【转】Visual Studio——多字节编码与Unicode码
多字节字符与宽字节字符
1) char与wchar_t
我们知道C++基本数据类型中表示字符的有两种:char、wchar_t。
char叫多字节字符,一个char占一个字节,之所以叫多字节字符是因为它表示一个字时可能是一个字节也可能是多个字节。一个英文字符(如’s’)用一个char(一个字节)表示,一个中文汉字(如’中’)用3个char(三个字节)表示,看下面的例子。
void TestChar()
{
char ch1 = 's'; // 正确
cout << "ch1:" << ch1 << endl;
char ch2 = '中'; // 错误,一个char不能完整存放一个汉字信息
cout << "ch2:" << ch2 << endl; char str[] = "中"; //前三个字节存放汉字'中',最后一个字节存放字符串结束符\0
cout << "str:" << str << endl;
//char str2[2] = "国"; // 错误:'str2' : array bounds overflow
//cout << str2 << endl;
}
结果如下:
ch1:s
ch2:
str:中
wchar_t被称为宽字符,一个wchar_t占2个字节。之所以叫宽字符是因为所有的字都要用两个字节(即一个wchar_t)来表示,不管是英文还是中文。看下面的例子:
void TestWchar_t()
{
wcout.imbue(locale("chs")); // 将wcout的本地化语言设置为中文 wchar_t wch1 = L's'; // 正确
wcout << "ch1:" << wch1 << endl;
wchar_t wch2 = L'中'; // 正确,一个汉字用一个wchar_t表示
wcout << "ch2:" << wch2 << endl; wchar_t wstr[] = L"中"; // 前两个字节(前一个wchar_t)存放汉字'中',最后两个字节(后一个wchar_t)存放字符串结束符\0
wcout << "str:" << wstr << endl;
wchar_t wstr2[] = L"中国";
wcout << "str2:" << wstr2 << endl;
}
结果如下:
ch1:s
ch2:中
str:中
str2:中国
说明:
1. 用常量字符给wchar_t变量赋值时,前面要加L。如: wchar_t wch2 = L’中’;
2. 用常量字符串给wchar_t数组赋值时,前面要加L。如: wchar_t wstr2[3] = L”中国”;
3. 如果不加L,对于英文可以正常,但对于非英文(如中文)会出错。
2)string与wstring
字符数组可以表示一个字符串,但它是一个定长的字符串,我们在使用之前必须知道这个数组的长度。为方便字符串的操作,STL为我们定义好了字符串的类string和wstring。大家对string肯定不陌生,但wstring可能就用的少了。
string是普通的多字节版本,是基于char的,对char数组进行的一种封装。
wstring是Unicode版本,是基于wchar_t的,对wchar_t数组进行的一种封装。
string与wstring的相关转换:
以下的两个方法是跨平台的,可在Windows下使用,也可在Linux下使用。
#include <cstdlib>
#include <string.h>
#include <string> // wstring => string
std::string WString2String(const std::wstring& ws)
{
std::string strLocale = setlocale(LC_ALL, "");
const wchar_t* wchSrc = ws.c_str();
size_t nDestSize = wcstombs(NULL, wchSrc, ) + ;
char *chDest = new char[nDestSize];
memset(chDest,,nDestSize);
wcstombs(chDest,wchSrc,nDestSize);
std::string strResult = chDest;
delete []chDest;
setlocale(LC_ALL, strLocale.c_str());
return strResult;
} // string => wstring
std::wstring String2WString(const std::string& s)
{
std::string strLocale = setlocale(LC_ALL, "");
const char* chSrc = s.c_str();
size_t nDestSize = mbstowcs(NULL, chSrc, ) + ;
wchar_t* wchDest = new wchar_t[nDestSize];
wmemset(wchDest, , nDestSize);
mbstowcs(wchDest,chSrc,nDestSize);
std::wstring wstrResult = wchDest;
delete []wchDest;
setlocale(LC_ALL, strLocale.c_str());
return wstrResult;
}
字符集(Charcater Set)与字符编码(Encoding)
字符集(Charcater Set或Charset):是一个系统支持的所有抽象字符的集合,也就是一系列字符的集合。字符是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。常见的字符集有:ASCII字符集、GB2312字符集(主要用于处理中文汉字)、GBK字符集(主要用于处理中文汉字)、Unicode字符集等。
字符编码(Character Encoding):是一套法则,使用该法则能够对自然语言的字符的一个字符集(如字母表或音节表),与计算机能识别的二进制数字进行配对。即它能在符号集合与数字系统之间建立对应关系,是信息处理的一项基本技术。通常人们用符号集合(一般情况下就是文字)来表达信息,而计算机的信息处理系统则是以二进制的数字来存储和处理信息的。字符编码就是将符号转换为计算机能识别的二进制编码。
一般一个字符集等同于一个编码方式,ANSI体系(ANSI是一种字符代码,为使计算机支持更多语言,通常使用 0x80~0xFF 范围的 2 个字节来表示 1 个字符)的字符集如ASCII、ISO 8859-1、GB2312、GBK等等都是如此。一般我们说一种编码都是针对某一特定的字符集。
一个字符集上也可以有多种编码方式,例如UCS字符集(也是Unicode使用的字符集)上有UTF-8、UTF-16、UTF-32等编码方式。
从计算机字符编码的发展历史角度来看,大概经历了三个阶段:
第一个阶段:ASCII字符集和ASCII编码。
计算机刚开始只支持英语(即拉丁字符),其它语言不能够在计算机上存储和显示。ASCII用一个字节(Byte)的7位(bit)表示一个字符,第一位置0。后来为了表示更多的欧洲常用字符又对ASCII进行了扩展,又有了EASCII,EASCII用8位表示一个字符,使它能多表示128个字符,支持了部分西欧字符。
第二个阶段:ANSI编码(本地化)
为使计算机支持更多语言,通常使用 0x80~0xFF 范围的 2 个字节来表示 1 个字符。比如:汉字 ‘中’ 在中文操作系统中,使用 [0xD6,0xD0] 这两个字节存储。
不同的国家和地区制定了不同的标准,由此产生了 GB2312, BIG5, JIS 等各自的编码标准。这些使用 2 个字节来代表一个字符的各种汉字延伸编码方式,称为 ANSI 编码。在简体中文系统下,ANSI 编码代表 GB2312 编码,在日文操作系统下,ANSI 编码代表 JIS 编码。
不同 ANSI 编码之间互不兼容,当信息在国际间交流时,无法将属于两种语言的文字,存储在同一段 ANSI 编码的文本中。
第三个阶段:UNICODE(国际化)
为了使国际间信息交流更加方便,国际组织制定了 UNICODE 字符集,为各种语言中的每一个字符设定了统一并且唯一的数字编号,以满足跨语言、跨平台进行文本转换、处理的要求。UNICODE 常见的有三种编码方式:UTF-8(1个字节表示)、UTF-16((2个字节表示))、UTF-32(4个字节表示)。
我们可以用一个树状图来表示由ASCII发展而来的各个字符集和编码的分支:
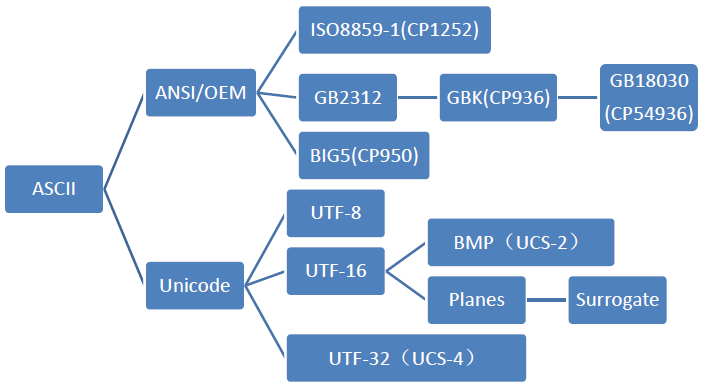
图1.各种类型的编译
如果要更详细地了解字符集和字符编码请参考:
工程里多字节字符与宽字符的配置
右键你的工程名->Properties,设置如下:
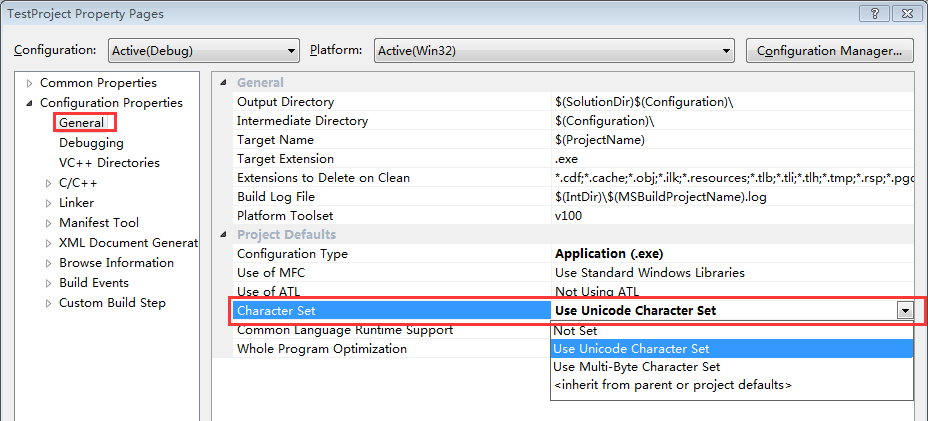
图2.Character Set
1、当设置为Use Unicode Character Set时,会有预编译宏:_UNICODE、UNICODE
图3.Unicode
2、当设置为Use Multi-Byte Character Set时,会有预编译宏:_MBCS

图4.Multi-Byte
Unicode Character Set与Multi-Byte Character Set有什么区别呢?
Unicode Character Set和Multi-Byte Character Set这两个设置有什么区别呢?我们来看一个例子:
有一个程序需要用MessageBox弹出提示框:
#include "windows.h" void TestMessageBox()
{
::MessageBox(NULL, "这是一个测试程序!", "Title", MB_OK);
}
上面这个Demo非常简单不用多说了吧!我们将Character Set设置为Multi-Byte Character Set时,可以正常编译和运行。但当我们设置为Unicode Character Set,则会有以下编译错误:
error C2664: ‘MessageBoxW’ : cannot convert parameter from ‘const char []’ to ‘LPCWSTR’
这是因为MessageBox有两个版本,一个MessageBoxW针对Unicode版的,一个是MessageBoxA针对Multi-Byte的,它们通过不同宏进行隔开,预设不同的宏会使用不同的版本。我们使用了Use Unicode Character Set就预设了_UNICODE、UNICODE宏,所以编译时就会使用MessageBoxW,这时我们传入多字节常量字符串肯定会有问题,而应该传入宽符的字符串,即将”Title”改为L”Title”就可以了,”这是一个测试程序!”也一样。
WINUSERAPI
int
WINAPI
MessageBoxA(
__in_opt HWND hWnd,
__in_opt LPCSTR lpText,
__in_opt LPCSTR lpCaption,
__in UINT uType);
WINUSERAPI
int
WINAPI
MessageBoxW(
__in_opt HWND hWnd,
__in_opt LPCWSTR lpText,
__in_opt LPCWSTR lpCaption,
__in UINT uType);
#ifdef UNICODE
#define MessageBox MessageBoxW
#else
#define MessageBox MessageBoxA
#endif // !UNICODE
上面的Multi-Byte Character Set一般是指ANSI(多字节)字符集,关于ANSI请参考第二小节“字符集(Charcater Set)与字符编码(Encoding)”。而Unicode Character Set就是Unicode字符集,一般是指UTF-16编码的Unicode。也就是说每个字符编码为两个字节,两个字节可以表示65535个字符,65535个字符可以表示世界上大部分的语言。
一般推荐使用Unicode的方式,因为它可以适应各个国家语言,在进行软件国际时将会非常便得。除非在对存储要求非常高的时候,或要兼容C的代码时,我们才会使用多字节的方式 。
理解_T()、_Text()宏及L" "
上一小节对MessageBox的调用中除了使用L"Title"外,还可以使用_T(“Title”)和_TEXT(“Title”)。而且你会发现在MFC和Win32程序中会更多地使用_T和_TEXT,那_T、_TEXT和L之间有什么区别呢?
通过第一小节多字节字符与宽字节字符我们知道表示多字节字符(char)串常量时用一般的双引号括起来就可以了,如"String test";而表示宽字节字符(wchar_t)串常量时要在引号前加L,如L”String test”。
查看tchar.h头文件的定义我们知道_T和_TEXT的功能是一样的,是一个预定义的宏。
#define _T(x) __T(x)
#define _TEXT(x) __T(x)
我们再看看__T(x)的定义,发现它有两个:
#ifdef _UNICODE
// ... 省略其它代码
#define __T(x) L ## x
// ... 省略其它代码
#else /* ndef _UNICODE */
// ... 省略其它代码
#define __T(x) x
// ... 省略其它代码
#endif /* _UNICODE */
这下明白了吗?当我们的工程的Character Set设置为Use Unicode Character Set时_T和_TEXT就会在常量字符串前面加L,否则(即Use Multi-Byte Character Set时)就会以一般的字符串处理。
Dword、LPSTR、LPWSTR、LPCSTR、LPCWSTR、LPTSTR、LPCTSTR
VC++中还有一些常用的宏你也许会范糊涂,如Dword、LPSTR、LPWSTR、LPCSTR、LPCWSTR、LPTSTR、LPCTSTR。这里我们统一总结一下:
常见的宏:
| 类型 | MBCS | UNICODE |
|---|---|---|
| WCHAR | wchar_t | wchar_t |
| LPSTR | char* | char* |
| LPCSTR | const char* | const char* |
| LPWSTR | wchar_t* | wchar_t* |
| LPCWSTR | const wchar_t* | const wchar_t* |
| TCHAR | char | wchar_t |
| LPTSTR | TCHAR*(或char*) | TCHAR* (或wchar_t*) |
| LPCTSTR | const TCHAR* | const TCHAR* |
P表示这是一个指针。
T表示_T宏,这个宏用来表示你的字符是否使用UNICODE, 如果你的程序定义了UNICODE或者其他相关的宏,那么这个字符或者字符串将被作为UNICODE字符串,否则就是标准的ANSI字符串。
STR表示这个变量是一个字符串。
C表示是一个常量,const。
LPTSTR:LPSTR、LPWSTR两者二选一,取决于是否宏定义了UNICODE或ANSI
LPCTSTR: LPCSTR、LPCWSTR两者二选一,取决于是否宏定义了UNICODE或ANSI
#ifdef UNICODE
typedef LPWSTR LPTSTR;
typedef LPCWSTR LPCTSTR;
#else
typedef LPSTR LPTSTR;
typedef LPCSTR LPCTSTR;
#endif
相互转换方法:
LPWSTR->LPTSTR: W2T();
LPTSTR->LPWSTR: T2W();
LPCWSTR->LPCSTR: W2CT();
LPCSTR->LPCWSTR: T2CW();
ANSI->UNICODE: A2W();
UNICODE->ANSI: W2A();
字符串函数:
还有一些字符串的操作函数,它们也有一 一对应关系:
| MBCS | UNICODE |
|---|---|
| strlen(); | wcslen(); |
| strcpy(); | wcscpy(); |
| strcmp(); | wcscmp(); |
| strcat(); | wcscat(); |
| strchr(); | wcschr(); |
| … | … |
通过这些函数和宏的命名你也许就发现了一些规律,一般带有前缀w(或后缀W)的都是用于宽字符的,而不带前缀w(或带有后缀A)的一般是用于多字节字符的。
理解CString产生的原因与工作的机理
CString:动态的TCHAR数组,是对TCHAR数组的一种封闭。它是一个完全独立的类,封装了“+”等操作符和字符串操作方法,换句话说就是CString是对TCHAR操作的方法的集合。它的作用是方便WIN32程序和MFC程序进行字符串的处理和类型的转换。
转自《带你玩转Visual Studio——带你理解多字节编码与Unicode码》
【转】Visual Studio——多字节编码与Unicode码的更多相关文章
- 转: 带你玩转Visual Studio——带你理解多字节编码与Unicode码
上一篇文章带你玩转Visual Studio——带你跳出坑爹的Runtime Library坑帮我们理解了Windows中的各种类型C/C++运行时库及它的来龙去脉,这是C++开发中特别容易误入歧途的 ...
- 带你玩转Visual Studio——带你理解多字节编码与Unicode码
目录(?)[-] 多字节字符与宽字节字符 char与wchar_t string与wstring string 与 wstring的相关转换 字符集Charcater Set与字符编码Encoding ...
- C++进阶—>带你理解多字节编码与Unicode码
参考网址:https://blog.csdn.net/u011028345/article/details/78516320 多字节字符与宽字节字符 char与wchar_t 我们知道C++基本数据类 ...
- MySql轻松入门系列——第二站 使用visual studio 对mysql进行源码级调试
一:背景 1. 讲故事 上一篇说了mysql的架构图,很多同学反馈说不过瘾,毕竟还是听我讲故事,那这篇就来说一说怎么利用visual studio 对 mysql进行源码级调试,毕竟源码面前,不谈隐私 ...
- VS2010与VS2013中的多字节编码与Unicode编码问题
1. 多字节字符与单字节字符 char与wchar_t 我们知道C++基本数据类型中表示字符的有两种:char.wchar_t. char叫多字节字符,一个char占一个字节,之所以叫多字节字符是因 ...
- Visual Studio 2017 序列号 Key 激活码 VS2017 注册码
Visual Studio 2017(VS2017) 企业版 Enterprise 注册码 序列号:NJVYC-BMHX2-G77MM-4XJMR-6Q8QF Visual Studio 2017(V ...
- Visual Studio调试到OpenCV源码中
TL;DR VS2015下,build-farm/vs2015-x64/bin/Debug/目录,*.pdb文件,都拷贝到install/x64/vc14/bin目录,就可以调试进去opencv源码了 ...
- Visual Studio Code - 在 JS 源码(TS、压缩前代码)上使用断点
步骤: 在构建工具(webpack.gulp 等)的配置中开启生成 source map 将 VSCode 配置中的debug.allowBreakpointsEverywhere设置为true(重要 ...
- 带你玩转Visual Studio
带你玩转Visual Studio 带你新建一个工程 工程目录下各文件的含义 解决方案与工程 在这之前先了解一个概念:解决方案与工程. 解决方案(Solution):一个大型项目的整体的工作环境: 工 ...
随机推荐
- 洛谷P2668 斗地主
好,终于搞完了这一道毒瘤题...... 先想到搜索,然后想到状压,发现数据组数很多,又是随机,还是决定用搜索. 先搜出的多的,于是顺序是三个顺子,然后按照多到少搜带牌,最后是不带牌. 大体思路很简单, ...
- activeMQ点对点
摘要: ActiveMQ 点对点消息 Point-to-Point 是一对一 创建消息生产者 /** * 点对点消息生产者 * * @author Edward * */ public ...
- 走近HTTP协议之一 基本网络概念与理解
当今的技术领域,开发者人数最为之多的群体便是web领域,与之相关岗位的包括前端工程师,后台工程师,移动端开发工程师等等.然而由于受时代浮躁氛围的影响,许多开发者对最为基础的HTTP协议都不甚了解,这也 ...
- 在IIS6中配置html文件以ASPX方式工作
在IIS6中配置html文件以ASPX方式工作 由于IIS6的安全不断提高,如果你需要设置html文件以ASPX文件方式被执行.仅仅设置应用程序映射是不够的,还 需要修改一些其他设置. 如果你只修改了 ...
- windows 2003 IIS FTP 530 home directory inaccessible
在 Windows Server 2003 及更新的版本中,IIS 中的 FTP 可以使用用户隔离了. 隔离有什么好处呢? 看起来更高级.比如 ftp1 用户打开的时候看到的路径是 /,但内容是自己文 ...
- 基于pycaffe的网络训练和结果分析(mnist数据集)
该工作的主要目的是为了练习运用pycaffe来进行神经网络一站式训练,并从多个角度来分析对应的结果. 目标: python的运用训练 pycaffe的接口熟悉 卷积网络(CNN)和全连接网络(DNN) ...
- 教你如何用Meterpreter渗透Win系统
在这篇文章中,我们将跟大家介绍如何使用Meterpreter来收集目标Windows系统中的信息,获取用户凭证,创建我们自己的账号,启用远程桌面,进行屏幕截图,以及获取用户键盘记录等等. 相关Payl ...
- 怎样解决Myeclipse内存溢出?
打开myeclipse 10安装目录下的myeclipse.ini文件 打开文件,将文件圈圈中的内容设置如下图: 上面是其中一种解决方案,下面介绍第二种解决方案 设置Default VM Argume ...
- JVM总结(二):垃圾回收器
这一节我们来总结一下JVM垃圾收集器方面的东西. 垃圾回收器 判断对象引用是否失效 对象生存判断算法 引用判断过程 垃圾收集算法简介 垃圾收集器 新生代垃圾收集器 老年代垃圾收集器 新生代和老年代垃圾 ...
- hashmap和hashtable异同
(一)继承的历史不同 Hashtable是继承自Dictionary类的,而HashMap则是Java 1.2引进的Map接口的一个实现. public class Hashtable extends ...