Caffe使用step by step:caffe框架下的基本操作和分析
caffe虽然已经安装了快一个月了,但是caffe使用进展比较缓慢,果然如刘老师说的那样,搭建起来caffe框架环境比较简单,但是完整的从数据准备->模型训练->调参数->合理结果需要一个比较长的过程,这个过程中你需要对caffe中很多东西,细节进行深入的理解,这样才可以知道为什么能有这样的结果,在训练或者fine-tuning时知道针对调整的方法。下面针对caffe中的使用进行讲解。
在使用过程中,caffe官网上提供了详细的使用说明,如果感觉仍然存在一些困难,可以使用谷歌或百度搜索自己遇到的问题和想要了解的过程进行搜索学习。
一、Caffe模型基本组成
想要训练一个caffe模型,需要配置两个文件,包含两个部分:网络模型,参数配置,分别对应***.prototxt , ****_solver.prototxt文件
Caffe模型文件讲解:
- 预处理图像的leveldb构建
输入:一批图像和label (2和3)
输出:leveldb (4)
指令里包含如下信息:- conver_imageset (构建leveldb的可运行程序)
- train/ (此目录放处理的jpg或者其他格式的图像)
- label.txt (图像文件名及其label信息)
- 输出的leveldb文件夹的名字
- CPU/GPU (指定是在cpu上还是在gpu上运行code)
CNN网络配置文件
- Imagenet_solver.prototxt (包含全局参数的配置的文件)
- Imagenet.prototxt (包含训练网络的配置的文件)
- Imagenet_val.prototxt (包含测试网络的配置文件)
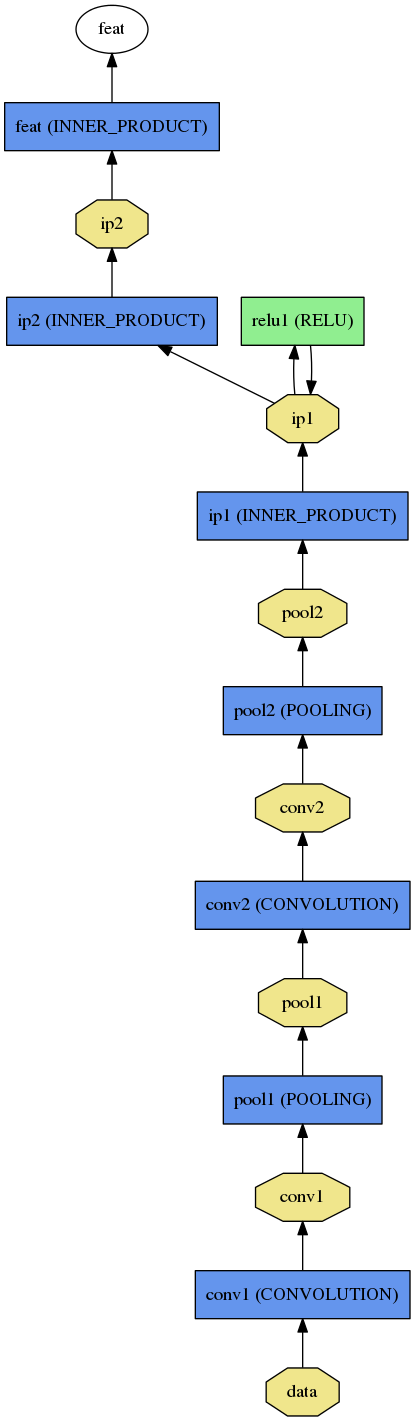
网络模型:即定义你网络的每一层,下图是用caffe中 /python/draw_net.py画出的的siamese的模型,非常清晰
层包含:(以LeNet为例)
DATA:一般包括训练数据和测试数据层两种类型。 一般指输入层,包含source:数据路径,批处理数据大小batch_size,scale表示数据表示在[0,1],0.00390625即 1/255
训练数据层:
layer {
name: "mnist"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
scale: 0.00390625
}
data_param {
source: "examples/mnist/mnist_train_lmdb"
batch_size: 64
backend: LMDB
}
}
测试数据层:
layer {
name: "mnist"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
scale: 0.00390625
}
data_param {
source: "examples/mnist/mnist_test_lmdb"
batch_size:
backend: LMDB
}
}
CONVOLUATION:卷积层,blobs_lr:1 , blobs_lr:2分别表示weight 及bias更新时的学习率,这里权重的学习率为solver.prototxt文件中定义的学习率真,bias的学习率真是权重学习率的2倍,这样一般会得到很好的收敛速度。
num_output表示滤波的个数,kernelsize表示滤波的大小,stride表示步长,weight_filter表示滤波的类型
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1 //weight学习率
}
param {
lr_mult: 2 //bias学习率,一般为weight的两倍
}
convolution_param {
num_output: 20 //滤波器个数
kernel_size:
stride: 1 //步长
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
POOLING: 池化层
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 2
stride:
}
}
INNER_PRODUCT: 其实表示全连接,不要被名字误导
layer {
name: "ip1"
type: "InnerProduct"
bottom: "pool2"
top: "ip1"
param {
lr_mult:
}
param {
lr_mult:
}
inner_product_param {
num_output: 500
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
RELU:激活函数,非线性变化层 max( 0 ,x ),一般与CONVOLUTION层成对出现
layer {
name: "relu1"
type: "ReLU"
bottom: "ip1"
top: "ip1"
}
SOFTMAX:
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "ip2"
bottom: "label"
top: "loss"
}
参数配置文件:
***_solver.prototxt文件定义一些模型训练过程中需要到的参数,比较学习率,权重衰减系数,迭代次数,使用GPU还是CPU等等
# The train/test net protocol buffer definition
net: "examples/mnist/lenet_train_test.prototxt" # test_iter specifies how many forward passes the test should carry out.
# In the case of MNIST, we have test batch size and test iterations,
# covering the full , testing images.
test_iter: # Carry out testing every training iterations.
test_interval: # The base learning rate, momentum and the weight decay of the network.
base_lr: 0.01
momentum: 0.9
weight_decay: 0.0005 # The learning rate policy
lr_policy: "inv"
gamma: 0.0001
power: 0.75 # Display every iterations
display: # The maximum number of iterations
max_iter: # snapshot intermediate results
snapshot:
snapshot_prefix: "examples/mnist/lenet" # solver mode: CPU or GPU
solver_mode: GPU
device_id: 0 #在cmdcaffe接口下,GPU序号从0开始,如果有一个GPU,则device_id:0
训练出的模型被存为***.caffemodel,可供以后使用。
二、使用caffe训练模型包含以下几个步骤:
- 准备数据
在caffe中使用数据来对机器学习算法进行训练时,首先需要了解基本数据组成。不论使用何种框架进行CNNs训练,共有3种数据集:
- Training Set:用于训练网络
- Validation Set:用于训练时测试网络准确率
- Test Set:用于测试网络训练完成后的最终正确率
- 重建lmdb/leveldb文件,caffe支持三种数据格式输入:images, levelda, lmdb
Caffe生成的数据分为2种格式:Lmdb和Leveldb
- 它们都是键/值对(Key/Value Pair)嵌入式数据库管理系统编程库。
- 虽然lmdb的内存消耗是leveldb的1.1倍,但是lmdb的速度比leveldb快10%至15%,更重要的是lmdb允许多种训练模型同时读取同一组数据集。
- 因此lmdb取代了leveldb成为Caffe默认的数据集生成格式。
- 定义name.prototxt , name_solver.prototxt文件
- 训练模型
三、caffe中比较有用且基础的接口(cmdcaffe)
注:在使用cmdcaffe时,需要默认切换到Caffe_Root文件夹下
1、训练模型,以mnist为例子
./build/tools/caffe train --solver=examples/mnist/lenet_solver.prototxt
注:caffe官网上给的例子不能直接执行,需要使用上述命令才可以使用tools下的caffe接口,因为caffe默认都需要从根目录下面执行文件。
2、观察各个阶段的运行时间可以使用
./build/tools/caffe time --model=models/bvlc_reference_caffenet/train_val.prototxt
3、使用已有模型提取特征
./build/tools/extract_features.bin models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel examples/_temp/imagenet_val.prototxt conv5 examples/_temp/features
conv5表示提取第五个卷积层的特征, examples/_temp/feaures表示存放结果的目录(这里的目录需要提前构建好)
4、对已有模型进行find-tuning,比如我们现在有一个1000类的分类模型,但目前我们的需求仅是20类,此时我们不需要重新训练一个模型,只需要将最后一层换成20类的softmax层,然后使用已有数据对原模型进行fine-tuning即可
在很多时候,使用Caffe框架学习深度学习模型时,从ImageNet或者其他大型数据集从头开始训练获得一个fine-tuing合适的模型难度太大,这时候最好的情况,就是在已经训练好的模型上面来进行fine-tuning,通过这些过程可以加深自己对深度学习,以及对caffe使用的了解和熟悉,以方便自己在后续提出自己的模型,自己进行模型训练和fine-tuning的过程。
已经训练好的caffe模型可以在git的caffe项目中下载,比较经典的模型有:AlexNet.caffemodel , LeNet.caffemodel , RCnn.caffemodel,其他的大家可以在caffe的git官网上面下载。
使用自己的数据集对已经训练好的模型进行fine-tuning的操作(使用cmdcaffe接口来进行):
./build/tools/caffe train -solver models/finetune_flickr_style/solver.prototxt -weights models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel -gpu 0
[option] 2>&1 | tee log.txt
第一个参数:选择好caffe模块
train:选取train函数
后面接具体的参数,分别为配置命令,配置文件路径,fine-tuning命令,fine-tuning依赖的基准模型文件目录,选用的训练方式:gpu或者cpu,使用cpu时可以默认不写
注:fine-tuning的过程与训练过程类似,只是在调用caffe接口时的命令不同,因此在fine-tuning之前,仍然需要按照训练流程准备数据。
下载数据->生成trainset和testset->生成db->设置好路径->fine-tuning。
5、还有一个是python下面的接口,draw_net.py可以根据.prototxt文件将模式用图示的方法表示出来,博文开始的模型图即用该接口所绘
./python/draw_net.py ./examples/siamese/mnist_siamese.prototxt ./examples/siamese/mnist_siamese.png
使用该接口进行网络的绘制示例化
第一个参数为模型文件,第二个参数为所绘模型图的保存地址
深度学习中batch_size的作用:
在深度学习训练过程中,有两种训练方法,一种意识batch ,一种是stochastic训练方法
solver:使用forward和backward接口来更新参数,并迭代对loss进行降低(定义的优化方法,有stochastic gradient descent,SGD;Adaptive gradient ,NAG和Scaffolding)
solver作用:(指定优化方法)
1.可以逐步对网络寻优,创建训练得到的网络,并对测试网络进行评价;
2.通过调用forward和backward来对网络参数进行迭代寻优;
3.周期性更新网络;
4.记录网络训练中间过程,寻优过程中记录状态
Caffe网络模型文件分析:
一个完整的基于caffe的网络模型,应该包含以下几个文件:

其中,deploy.prototxt是用来在网络完成训练之后进行部署的(其他深度学习框架导入caffemodel文件时,也是以此为原型),solver.prototxt用于设定网络训练时的参数,train_val.prototxt用于对网络进行训练的模型定义,*.caffemodel是预训练好的网络模型,存储网络中的参数。
caffe和theano以及lasagne转化过程中的一些基础知识:
在caffe结构中,在convLayer层中有group这样一个参数,该参数来自于经典的ImageNet论文,关于group参数,yangqing给的解释为:
It was there to implement the grouped convolution in Alex Krizhevsky's paper: when group=2, the first half of the filters are only connected to the first half of the input channels, and the second half only connected to the second half.
即当group=2时,filter的前半部分同输入连接,后半部分同后半部分的filter连接,而在lasagne中并没有对应的该参数,因此需要使用官方给定的函数接口来进行实现。
具体见:地址
参考博客:Caffe 初识,揭开面纱
Caffe使用step by step:caffe框架下的基本操作和分析的更多相关文章
- 【神经网络与深度学习】Caffe使用step by step:caffe框架下的基本操作和分析
caffe虽然已经安装了快一个月了,但是caffe使用进展比较缓慢,果然如刘老师说的那样,搭建起来caffe框架环境比较简单,但是完整的从数据准备->模型训练->调参数->合理结果需 ...
- MySQL在Django框架下的基本操作(MySQL在Linux下配置)
[原]本文根据实际操作主要介绍了Django框架下MySQL的一些常用操作,核心内容如下: ------------------------------------------------------ ...
- Caffe框架下的图像回归测试
Caffe框架下的图像回归测试 参考资料: 1. http://stackoverflow.com/questions/33766689/caffe-hdf5-pre-processing 2. ht ...
- caffe框架下目标检测——faster-rcnn实战篇操作
原有模型 1.下载fasrer-rcnn源代码并安装 git clone --recursive https://github.com/rbgirshick/py-faster-rcnn.git 1) ...
- Caffe使用step by step:faster-rcnn目标检测matlab代码
faster-rcnn是MSRA在物体检测最新的研究成果,该研究成果基于RCNN,fast rcnn以及SPPnet,对之前目标检测方法进行改进,faster-rcnn项目地址.首先,faster r ...
- caffe框架下目标检测——faster-rcnn实战篇问题集锦
1.问题 解决方案:没编译好,需要在lib下编译make 需要在caffe-fast-rcnn下编译make或者make all -j16 ,还需要make pycaffe 2.问题 解决方案:/p ...
- EF框架step by step(7)—Code First DataAnnotations(2)
上一篇EF框架step by step(7)—Code First DataAnnotations(1)描述了实体内部的采用数据特性描述与表的关系.这一篇将用DataAnnotations描述一下实体 ...
- EF框架step by step(7)—Code First DataAnnotations(1)
Data annotation特性是在.NET 3.5中引进的,给ASP.NET web应用中的类提供了一种添加验证的方式.Code First允许你使用代码来建立实体框架模型,同时允许用Data a ...
- WPF Step By Step 系列-Prism框架在项目中使用
WPF Step By Step 系列-Prism框架在项目中使用 回顾 上一篇,我们介绍了关于控件模板的用法,本节我们将继续说明WPF更加实用的内容,在大型的项目中如何使用Prism框架,并给予Pr ...
随机推荐
- keras + tensorflow安装
先安装anaconda 一条指令:conda install keras 就可以把keras,tensorflow装好.
- 并行(多进程)-python
1.进程创建 2.当前进程信息 使用current_process可获得当前进程的信息: (1)引入:from multiprocessing import current_process (2)获取 ...
- python 全栈开发,Day87(ajax登录示例,CSRF跨站请求伪造,Django的中间件,自定义分页)
一.ajax登录示例 新建项目login_ajax 修改urls.py,增加路径 from app01 import views urlpatterns = [ path('admin/', admi ...
- 《剑指offer》-找到数组中重复的数字
题目描述 在一个长度为n的数组里的所有数字都在0到n-1的范围内. 数组中某些数字是重复的,但不知道有几个数字是重复的.也不知道每个数字重复几次.请找出数组中任意一个重复的数字. 例如,如果输入长度为 ...
- 观察者模式(Observer Pattern)
一.概述在软件设计工作中会存在对象之间的依赖关系,当某一对象发生变化时,所有依赖它的对象都需要得到通知.如果设计的不好,很容易造成对象之间的耦合度太高,难以应对变化.使用观察者模式可以降低对象之间的依 ...
- poj 1251 poj 1258 hdu 1863 poj 1287 poj 2421 hdu 1233 最小生成树模板题
poj 1251 && hdu 1301 Sample Input 9 //n 结点数A 2 B 12 I 25B 3 C 10 H 40 I 8C 2 D 18 G 55D 1 E ...
- SpringBank 开发日志 一种简单的拦截器设计实现
当交易由Action进入Service之前,需要根据不同的Service实际负责业务的不同,真正执行Service的业务逻辑之前,做一些检查工作.这样的拦截器应该是基于配置的,与Service关联起来 ...
- BZOJ1036 [ZJOI2008]树的统计Count 树链剖分
欢迎访问~原文出处——博客园-zhouzhendong 去博客园看该题解 题目传送门 - BZOJ1036 题意概括 一个树,每个节点有一个权值.3种操作. 1:修改某一个节点的权值. 2:询问某两个 ...
- A Simple Math Problem HDU1757
一次ac 在做递推关系的题目的时候 快速幂矩阵真的很有用 #include<iostream> #include<cstdio> #include<cstring> ...
- Hat’s Words HDU1247
一个很经典的字典树题目 先建树 再拆单词进行判断是否都在树内 因为爆内存错了很久 如果一个四十万的数组 用mamset的话会直接爆几十万的内存 所以要:用多少 初始化多少才对!( 修改了两条初始化语 ...