SQL优化之count(*),count(列)
一、count各种用法的区别
1、count函数是日常工作中最常用的函数之一,用来统计表中数据的总数,常用的有count(*),count(1),count(列)。count(*)和count(1)是用来统计表中共有多少数据。是针对全表的
SELECT COUNT(*) FROM TAB1;
SELECT COUNT(1) FROM TAB1;
SELECT COUNT(*) FROM TAB1, TAB2; #显示两表做笛卡尔积后的行数
2、count(列)是针对于某一列的,如果此列值为空的话,count(列)是不会统计这一行的。NULL不会算在行数统计之内
CREATE TABLE T1(I int);
INSERT INTO T1 VALUES(1),(2),(NULL);
SELECT COUNT(*) FROM T1; # 结果为3
SELECT COUNT(*) FROM T1; # 结果为2
二、关于count的用法,谁更快
1、由上文可知,在数据库中count(*)和count(列)根本就是不等价的,count(*)是针对于全表的,而count(列)是针对于某一列的,如果此列值为空的话,count(列)是不会统计这一行的
所以两者根本没有可比性,性能比较首先要考虑写法等价,这两个语句根本就不等价的。也没有比较的意义。
2、建一张有25个字段的表并加入数据在进行count(*)和count(列)比较,分别执行count(*)和count每一列的操作来看一下谁更快。结果如下:
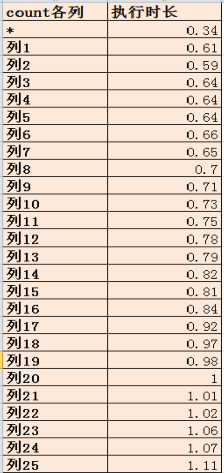
结论:列的偏移量决定性能,列越靠后,访问的开销越大。由于count(*)的算法与列偏移量无关,所以count(*) 最快,count( 最后列) 最慢所以:在设计表结构的过程中,越常用到的 列,要放在表结构的前边,不常用的列,放在表结构的后边。在工作中根据实际业务再考虑应该使用count(*)还是count(列)
PS: conut(1)和count(*)是一样的。但是在informix数据库中,对count(*)做过算法优化,远远快于count(1)。
三、关于SQL优化的一些误区
1、在联合查询中,和表的连接顺序无关。有人认为数据库的解析器是按顺序扫描from字句中的表名。应该选择小表作为基础表优先扫描(ps:如果现在的小表随着业务量的提升变成大表了,岂 不是要经常修改应用)。所以这种说法是不成立的,在联合查询中,以下的两种写法是没有区别的
T1(2条数据)
T2(1万条数据)
SELECT COUNT(*) FROM T1, T2;
SELECT COUNT(*) FROM T2, T1;
2、和where字句的连接顺序也无关。数据库在解析where字句时,也是按顺序解析(oracle是自下而上)。有些人认为where子句中排在最后的表应该是返回数据量少的表。这种说法也是不成立的
如:从T1表查到的数据比较少或该表的条件比较确定。
SELECT * FROM T1,T2 WHRE T1.A > 10 AND T2.B = 20;
SELECT * FROM T1,T2 WHRE T2.B = 20 AND T1.A > 10;
如果T2表返回数据量大,第二条SQL比第一条快(不成立)
3、用not exists取代not in是没有依据的(在oracle11g中都是采用高效的anti反连接算法)
SQL优化之count(*),count(列)的更多相关文章
- SQL优化之SELECT COUNT(*)
前言 SQL优化之SQL 进阶技巧(上) SQL优化之SQL 进阶技巧(下)中提到使用以下 sql 会导致慢查询 SELECT COUNT(*) FROM SomeTable SELECT COUNT ...
- SQL优化之SQL 进阶技巧(下)
上文( SQL优化之SQL 进阶技巧(上) )我们简述了 SQL 的一些进阶技巧,一些朋友觉得不过瘾,我们继续来下篇,再送你 10 个技巧 一. 使用延迟查询优化 limit [offset], [r ...
- SQL优化之SQL 进阶技巧(上)
由于工作需要,最近做了很多 BI 取数的工作,需要用到一些比较高级的 SQL 技巧,总结了一下工作中用到的一些比较骚的进阶技巧,特此记录一下,以方便自己查阅,主要目录如下: SQL 的书写规范 SQL ...
- 6.组函数(avg(),sum(),max(),min(),count())、多行函数,分组数据(group by,求各部门的平均工资),分组过滤(having和where),sql优化
1组函数 avg(),sum(),max(),min(),count()案例: selectavg(sal),sum(sal),max(sal),min(sal),count(sal) from ...
- 从多表连接后的select count(*)看待SQL优化
从多表连接后的select count(*)看待SQL优化 一朋友问我,以下这SQL能直接改写成select count(*) from a吗? SELECT COUNT(*) FROM a LEFT ...
- 关于数据库优化1——关于count(1),count(*),和count(列名)的区别,和关于表中字段顺序的问题
1.关于count(1),count(*),和count(列名)的区别 相信大家总是在工作中,或者是学习中对于count()的到底怎么用更快.一直有很大的疑问,有的人说count(*)更快,也有的人说 ...
- 慕课网 性能优化之MySQL优化--- max 和count的性能优化
注:在执行SQL语句前加上explain可以查看MySQL的执行计划 数据库:MySQL官方提供的sakila数据库 Max优化: 例如:查询最后支付时间 explain select max(pay ...
- SQL中AVG、COUNT、SUM、MAX等聚合函数对NULL值的处理
一.AVG() 求平均值注意AVE()忽略NULL值,而不是将其作为“0”参与计算 二.COUNT() 两种用法 1.COUNT(*) 对表中行数进行计数不管是否有NULL 2.COUNT(字段名) ...
- SQL语句中count(1)count(*)count(字段)用法的区别
SQL语句中count(1)count(*)count(字段)用法的区别 在SQL语句中count函数是最常用的函数之一,count函数是用来统计表中记录数的一个函数, 一. count(1)和cou ...
随机推荐
- 2019-03-14-day010-函数进阶
昨日回顾 1.函数: 函数的定义 函数的参数 位置参数 关键字参数 混合参数 形参的位置上(默认参数) 实参的位置上(关键字参数) 位置参数 > 默认参数 三元运算符: c = a if a&g ...
- springboot默认创建的bean是单实还是多例
转:https://blog.csdn.net/q1512451239/article/details/53122687 springboot默认创建的bean是单实还是多例 曾经面试的时候有面试官问 ...
- springboot区分开发、测试、生产多环境的应用配置
转:https://blog.csdn.net/daguairen/article/details/79236885 springboot区分开发.测试.生产多环境的应用配置(一) Spring可使用 ...
- 【Think in java读书笔记】序列化
Java的对象序列化将那些实现了Serializable接口的对象转换成一个字节序列,并能够在以后将这个字节序列完全恢复成为原来的对象. 序列化机制能自动弥补不同操作系统之间的差异,也就是说在Wind ...
- ArcGIS中的数据连接问题——数据类型不统一
博主在研究空间数据分布的时候经常会用到 ArcGIS 进行空间数据可视化.但是有时候会由于数据类型不统一而无法将 csv 中的数据连接到底图上.比如在底图中的数据是字符串格式,而 csv 中是数字格式 ...
- TensorRT caffemodel serialize
1.TensorRT的需要的文件 需要的基本文件(不是必须的) 1>网络结构文件(deploy.prototxt) 2>训练的权重模型(net.caffemodel) TensorRT 2 ...
- 【Eigen开源库】linux系统如何安装使用Eigen库
code /* * File : haedPose.cpp * Coder: * Date : 20181126 * Refer: https://www.learnopencv.com/head-p ...
- NOI-1.1-10-字符表示超级玛丽
10:超级玛丽游戏 总时间限制: 1000ms 内存限制: 65536kB 描述 超级玛丽是一个非常经典的游戏.请你用字符画的形式输出超级玛丽中的一个场景. 输入 无. 输出 如样例所示. 样 ...
- html播放音乐
如何在网站网页中添加音乐代码 告诉你多种格式文件的详细使用代码. width_num——指定一个作为宽度的数字: height_num——指定一个作为高度的数字: 1.mp3 ...
- [LeetCode&Python] Problem 258. Add Digits
Given a non-negative integer num, repeatedly add all its digits until the result has only one digit. ...