Python爬虫实例:糗百
看了下python爬虫用法,正则匹配过滤对应字段,这里进行最强外功:copy大法实践
一开始是直接从参考链接复制粘贴的,发现由于糗百改版导致失败,这里对新版html分析后进行了简单改进,把整理过程记录如下:
参考文章中是这样的:
截图参考中的html文件布局如下:

分析参考中的伪代码如下:
分析图中html布局伪代码:
<div>
<div class=‘author’>
<a>
<img></img>
“昵称”
</a>
</div>
<div class=‘content’>
“内容”
</div>
<div class=‘status’>
<span></span>
<span></span>
<span></span>
</div>
</div>
进行匹配的正则表达式为:
'<div.*?author">.*?<a.*?<img.*?>(.*?)</a>.*?<div.*?' + 'content">(.*?)<!--(.*?)-->.*?</div>(.*?)<div class="stats.*?class="number">(.*?)</i>'
根据正则进行筛选过滤的python代码为:(python代码每次执行都一致,不同的事正则表达式,执行代码中的正则表达式替换为文字,复制上下文中的进行替换即可)
# -*- coding: UTF-8 -*- import urllib
import urllib2
import re def qiubaiWithoutImageTest():
page = 1
url = 'http://www.qiushibaike.com/hot/page/' + str(page)
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = {'User-Agent': user_agent}
try:
request = urllib2.Request(url, headers=headers)
response = urllib2.urlopen(request)
content = response.read().decode('utf-8')
# pattern = re.compile('<div.*?author">.*?<a.*?<img.*?>(.*?)</a>.*?<div.*?' +
# 'content">(.*?)<!--(.*?)-->.*?</div>(.*?)<div class="stats.*?class="number">(.*?)</i>',
# re.S)
pattern = re.compile('正则表达式',
re.S)
items = re.findall(pattern, content)
print items
for item in items:
print item[0],item[1],item[2],item[3]
# haveImg = re.search("img", item[3])
# if not haveImg:
# # print item
# print item[0], item[1], item[2], item[4]
except urllib2.URLError, e:
if hasattr(e, "code"):
print e.code
if hasattr(e, "reason"):
print e.reason #执行代码
qiubaiWithoutImageTest()
但是,听说但是之前的话都是废话。。。
但是因为糗百改版成如下图中的格式:
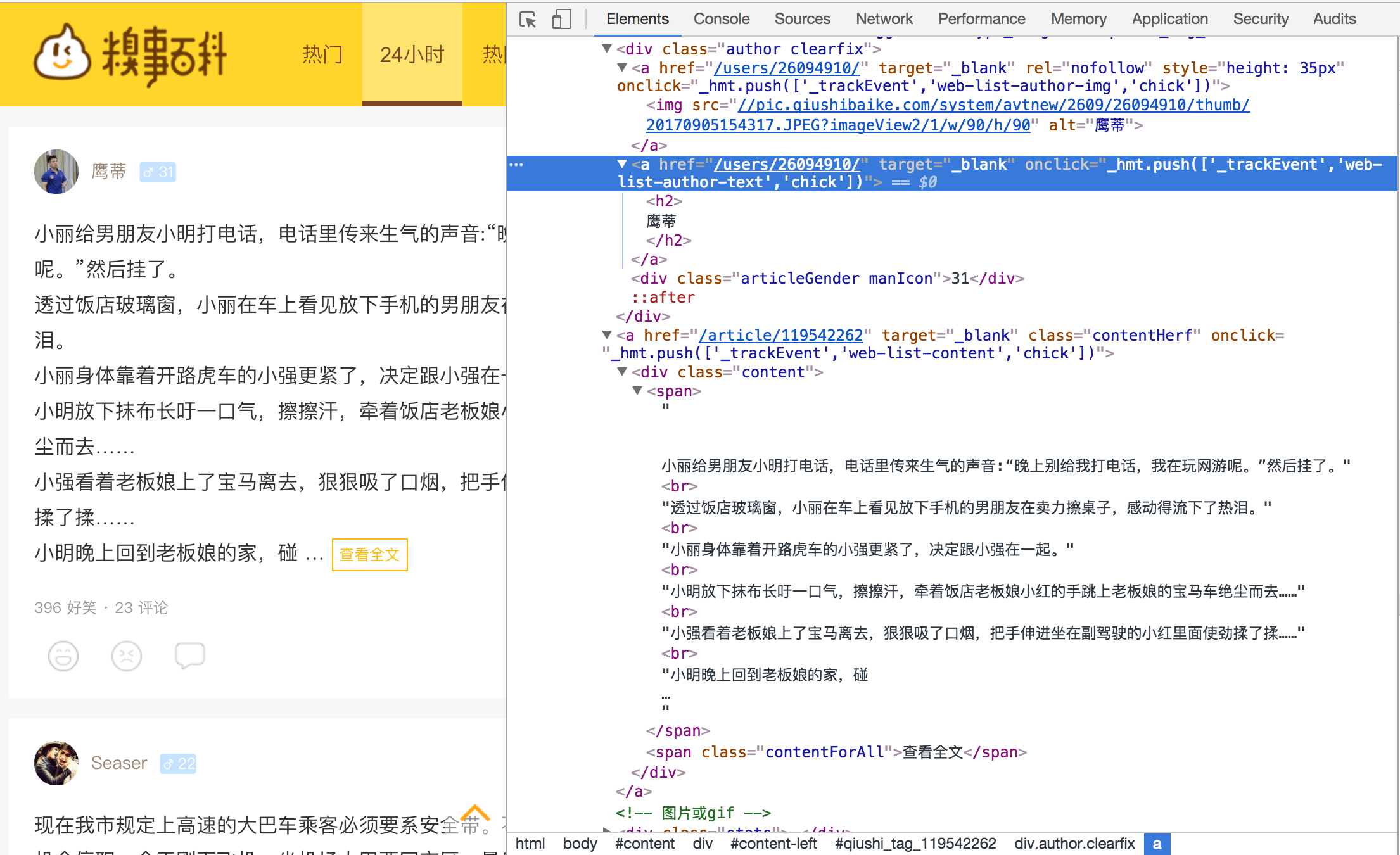
所以只能参考照猫画虎按照新格式进行正则表达式的修改了:
分析新的html伪代码格式如下:
<div>
<div class=‘author’>
<a><img></img></a>
<a><h2>’昵称’</h2></a>
<div>年龄</div>
</div>
<a class=‘contentHerf’>
<div class=‘content’>
<span>’内容’</span>
</div>
</a>
<div class=‘status’>
<span></span>
<span></span>
<span></span>
</div>
</div>
所以新版的正则表达式修改如下:
LZ正则水平有限,进行了多次尝试才匹配成功。。。,把各个版本记录如下
=======版本1(未通过)
'<div.*?author">.*?<a.*?<img.*?>(.*?)</a>.*?<a.*?><h2.*?>(.*?)</h2>.*?</a>.*?<a.*?contentHerf">.*?<div.*?' + 'content”>(.*?)<span.*?>(.*?)</span>.*?<!--(.*?)-->.*?</div>(.*?)</a>.*?<div class="stats.*?class="number">(.*?)</i>' ========版本2(未通过)
'<div.*?author">.*?<a.*?<img.*?>(.*?)</a>.*?<a.*?><h2.*?>(.*?)</h2>.*?</a>.*?<a.*?contentHerf">.*?<div.*?content">(.*?)<span.*?>(.*?)</span>.*?<!--(.*?)-->.*?</div>(.*?)</a>.*?<div class="stats.*?class="number">(.*?)</i>' =========版本3(未通过)
'<div.*?author">.*?<a.*?<img.*?>(.*?)</a>.*?<a.*?>.*?<h2.*?>(.*?)</h2>.*?</a>.*?<a.*?contentHerf">.*?<div.*?content">(.*?)<span.*?>(.*?)</span>.*?</div>.*?</a>.*?<div class="stats.*?class="number">(.*?)</i>' =========版本4(通过仅有内容)
'<div.*?content">(.*?)<span.*?>(.*?)</span>.*?</div>' =========版本5(通过:内容、昵称)
'<div.*?author clearfix">.*?<a.*?<img.*?>(.*?)</a>.*?<a.*?<h2.*?>(.*?)</h2>.*?</a>.*?</div>.*?<div.*?content">(.*?)<span.*?>(.*?)</span>.*?</div>' =========版本6(通过:内容、昵称、年龄)
'<div.*?author clearfix">.*?<a.*?<h2.*?>(.*?)</h2>.*?</a>.*?<div.*?articleGender manIcon">(.*?)</div>.*?</div>.*?<div.*?content">(.*?)<span.*?>(.*?)</span>.*?</div>'
最终终于看到了如下结果:
胖香娇喘助理
31
老妹单身很久了,一直没对象,那天跟我出去坐公交,身边站着一个小伙子,小婊砸一直往人小伙子身边蹭。<br/>突然,这小婊砸捂着头:“哎呦!我头晕,不行,晕了。。。”说着,顺势倒在人家小伙子怀里。<br/>小伙子吓坏了,摇了摇老妹:“大姐,大姐,您没事吧!”<br/>老妹一听,怒不可遏:“叫谁大姐呢?我有这么老吗?”说着,给了人家一个白眼,还没到站就下车了。<br/>剩我一脸蒙蔽。。这招几百年前就有人用了。 萌面大叔l
26
我对蝉说,他日再见要等来年!蝉对我说,他日重逢要等来生! 逍遥ベ假行僧
29
初闻不知曲中意,在听已是曲中人。 现知词意唯落泪,不见当年陪孤人。 既然亦是曲中人,为何还听曲中曲。 曲中思念今犹在,不见当年梦中人。 逆流而上669
26
一次历史考试,问:1966年至1999年发生了哪三件大事。一奇葩同学是这样回答的:“1969年,我爸出生了;1972年我妈出生了;1995年,一个晴天霹雳,神一般的人物——我诞生了!”然后这张试卷就在公告栏里挂了一个星期! 匿名用户 38
公司高层来我们基层调研,到我们单位的是位副总,笔杆子小李又开始嘚瑟着发报道,还把稿子发到我们单位群,其中有这几句话“某总深入基层调研一线生产生活情况,与一线职工同吃同住......”我@了他一下,说:“在职工前面加个女字就更好了。”就在这时,某副总@了我一下:“到我办公室来一下。”我擦,谁把副总拉群里来的?[哀怨][哀怨][哀怨] 匿名用户 0
没有更好的办法了 a金钊
24
男生用“没事,不疼。”欺骗了多少女生;女生用“啊,疼!”欺骗了多少男生。 青青子衿忧我心
24
甲:怎么了?看着你气色不太好<br/>乙:昨儿喝多了,也吐也泻<br/><br/>甲:喝多少啊?成这德行<br/>乙:喝了一打老酸奶。。。<br/>听得都TM醉了,,,, 请叫我小智
21
看懂绝逼是污神。 surepman
22
这真不是故意的 傻晴°
38
开会,女同事让我坐她旁边,我内心一阵激动。我坐定后,她拿出手机玩了起来,说:你坐这领导(在侧面)就看不见我了。 挖鼻孔的老虎
99
晚上回到家,老婆用手机边拍我边问:“不是说加班吗,怎么有酒味?”<br/>我面对摄像头有点不自在:“我,我口渴,路上买了瓶啤酒喝。”<br/>老婆拿着手机捣鼓了好一会儿,然后说:“我妈不信、我妹妹不信、我全体闺蜜不信,连我9岁的侄女都觉得你没加班只是去了喝酒。” 今狐小妖
30
二楼二楼,别拿着手机看了电话不会打来的 你的选择你的选择
35
这一家子拖鞋真会放,整齐,还有什么?
LZ是Python新手,水平有限,仅作为学习参考使用!
贴上后续参考中的进阶代码
# -*- coding: UTF-8 -*- import urllib
import urllib2
import re
import thread
import time # 糗事百科爬虫类
class QSBK:
# 初始化方法,定义一些变量
def __init__(self):
self.pageIndex = 1
self.user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
# 初始化headers
self.headers = {'User-Agent': self.user_agent}
# 存放段子的变量,每一个元素是每一页的段子们
self.stories = []
# 存放程序是否继续运行的变量
self.enable = False # 传入某一页的索引获得页面代码
def getPage(self, pageIndex):
try:
url = 'http://www.qiushibaike.com/hot/page/' + str(pageIndex)
# 构建请求的request
request = urllib2.Request(url, headers=self.headers)
# 利用urlopen获取页面代码
response = urllib2.urlopen(request)
# 将页面转化为UTF-8编码
pageCode = response.read().decode('utf-8')
# print pageCode
return pageCode except urllib2.URLError, e:
if hasattr(e, "reason"):
print u"连接糗事百科失败,错误原因", e.reason
return None # 传入某一页代码,返回本页不带图片的段子列表
def getPageItems(self, pageIndex):
pageCode = self.getPage(pageIndex)
if not pageCode:
print "页面加载失败...."
return None
pattern = re.compile('<div.*?author clearfix">.*?<a.*?<h2.*?>(.*?)</h2>.*?</a>.*?<div.*?articleGender manIcon">(.*?)</div>.*?</div>.*?<div.*?content">(.*?)<span.*?>(.*?)</span>.*?</div>',
re.S)
items = re.findall(pattern, pageCode)
# 用来存储每页的段子们
pageStories = []
# 遍历正则表达式匹配的信息
for item in items: for itemInItem in item:
pageStories.append(itemInItem.strip())
print itemInItem # 是否含有图片
# haveImg = re.search("img", item[3])
# # 如果不含有图片,把它加入list中
# if not haveImg:
# replaceBR = re.compile('<br/>')
# text = re.sub(replaceBR, "\n", item[1])
# # item[0]是一个段子的发布者,item[1]是内容,item[2]是发布时间,item[4]是点赞数
# pageStories.append([item[0].strip(), text.strip(), item[2].strip(), item[4].strip()])
return pageStories # 加载并提取页面的内容,加入到列表中
def loadPage(self):
# 如果当前未看的页数少于2页,则加载新一页
if self.enable == True:
if len(self.stories) < 2:
# 获取新一页
pageStories = self.getPageItems(self.pageIndex)
# 将该页的段子存放到全局list中
if pageStories:
self.stories.append(pageStories)
# 获取完之后页码索引加一,表示下次读取下一页
self.pageIndex += 1 # 调用该方法,每次敲回车打印输出一个段子
def getOneStory(self, pageStories, page):
# 遍历一页的段子
for story in pageStories:
# 等待用户输入
input = raw_input()
# 每当输入回车一次,判断一下是否要加载新页面
self.loadPage()
# 如果输入Q则程序结束
if input == "Q":
self.enable = False
return
print u"第%d页\t发布人:%s\t发布时间:%s\t赞:%s\n%s" % (page, story[0], story[2], story[3], story[1]) # 开始方法
def start(self):
print u"正在读取糗事百科,按回车查看新段子,Q退出"
# 使变量为True,程序可以正常运行
self.enable = True
# 先加载一页内容
self.loadPage()
# 局部变量,控制当前读到了第几页
nowPage = 0
while self.enable:
if len(self.stories) > 0:
# 从全局list中获取一页的段子
pageStories = self.stories[0]
# 当前读到的页数加一
nowPage += 1
# 将全局list中第一个元素删除,因为已经取出
del self.stories[0]
# 输出该页的段子
self.getOneStory(pageStories, nowPage) qbspider = QSBK()
qbspider.start()#在log中敲入enter进行下一页数据展示,目前还有一些问题
参考链接:
python学习笔记三:解析html(HTMLParser、SGMLParser),并抓取图片
Python爬虫实例:糗百的更多相关文章
- Python爬虫实例:爬取B站《工作细胞》短评——异步加载信息的爬取
很多网页的信息都是通过异步加载的,本文就举例讨论下此类网页的抓取. <工作细胞>最近比较火,bilibili 上目前的短评已经有17000多条. 先看分析下页面 右边 li 标签中的就是短 ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- Python 爬虫实例
下面是我写的一个简单爬虫实例 1.定义函数读取html网页的源代码 2.从源代码通过正则表达式挑选出自己需要获取的内容 3.序列中的htm依次写到d盘 #!/usr/bin/python import ...
- shell及Python爬虫实例展示
1.shell爬虫实例: [root@db01 ~]# vim pa.sh #!/bin/bash www_link=http://www.cnblogs.com/clsn/default.html? ...
- python爬虫实例——爬取歌单
学习自<<从零开始学python网络爬虫>> 爬取酷狗歌单,保存入csv文件 直接上源代码:(含注释) import requests #用于请求网页获取网页数据 from b ...
- python爬虫实例大全
WechatSogou [1]- 微信公众号爬虫.基于搜狗微信搜索的微信公众号爬虫接口,可以扩展成基于搜狗搜索的爬虫,返回结果是列表,每一项均是公众号具体信息字典. DouBanSpider [2]- ...
- Python 爬虫实例(爬百度百科词条)
爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成.爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入 ...
- Python爬虫实例(三)代理的使用
一些网站会有相应的反爬虫措施,例如很多网站会检测某一段时间某个IP的访问次数,如果访问频率太快以至于看起来不像正常访客,它可能就会会禁止这个IP的访问.所以我们需要设置一些代理服务器,每隔一段时间换一 ...
随机推荐
- favicon.ico问题
在访问web的时候,有时出现favicon.ico 不知道这是一个什么东西,查看百度:
- centos7 部署 open-falcon 0.2.1
=============================================== 2019/4/28_第1次修改 ccb_warlock 更新 ...
- Linux多台机器配置ssh免登录
.安装ssh. sudo apt-get install ssh. 安装完成后会在~目录(当前用户主目录,即这里的/home/xuhui)下产生一个隐藏文件夹.ssh(ls -a 可以查看隐藏文件). ...
- Python-HTML 最强标签分类
编程: 使用(展示)数据 存储数据 处理数据 前端 1. 前端是做什么的? 2. 我们为什么要学前端? 3. 前端都有哪些内容? 1. HTML 2. CSS 3. JavaScript 4.jQue ...
- Android 自定义View二(深入了解自定义属性attrs.xml)
1.为什么要自定义属性 要使用属性,首先这个属性应该存在,所以如果我们要使用自己的属性,必须要先把他定义出来才能使用.但我们平时在写布局文件的时候好像没有自己定义属性,但我们照样可以用很多属性,这是为 ...
- ubuntu chrome 安装ubuntu16.04 : google浏览器安装及离线插件安装(谷歌访问助手)
1.https://blog.csdn.net/cheneykl/article/details/79187954 https://download.oracle.com/otn-pub/java/j ...
- 获取修改CSS
获取CSS使用方法css("CSS属性名称"), 示例css("color") 设置CSS使用方法css("CSS属性名称","属 ...
- 【C语言】字节对齐(内存对齐)
数据对齐 1. 对齐原则: [原则1]数据成员对齐规则:结构(struct)(或联合(union))的数据成员,第一个数据成员放在offset为0的地方,以后每个数据成员的对齐按照#pragma p ...
- Kibana加载样本数据
kibana 6.2 加载样本数据 kibana loading sample data 下载样本数据 # 莎士比亚经典作品 wget https://download.elastic.co/demo ...
- 国内最火5款Java微服务开源项目
目录 1.pig 2.zheng 3.Cloud-Platform 4.SpringBlade 5.Guns 1.pig 开源地址:https://gitee.com/log4j/pig 基于Spri ...