: front
volumes:
- name: filebeat-storage
hostPath:
path: /var/log/containers
- name: varlogpods
hostPath:
path: /var/log/pods
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
- name: filebeat-volume
configMap:
name: filebeat-config

参考资料:
- Elasticsearch cluster on top of Kubernetes made easy
- Install Elasticseaerch with Docker
- Docker Elasticsearch
- Running Kibana on Docker
- Configuring Elasticsearch
- Elasticsearch Node
- Loggin Using Elasticsearch and kibana
- Configuring Logstash for Docker
- Running Filebeat on Docker
- Filebeat中文指南
- Add experimental symlink support
Kubernetes部署ELK并使用Filebeat收集容器日志的更多相关文章
- K8S 使用 SideCar 模式部署 Filebeat 收集容器日志
对于 K8S 内的容器日志收集,业内一般有两种常用的方式: 使用 DaemonSet 在每台 Node 上部署一个日志收集容器,用于收集当前 Node 上所有容器挂载到宿主机目录下的日志 使用 Sid ...
- ELK日志分析系统(2)-logspout收集容器日志
1. 概述 安装了ELK之后,就是要考虑怎么获取log数据了. 收集log数据的方式有很多种: 1). beats采集数据发布到logstash 2). Filebeat采集数据发布到logstash ...
- ELK学习实验018:filebeat收集docker日志
Filebeat收集Docker日志 1 安装docker [root@node4 ~]# yum install -y yum-utils device-mapper-persistent-data ...
- ELK学习实验016:filebeat收集tomcat日志
filebeat收集tomcat日志 1 安装tomcat [root@node4 ~]# yum -y install tomcat tomcat-webapps tomcat-admin-weba ...
- 用elk+filebeat监控容器日志
elk 为 elasticsearch(查询搜索引擎),logstash(对日志进行分析和过滤,然后转发给elasticsearch),kibana(一个web图形界面用于可视化elasticsea ...
- ELK之filebeat收集多类型日志
1.IP规划 10.0.0.33:filebeat+tomcat,filebeat收集系统日志.tomcat日志发送到logstash 10.0.0.32:logstash,将日志写入reids(in ...
- ELK学习实验017:filebeat收集java日志
收集JAVA格式日志 1 查看Java格式日志 elasticsearch属于Java日志,可以收集elasticsearch作为Java日志范本 [root@node3 ~]# tail -f /u ...
- ELK 二进制安装并收集nginx日志
对于日志来说,最常见的需求就是收集.存储.查询.展示,开源社区正好有相对应的开源项目:logstash(收集).elasticsearch(存储+搜索).kibana(展示),我们将这三个组合起来的技 ...
- ELK filter过滤器来收集Nginx日志
前面已经有ELK-Redis的安装,此处只讲在不改变日志格式的情况下收集Nginx日志. 1.Nginx端的日志格式设置如下: log_format access '$remote_addr - $r ...
随机推荐
- vue-cli 搭建的项目处理不同环境下请求不同域名的问题
使用 vue-cli 开发项目过程中, 根据开发环境和正式环境不同, 我们往往需要请求不同域名下的后台接口, 这时候, 该怎么去设置, 达到同一种写法可以根据环境不同而自动切换请求域名呢? 本文将会介 ...
- Linux在bash history当中添加timestamp
执行以下两条命令即可 echo 'export HISTTIMEFORMAT="%y-%m-%d %T "' >> /etc/profile source /etc/p ...
- LeetCode(45): 跳跃游戏 II
Hard! 题目描述: 给定一个非负整数数组,你最初位于数组的第一个位置. 数组中的每个元素代表你在该位置可以跳跃的最大长度. 你的目标是使用最少的跳跃次数到达数组的最后一个位置. 示例: 输入: [ ...
- PHP获取文件大小的方法详解
对于初入门的PHP新手来说,PHP获取文件大小这个功能实现,或许有一定的难度.但是相信新手小白们在看过本篇文章介绍后,一定能轻松掌握PHP获取文件大小的重要知识! 下面我们通过具体的代码示例,为大家详 ...
- ZOJ 3229 Shoot the Bullet(有源汇上下界最大流)
题目链接:http://acm.zju.edu.cn/onlinejudge/showProblem.do?problemId=3442 题目大意: 一个屌丝给m个女神拍照,计划拍照n天,每一天屌丝给 ...
- python 全栈开发,Day14(列表推导式,生成器表达式,内置函数)
一.列表生成式 生成1-100的列表 li = [] for i in range(1,101): li.append(i) print(li) 执行输出: [1,2,3...] 生成python1期 ...
- 《JavaScript 高级程序设计》第三章:基本概念
目录 语法 标识符 严格模式 关键字 保留字 变量 数据类型 运算符 表达式与语句 语法 "语法"指的是一门语言的书写风格,JavaScript 的语法风格很类似于 C 以及 Ja ...
- PhotoShop 常用快捷键
PhotoShop: ctrl+j 复制一块图层ctrl+t 自由变换钢笔画出来的是路径不是选区,将路径转化成选区:ctrl+回车 alt+delete 直排文字蒙版ctrl+d 取消选择中括号可改变 ...
- uva1354 天平难题 【位枚举子集】||【huffman树】
题目链接:https://vjudge.net/contest/210334#problem/G 转载于:https://blog.csdn.net/todobe/article/details/54 ...
- hdu 1276士兵队列问题【queue】
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1276 士兵队列训练问题 ...