WGAN源码解读
WassersteinGAN源码
作者的代码包括两部分:models包下包含dcgan.py和mlp.py, 这两个py文件是两种不同的网络结构,在dcgan.py中判别器和生成器都含有卷积网络,而mlp.py中判别器和生成器都只是全连接。 此外main.py为主函数,通过引入import models中的生成器和判别器来完成训练与迭代。
参数说明(main.py中):
parser = argparse.ArgumentParser()
parser.add_argument('--dataset', required=True, help='cifar10 | lsun | imagenet | folder | lfw ')
parser.add_argument('--dataroot', required=True, help='path to dataset')
parser.add_argument('--workers', type=int, help='number of data loading workers', default=2)
parser.add_argument('--batchSize', type=int, default=64, help='input batch size')
parser.add_argument('--imageSize', type=int, default=64, help='the height / width of the input image to network')
parser.add_argument('--nc', type=int, default=3, help='input image channels')
parser.add_argument('--nz', type=int, default=100, help='size of the latent z vector')
parser.add_argument('--ngf', type=int, default=64)
parser.add_argument('--ndf', type=int, default=64)
parser.add_argument('--niter', type=int, default=25, help='number of epochs to train for')
parser.add_argument('--lrD', type=float, default=0.00005, help='learning rate for Critic, default=0.00005')
parser.add_argument('--lrG', type=float, default=0.00005, help='learning rate for Generator, default=0.00005')
parser.add_argument('--beta1', type=float, default=0.5, help='beta1 for adam. default=0.5')
parser.add_argument('--cuda' , action='store_true', help='enables cuda')
parser.add_argument('--ngpu' , type=int, default=1, help='number of GPUs to use')
parser.add_argument('--netG', default='', help="path to netG (to continue training)")
parser.add_argument('--netD', default='', help="path to netD (to continue training)")
parser.add_argument('--clamp_lower', type=float, default=-0.01)
parser.add_argument('--clamp_upper', type=float, default=0.01)
parser.add_argument('--Diters', type=int, default=5, help='number of D iters per each G iter')
parser.add_argument('--noBN', action='store_true', help='use batchnorm or not (only for DCGAN)')
parser.add_argument('--mlp_G', action='store_true', help='use MLP for G')
parser.add_argument('--mlp_D', action='store_true', help='use MLP for D')
parser.add_argument('--n_extra_layers', type=int, default=0, help='Number of extra layers on gen and disc')
parser.add_argument('--experiment', default=None, help='Where to store samples and models')
parser.add_argument('--adam', action='store_true', help='Whether to use adam (default is rmsprop)')
1.models包中的mlp.py:
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from __future__ import unicode_literals
import torch
import torch.nn as nn class MLP_G(nn.Module):
def __init__(self, isize, nz, nc, ngf, ngpu):
super(MLP_G, self).__init__()
self.ngpu = ngpu main = nn.Sequential(
# Z goes into a linear of size: ngf
nn.Linear(nz, ngf),
nn.ReLU(True),
nn.Linear(ngf, ngf),
nn.ReLU(True),
nn.Linear(ngf, ngf),
nn.ReLU(True),
nn.Linear(ngf, nc * isize * isize),
)
self.main = main
self.nc = nc
self.isize = isize
self.nz = nz def forward(self, input):
input = input.view(input.size(0), input.size(1))
if isinstance(input.data, torch.cuda.FloatTensor) and self.ngpu > 1:
output = nn.parallel.data_parallel(self.main, input, range(self.ngpu))
else:
output = self.main(input)
return output.view(output.size(0), self.nc, self.isize, self.isize) class MLP_D(nn.Module):
def __init__(self, isize, nz, nc, ndf, ngpu):
super(MLP_D, self).__init__()
self.ngpu = ngpu main = nn.Sequential(
# Z goes into a linear of size: ndf
nn.Linear(nc * isize * isize, ndf),
nn.ReLU(True),
nn.Linear(ndf, ndf),
nn.ReLU(True),
nn.Linear(ndf, ndf),
nn.ReLU(True),
nn.Linear(ndf, 1),
)
self.main = main
self.nc = nc
self.isize = isize
self.nz = nz def forward(self, input):
input = input.view(input.size(0),
input.size(1) * input.size(2) * input.size(3))
if isinstance(input.data, torch.cuda.FloatTensor) and self.ngpu > 1:
output = nn.parallel.data_parallel(self.main, input, range(self.ngpu))
else:
output = self.main(input)
output = output.mean(0)
return output.view(1)
mlp.py
在利用全连接实现的网络中,生成器的结构为四层全连接,伴有4个ReLU激活函数。噪声即生成器的输入,其维度为 nz=100维。所以生成器的输入维度为(batch_size, nz), 输出为图像的尺寸(batch_size, nc, isize, isize)。注意的是torch.nn只支持mini_batch,若想输入单个样本,可利用input.unsqueeze(0)将batch_size设为1。WGAN的判别器与GAN不同之处是最后一层取消了sigmoid,其结构也为4层全连接。判别器的输入为图像的尺寸,同时判别器的输入为生成器的输出,而输出为1维,即batch_size大小的向量,求mean得到一个数。
此外代码中还对 ngpu>1 的情形下使用Multi-GPU layers: class torch.nn.DataParallel(module, device_ids=None, output_device=None, dim=0) 此容器通过将mini-batch划分到不同的设备上来实现给定module的并行。在forward过程中,module会在每个设备上都复制一遍,每个副本都会处理部分输入。在backward过程中,副本上的梯度会累加到原始module上。
batch的大小应该大于所使用的GPU的数量。还应当是GPU个数的整数倍,这样划分出来的每一块都会有相同的样本数量。
2.models包中的dcgan.py
import torch
import torch.nn as nn
import torch.nn.parallel class DCGAN_D(nn.Module):
def __init__(self, isize, nz, nc, ndf, ngpu, n_extra_layers=0):
super(DCGAN_D, self).__init__()
self.ngpu = ngpu
assert isize % 16 == 0, "isize has to be a multiple of 16" main = nn.Sequential()
# input is nc x isize x isize
main.add_module('initial.conv.{0}-{1}'.format(nc, ndf),
nn.Conv2d(nc, ndf, 4, 2, 1, bias=False))
main.add_module('initial.relu.{0}'.format(ndf),
nn.LeakyReLU(0.2, inplace=True))
csize, cndf = isize / 2, ndf # Extra layers
for t in range(n_extra_layers):
main.add_module('extra-layers-{0}.{1}.conv'.format(t, cndf),
nn.Conv2d(cndf, cndf, 3, 1, 1, bias=False))
main.add_module('extra-layers-{0}.{1}.batchnorm'.format(t, cndf),
nn.BatchNorm2d(cndf))
main.add_module('extra-layers-{0}.{1}.relu'.format(t, cndf),
nn.LeakyReLU(0.2, inplace=True)) while csize > 4:
in_feat = cndf
out_feat = cndf * 2
main.add_module('pyramid.{0}-{1}.conv'.format(in_feat, out_feat),
nn.Conv2d(in_feat, out_feat, 4, 2, 1, bias=False))
main.add_module('pyramid.{0}.batchnorm'.format(out_feat),
nn.BatchNorm2d(out_feat))
main.add_module('pyramid.{0}.relu'.format(out_feat),
nn.LeakyReLU(0.2, inplace=True))
cndf = cndf * 2
csize = csize / 2 # state size. K x 4 x 4
main.add_module('final.{0}-{1}.conv'.format(cndf, 1),
nn.Conv2d(cndf, 1, 4, 1, 0, bias=False))
self.main = main def forward(self, input):
if isinstance(input.data, torch.cuda.FloatTensor) and self.ngpu > 1:
output = nn.parallel.data_parallel(self.main, input, range(self.ngpu))
else:
output = self.main(input) output = output.mean(0)
return output.view(1) class DCGAN_G(nn.Module):
def __init__(self, isize, nz, nc, ngf, ngpu, n_extra_layers=0):
super(DCGAN_G, self).__init__()
self.ngpu = ngpu
assert isize % 16 == 0, "isize has to be a multiple of 16" cngf, tisize = ngf//2, 4
while tisize != isize:
cngf = cngf * 2
tisize = tisize * 2 main = nn.Sequential()
# input is Z, going into a convolution
main.add_module('initial.{0}-{1}.convt'.format(nz, cngf),
nn.ConvTranspose2d(nz, cngf, 4, 1, 0, bias=False))
main.add_module('initial.{0}.batchnorm'.format(cngf),
nn.BatchNorm2d(cngf))
main.add_module('initial.{0}.relu'.format(cngf),
nn.ReLU(True)) csize, cndf = 4, cngf
while csize < isize//2:
main.add_module('pyramid.{0}-{1}.convt'.format(cngf, cngf//2),
nn.ConvTranspose2d(cngf, cngf//2, 4, 2, 1, bias=False))
main.add_module('pyramid.{0}.batchnorm'.format(cngf//2),
nn.BatchNorm2d(cngf//2))
main.add_module('pyramid.{0}.relu'.format(cngf//2),
nn.ReLU(True))
cngf = cngf // 2
csize = csize * 2 # Extra layers
for t in range(n_extra_layers):
main.add_module('extra-layers-{0}.{1}.conv'.format(t, cngf),
nn.Conv2d(cngf, cngf, 3, 1, 1, bias=False))
main.add_module('extra-layers-{0}.{1}.batchnorm'.format(t, cngf),
nn.BatchNorm2d(cngf))
main.add_module('extra-layers-{0}.{1}.relu'.format(t, cngf),
nn.ReLU(True)) main.add_module('final.{0}-{1}.convt'.format(cngf, nc),
nn.ConvTranspose2d(cngf, nc, 4, 2, 1, bias=False))
main.add_module('final.{0}.tanh'.format(nc),
nn.Tanh())
self.main = main def forward(self, input):
if isinstance(input.data, torch.cuda.FloatTensor) and self.ngpu > 1:
output = nn.parallel.data_parallel(self.main, input, range(self.ngpu))
else:
output = self.main(input)
return output
###############################################################################
class DCGAN_D_nobn(nn.Module):
def __init__(self, isize, nz, nc, ndf, ngpu, n_extra_layers=0):
super(DCGAN_D_nobn, self).__init__()
self.ngpu = ngpu
assert isize % 16 == 0, "isize has to be a multiple of 16" main = nn.Sequential()
# input is nc x isize x isize
# input is nc x isize x isize
main.add_module('initial.conv.{0}-{1}'.format(nc, ndf),
nn.Conv2d(nc, ndf, 4, 2, 1, bias=False))
main.add_module('initial.relu.{0}'.format(ndf),
nn.LeakyReLU(0.2, inplace=True))
csize, cndf = isize / 2, ndf # Extra layers
for t in range(n_extra_layers):
main.add_module('extra-layers-{0}.{1}.conv'.format(t, cndf),
nn.Conv2d(cndf, cndf, 3, 1, 1, bias=False))
main.add_module('extra-layers-{0}.{1}.relu'.format(t, cndf),
nn.LeakyReLU(0.2, inplace=True)) while csize > 4:
in_feat = cndf
out_feat = cndf * 2
main.add_module('pyramid.{0}-{1}.conv'.format(in_feat, out_feat),
nn.Conv2d(in_feat, out_feat, 4, 2, 1, bias=False))
main.add_module('pyramid.{0}.relu'.format(out_feat),
nn.LeakyReLU(0.2, inplace=True))
cndf = cndf * 2
csize = csize / 2 # state size. K x 4 x 4
main.add_module('final.{0}-{1}.conv'.format(cndf, 1),
nn.Conv2d(cndf, 1, 4, 1, 0, bias=False))
self.main = main def forward(self, input):
if isinstance(input.data, torch.cuda.FloatTensor) and self.ngpu > 1:
output = nn.parallel.data_parallel(self.main, input, range(self.ngpu))
else:
output = self.main(input) output = output.mean(0)
return output.view(1) class DCGAN_G_nobn(nn.Module):
def __init__(self, isize, nz, nc, ngf, ngpu, n_extra_layers=0):
super(DCGAN_G_nobn, self).__init__()
self.ngpu = ngpu
assert isize % 16 == 0, "isize has to be a multiple of 16" cngf, tisize = ngf//2, 4
while tisize != isize:
cngf = cngf * 2
tisize = tisize * 2 main = nn.Sequential()
main.add_module('initial.{0}-{1}.convt'.format(nz, cngf),
nn.ConvTranspose2d(nz, cngf, 4, 1, 0, bias=False))
main.add_module('initial.{0}.relu'.format(cngf),
nn.ReLU(True)) csize, cndf = 4, cngf
while csize < isize//2:
main.add_module('pyramid.{0}-{1}.convt'.format(cngf, cngf//2),
nn.ConvTranspose2d(cngf, cngf//2, 4, 2, 1, bias=False))
main.add_module('pyramid.{0}.relu'.format(cngf//2),
nn.ReLU(True))
cngf = cngf // 2
csize = csize * 2 # Extra layers
for t in range(n_extra_layers):
main.add_module('extra-layers-{0}.{1}.conv'.format(t, cngf),
nn.Conv2d(cngf, cngf, 3, 1, 1, bias=False))
main.add_module('extra-layers-{0}.{1}.relu'.format(t, cngf),
nn.ReLU(True)) main.add_module('final.{0}-{1}.convt'.format(cngf, nc),
nn.ConvTranspose2d(cngf, nc, 4, 2, 1, bias=False))
main.add_module('final.{0}.tanh'.format(nc),
nn.Tanh())
self.main = main def forward(self, input):
if isinstance(input.data, torch.cuda.FloatTensor) and self.ngpu > 1:
output = nn.parallel.data_parallel(self.main, input, range(self.ngpu))
else:
output = self.main(input)
return output
dcgan.py
此文件中共4个类,分为两组。第一组是DCGAN_D和DCGAN_G, 这两个类都使用了Batch normalization。而另一组是DCGAN_D_nobn和DCGAN_G_nobn, 这两个类都没有使用Batch normalization。首先看判别器,设定了image的尺寸为16的倍数,然后经过一个卷积层和一个LeakyReLU后来到Extra layers, 在这个其他层中当参数 n_extra_layers 为n时, 将Conv-BN-LeakyReLU重复n次,此时判断如果特征图大小 >4, 则再次进行Conv-BN-LeakyReLU操作直到特征图大小 =4,然后进行最后一次卷积核大小为4的卷积,此时输出为1维向量,求均值后得到一个数。
然后看生成器,生成器用到了反卷积,因为其输入为100维噪声数据(类似向量),输出为图像(类似矩阵)。首先经过ConvTranspose2d-BN-ReLU, 将100维的噪声反卷积为512维。然后经过一系列(3次)ConvTranspose2d-BN-ReLU将特征图维度改为了64通道。此时又来到了Extra layers, 在这个其他层中当参数 n_extra_layers 为n时, 将ConvTranspose2d-BN-ReLU重复n次,注意此时n次反卷积设置为通道数不变的反卷积,所以若经过这n次操作,通道数仍为64维。最后经过ConvTranspose2d-Tanh后,将通道数将为了3,数值大小都在-1至1之间。
对于两组文件不同之处只有BN的使用与否,所以不必赘述。
3.main.py
from __future__ import print_function
import argparse
import random
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.backends.cudnn as cudnn
import torch.optim as optim
import torch.utils.data
import torchvision.datasets as dset
import torchvision.transforms as transforms
import torchvision.utils as vutils
from torch.autograd import Variable
import os import models.dcgan as dcgan
import models.mlp as mlp parser = argparse.ArgumentParser()
parser.add_argument('--dataset', required=True, help='cifar10 | lsun | imagenet | folder | lfw ')
parser.add_argument('--dataroot', required=True, help='path to dataset')
parser.add_argument('--workers', type=int, help='number of data loading workers', default=2)
parser.add_argument('--batchSize', type=int, default=64, help='input batch size')
parser.add_argument('--imageSize', type=int, default=64, help='the height / width of the input image to network')
parser.add_argument('--nc', type=int, default=3, help='input image channels')
parser.add_argument('--nz', type=int, default=100, help='size of the latent z vector')
parser.add_argument('--ngf', type=int, default=64)
parser.add_argument('--ndf', type=int, default=64)
parser.add_argument('--niter', type=int, default=25, help='number of epochs to train for')
parser.add_argument('--lrD', type=float, default=0.00005, help='learning rate for Critic, default=0.00005')
parser.add_argument('--lrG', type=float, default=0.00005, help='learning rate for Generator, default=0.00005')
parser.add_argument('--beta1', type=float, default=0.5, help='beta1 for adam. default=0.5')
parser.add_argument('--cuda' , action='store_true', help='enables cuda')
parser.add_argument('--ngpu' , type=int, default=1, help='number of GPUs to use')
parser.add_argument('--netG', default='', help="path to netG (to continue training)")
parser.add_argument('--netD', default='', help="path to netD (to continue training)")
parser.add_argument('--clamp_lower', type=float, default=-0.01)
parser.add_argument('--clamp_upper', type=float, default=0.01)
parser.add_argument('--Diters', type=int, default=5, help='number of D iters per each G iter')
parser.add_argument('--noBN', action='store_true', help='use batchnorm or not (only for DCGAN)')
parser.add_argument('--mlp_G', action='store_true', help='use MLP for G')
parser.add_argument('--mlp_D', action='store_true', help='use MLP for D')
parser.add_argument('--n_extra_layers', type=int, default=0, help='Number of extra layers on gen and disc')
parser.add_argument('--experiment', default=None, help='Where to store samples and models')
parser.add_argument('--adam', action='store_true', help='Whether to use adam (default is rmsprop)')
opt = parser.parse_args()
print(opt) if opt.experiment is None:
opt.experiment = 'samples'
os.system('mkdir {0}'.format(opt.experiment)) opt.manualSeed = random.randint(1, 10000) # fix seed
print("Random Seed: ", opt.manualSeed)
random.seed(opt.manualSeed)
torch.manual_seed(opt.manualSeed) cudnn.benchmark = True if torch.cuda.is_available() and not opt.cuda:
print("WARNING: You have a CUDA device, so you should probably run with --cuda") if opt.dataset in ['imagenet', 'folder', 'lfw']:
# folder dataset
dataset = dset.ImageFolder(root=opt.dataroot,
transform=transforms.Compose([
transforms.Scale(opt.imageSize),
transforms.CenterCrop(opt.imageSize),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]))
elif opt.dataset == 'lsun':
dataset = dset.LSUN(db_path=opt.dataroot, classes=['bedroom_train'],
transform=transforms.Compose([
transforms.Scale(opt.imageSize),
transforms.CenterCrop(opt.imageSize),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]))
elif opt.dataset == 'cifar10':
dataset = dset.CIFAR10(root=opt.dataroot, download=True,
transform=transforms.Compose([
transforms.Scale(opt.imageSize),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
)
assert dataset
dataloader = torch.utils.data.DataLoader(dataset, batch_size=opt.batchSize,
shuffle=True, num_workers=int(opt.workers)) ngpu = int(opt.ngpu)
nz = int(opt.nz)
ngf = int(opt.ngf)
ndf = int(opt.ndf)
nc = int(opt.nc)
n_extra_layers = int(opt.n_extra_layers) # custom weights initialization called on netG and netD
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
m.weight.data.normal_(0.0, 0.02)
elif classname.find('BatchNorm') != -1:
m.weight.data.normal_(1.0, 0.02)
m.bias.data.fill_(0) if opt.noBN:
netG = dcgan.DCGAN_G_nobn(opt.imageSize, nz, nc, ngf, ngpu, n_extra_layers)
elif opt.mlp_G:
netG = mlp.MLP_G(opt.imageSize, nz, nc, ngf, ngpu)
else:
netG = dcgan.DCGAN_G(opt.imageSize, nz, nc, ngf, ngpu, n_extra_layers) netG.apply(weights_init)
if opt.netG != '': # load checkpoint if needed
netG.load_state_dict(torch.load(opt.netG))
print(netG) if opt.mlp_D:
netD = mlp.MLP_D(opt.imageSize, nz, nc, ndf, ngpu)
else:
netD = dcgan.DCGAN_D(opt.imageSize, nz, nc, ndf, ngpu, n_extra_layers)
netD.apply(weights_init) if opt.netD != '':
netD.load_state_dict(torch.load(opt.netD))
print(netD) input = torch.FloatTensor(opt.batchSize, 3, opt.imageSize, opt.imageSize)
noise = torch.FloatTensor(opt.batchSize, nz, 1, 1)
fixed_noise = torch.FloatTensor(opt.batchSize, nz, 1, 1).normal_(0, 1)
one = torch.FloatTensor([1])
mone = one * -1 if opt.cuda:
netD.cuda()
netG.cuda()
input = input.cuda()
one, mone = one.cuda(), mone.cuda()
noise, fixed_noise = noise.cuda(), fixed_noise.cuda() # setup optimizer
if opt.adam:
optimizerD = optim.Adam(netD.parameters(), lr=opt.lrD, betas=(opt.beta1, 0.999))
optimizerG = optim.Adam(netG.parameters(), lr=opt.lrG, betas=(opt.beta1, 0.999))
else:
optimizerD = optim.RMSprop(netD.parameters(), lr = opt.lrD)
optimizerG = optim.RMSprop(netG.parameters(), lr = opt.lrG) gen_iterations = 0
for epoch in range(opt.niter):
data_iter = iter(dataloader)
i = 0
while i < len(dataloader):
############################
# (1) Update D network
###########################
for p in netD.parameters(): # reset requires_grad
p.requires_grad = True # they are set to False below in netG update # train the discriminator Diters times
if gen_iterations < 25 or gen_iterations % 500 == 0:
Diters = 100
else:
Diters = opt.Diters
j = 0
while j < Diters and i < len(dataloader):
j += 1 # clamp parameters to a cube
for p in netD.parameters():
p.data.clamp_(opt.clamp_lower, opt.clamp_upper) data = data_iter.next()
i += 1 # train with real
real_cpu, _ = data
netD.zero_grad()
batch_size = real_cpu.size(0) if opt.cuda:
real_cpu = real_cpu.cuda()
input.resize_as_(real_cpu).copy_(real_cpu)
inputv = Variable(input) errD_real = netD(inputv)
errD_real.backward(one) # train with fake
noise.resize_(opt.batchSize, nz, 1, 1).normal_(0, 1)
noisev = Variable(noise, volatile = True) # totally freeze netG
fake = Variable(netG(noisev).data)
inputv = fake
errD_fake = netD(inputv)
errD_fake.backward(mone)
errD = errD_real - errD_fake
optimizerD.step() ############################
# (2) Update G network
###########################
for p in netD.parameters():
p.requires_grad = False # to avoid computation
netG.zero_grad()
# in case our last batch was the tail batch of the dataloader,
# make sure we feed a full batch of noise
noise.resize_(opt.batchSize, nz, 1, 1).normal_(0, 1)
noisev = Variable(noise)
fake = netG(noisev)
errG = netD(fake)
errG.backward(one)
optimizerG.step()
gen_iterations += 1 print('[%d/%d][%d/%d][%d] Loss_D: %f Loss_G: %f Loss_D_real: %f Loss_D_fake %f'
% (epoch, opt.niter, i, len(dataloader), gen_iterations,
errD.data[0], errG.data[0], errD_real.data[0], errD_fake.data[0]))
if gen_iterations % 500 == 0:
real_cpu = real_cpu.mul(0.5).add(0.5)
vutils.save_image(real_cpu, '{0}/real_samples.png'.format(opt.experiment))
fake = netG(Variable(fixed_noise, volatile=True))
fake.data = fake.data.mul(0.5).add(0.5)
vutils.save_image(fake.data, '{0}/fake_samples_{1}.png'.format(opt.experiment, gen_iterations)) # do checkpointing
torch.save(netG.state_dict(), '{0}/netG_epoch_{1}.pth'.format(opt.experiment, epoch))
torch.save(netD.state_dict(), '{0}/netD_epoch_{1}.pth'.format(opt.experiment, epoch))
main.py
首先利用parser = argparse.ArgumentParser()命令行解析工具设置了一堆参数,如文章最开始处。
然后利用net.apply(weighs_init)递归进行权重初始化:
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
m.weight.data.normal_(0.0, 0.02)
elif classname.find('BatchNorm') != -1:
m.weight.data.normal_(1.0, 0.02)
m.bias.data.fill_(0)
接着选择dcgan结构或者mlp结构,尽量不要在 D 中使用 batch normalization,即不选DCGAN_D_nobn。可选的优化器为Adam和RMSprop。在WGAN中尽量使用RMSProp 或 SGD 。
迭代训练的epoch为25,注意参数 Diters默认为5,是指每迭代generator 1 次,迭代descriminator 5 次。为什么迭代判别器多于生成器呢?因为如果判别器太弱,那么生成器的质量就会受到影响导致生成的图片质量太低。在代码中我们看可以看到:
if gen_iterations < 25 or gen_iterations % 500 == 0:
Diters = 100
else:
Diters = opt.Diters
gen_iterations(生成器迭代次数)在epoch循环外被初始化为0,也即是说当在第一个epoch中,将判别器迭代100次,将生成器迭代1次。然后当gen_iteration>=25时,即生成器迭代了25次以上时,生成器每迭代一次,判别器迭代默认的5次。此外还有一些细节例如:
one = torch.FloatTensor([1])
mone = one * -1
...
errD_real.backward(one)
...
errD_fake.backward(mone)
...
errG.backward(one)
为啥反向传播参数有的为1,有的为-1?先看WGAN的损失函数:
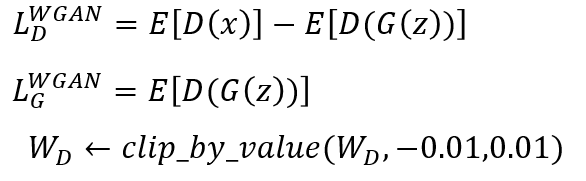

即对于判别器:maxmize LD
对于生成器:maxmize LG
最大化判LD可以看做最大化E(D(x)), 最小化E(D(G(z)))。所以第一项求梯度后系数为1,即梯度上升求最大值,而第二项最小化得利用梯度下降法,所以反向传播时得加个负号变为负梯度。
最大化LG可以看做最大化E(D(G(z)))。即利用梯度上升法,所以反向传播时系数为1,即梯度方向就是最速上升方向。
附:DCGAN、WGAN实现。
WGAN源码解读的更多相关文章
- SDWebImage源码解读之SDWebImageDownloaderOperation
第七篇 前言 本篇文章主要讲解下载操作的相关知识,SDWebImageDownloaderOperation的主要任务是把一张图片从服务器下载到内存中.下载数据并不难,如何对下载这一系列的任务进行设计 ...
- SDWebImage源码解读 之 NSData+ImageContentType
第一篇 前言 从今天开始,我将开启一段源码解读的旅途了.在这里先暂时不透露具体解读的源码到底是哪些?因为也可能随着解读的进行会更改计划.但能够肯定的是,这一系列之中肯定会有Swift版本的代码. 说说 ...
- SDWebImage源码解读 之 UIImage+GIF
第二篇 前言 本篇是和GIF相关的一个UIImage的分类.主要提供了三个方法: + (UIImage *)sd_animatedGIFNamed:(NSString *)name ----- 根据名 ...
- SDWebImage源码解读 之 SDWebImageCompat
第三篇 前言 本篇主要解读SDWebImage的配置文件.正如compat的定义,该配置文件主要是兼容Apple的其他设备.也许我们真实的开发平台只有一个,但考虑各个平台的兼容性,对于框架有着很重要的 ...
- SDWebImage源码解读_之SDWebImageDecoder
第四篇 前言 首先,我们要弄明白一个问题? 为什么要对UIImage进行解码呢?难道不能直接使用吗? 其实不解码也是可以使用的,假如说我们通过imageNamed:来加载image,系统默认会在主线程 ...
- SDWebImage源码解读之SDWebImageCache(上)
第五篇 前言 本篇主要讲解图片缓存类的知识,虽然只涉及了图片方面的缓存的设计,但思想同样适用于别的方面的设计.在架构上来说,缓存算是存储设计的一部分.我们把各种不同的存储内容按照功能进行切割后,图片缓 ...
- SDWebImage源码解读之SDWebImageCache(下)
第六篇 前言 我们在SDWebImageCache(上)中了解了这个缓存类大概的功能是什么?那么接下来就要看看这些功能是如何实现的? 再次强调,不管是图片的缓存还是其他各种不同形式的缓存,在原理上都极 ...
- AFNetworking 3.0 源码解读 总结(干货)(下)
承接上一篇AFNetworking 3.0 源码解读 总结(干货)(上) 21.网络服务类型NSURLRequestNetworkServiceType 示例代码: typedef NS_ENUM(N ...
- AFNetworking 3.0 源码解读 总结(干货)(上)
养成记笔记的习惯,对于一个软件工程师来说,我觉得很重要.记得在知乎上看到过一个问题,说是人类最大的缺点是什么?我个人觉得记忆算是一个缺点.它就像时间一样,会自己消散. 前言 终于写完了 AFNetwo ...
随机推荐
- Leetcode 190.颠倒二进制位 By Python
颠倒给定的 32 位无符号整数的二进制位. 示例: 输入: 43261596 输出: 964176192 解释: 43261596 的二进制表示形式为 000000101001010000011110 ...
- 自学Zabbix9.2 zabbix网络发现规则配置详解+实战
点击返回:自学Zabbix之路 点击返回:自学Zabbix4.0之路 点击返回:自学zabbix集锦 自学Zabbix9.2 zabbix网络发现规则配置详解+实战 1. 创建网络发现规则 Conf ...
- Android 屏幕操作
1 全屏显示Activity 代码 : 方法一:编程实现 getWindow().setFlags(WindowManager.LayoutParams.FLAG_FULLSCREEN, Window ...
- py3+requests+re+urllib,爬取并下载不得姐视频
实现原理及思路请参考我的另外几篇爬虫实践博客 py3+urllib+bs4+反爬,20+行代码教你爬取豆瓣妹子图:http://www.cnblogs.com/UncleYong/p/6892688. ...
- P1186 玛丽卡 删边最短路最大值
反正蛮水的一道题. 胡雨菲一句话让我的代码减少了10行还A了,之前的是个错的. 思路:先求出最短路,然后依次删去最短路上的每一条边,跑最短路求最大值. 关于删边:我的想法是当作链表删除,把last的n ...
- 一起使用mock数据动态创建表格
在ant-design中,我们创建一个基础table会怎么实现呢? 如下代码可视,我们会自己创建一些数据,在表格中渲染出来,如下 <Card title="基础表格"> ...
- mac idea merge后需要手动push到远程服务器
- elasticsearch 动态模板设置
自定义动态映射 如果你想在运行时增加新的字段,你可能会启用动态映射.然而,有时候,动态映射 规则 可能不太智能.幸运的是,我们可以通过设置去自定义这些规则,以便更好的适用于你的数据. 日期检测 当 E ...
- 函数和常用模块【day04】:内置函数(十)
一.36-40 36.isinstance(object, classinfo) 功能:用于判断,对象是否是某个类的实例 # s = "alex" # 对象,"alex& ...
- SQL记录-Oracle重命名表名例子
rename table_1 to table_2