L1 与 L2 正则化
参考这篇文章:
https://baijiahao.baidu.com/s?id=1621054167310242353&wfr=spider&for=pc
https://blog.csdn.net/jinping_shi/article/details/52433975
参考这篇文章:
https://baijiahao.baidu.com/s?id=1621054167310242353&wfr=spider&for=pc
https://blog.csdn.net/jinping_shi/article/details/52433975
参考这篇文章:
https://baijiahao.baidu.com/s?id=1621054167310242353&wfr=spider&for=pc
https://blog.csdn.net/jinping_shi/article/details/52433975
参考这篇文章:
https://baijiahao.baidu.com/s?id=1621054167310242353&wfr=spider&for=pc
https://blog.csdn.net/jinping_shi/article/details/52433975
参考这篇文章:
https://baijiahao.baidu.com/s?id=1621054167310242353&wfr=spider&for=pc
https://blog.csdn.net/jinping_shi/article/details/52433975
1. L2 正则化直观解释
L2 正则化公式非常简单,直接在原来的损失函数基础上加上权重参数的平方和:
L=Ein+λ∑jw2j
L=Ein+λ∑jwj2
其中,Ein 是未包含正则化项的训练样本误差,λ 是正则化参数,可调。但是正则化项是如何推导的?接下来,我将详细介绍其中的物理意义。
我们知道,正则化的目的是限制参数过多或者过大,避免模型更加复杂。例如,使用多项式模型,如果使用 10 阶多项式,模型可能过于复杂,容易发生过拟合。所以,为了防止过拟合,我们可以将其高阶部分的权重 w 限制为 0,这样,就相当于从高阶的形式转换为低阶。
为了达到这一目的,最直观的方法就是限制 w 的个数,但是这类条件属于 NP-hard 问题,求解非常困难。所以,一般的做法是寻找更宽松的限定条件:
∑jw2j≤C
∑jwj2≤C
上式是对 w 的平方和做数值上界限定,即所有w 的平方和不超过参数 C。这时候,我们的目标就转换为:最小化训练样本误差 Ein,但是要遵循 w 平方和小于 C 的条件。
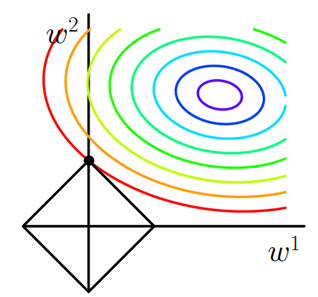
下面,我用一张图来说明如何在限定条件下,对 Ein 进行最小化的优化。
如上图所示,蓝色椭圆区域是最小化 Ein 区域,红色圆圈是 w 的限定条件区域。在没有限定条件的情况下,一般使用梯度下降算法,在蓝色椭圆区域内会一直沿着 w 梯度的反方向前进,直到找到全局最优值 wlin。例如空间中有一点 w(图中紫色点),此时 w 会沿着 -∇Ein 的方向移动,如图中蓝色箭头所示。但是,由于存在限定条件,w 不能离开红色圆形区域,最多只能位于圆上边缘位置,沿着切线方向。w 的方向如图中红色箭头所示。
那么问题来了,存在限定条件,w 最终会在什么位置取得最优解呢?也就是说在满足限定条件的基础上,尽量让 Ein 最小。
我们来看,w 是沿着圆的切线方向运动,如上图绿色箭头所示。运动方向与 w 的方向(红色箭头方向)垂直。运动过程中,根据向量知识,只要 -∇Ein 与运行方向有夹角,不垂直,则表明 -∇Ein 仍会在 w 切线方向上产生分量,那么 w 就会继续运动,寻找下一步最优解。只有当 -∇Ein 与 w 的切线方向垂直时,-∇Ein在 w 的切线方向才没有分量,这时候 w 才会停止更新,到达最接近 wlin 的位置,且同时满足限定条件。
-∇Ein 与 w 的切线方向垂直,即 -∇Ein 与 w 的方向平行。如上图所示,蓝色箭头和红色箭头互相平行。这样,根据平行关系得到:
−∇Ein+λw=0
−∇Ein+λw=0
移项,得:
∇Ein+λw=0
∇Ein+λw=0
这样,我们就把优化目标和限定条件整合在一个式子中了。也就是说只要在优化 Ein 的过程中满足上式,就能实现正则化目标。
接下来,重点来了!根据最优化算法的思想:梯度为 0 的时候,函数取得最优值。已知 ∇Ein 是 Ein 的梯度,观察上式,λw 是否也能看成是某个表达式的梯度呢?
当然可以!λw 可以看成是 1/2λw*w 的梯度:
∂∂w(12λw2)=λw
∂∂w(12λw2)=λw
这样,我们根据平行关系求得的公式,构造一个新的损失函数:
Eaug=Ein+λ2w2
Eaug=Ein+λ2w2
之所以这样定义,是因为对 Eaug 求导,正好得到上面所求的平行关系式。上式中等式右边第二项就是 L2 正则化项。
这样, 我们从图像化的角度,分析了 L2 正则化的物理意义,解释了带 L2 正则化项的损失函数是如何推导而来的。
2. L1 正则化直观解释
L1 正则化公式也很简单,直接在原来的损失函数基础上加上权重参数的绝对值:
L=Ein+λ∑j|wj|
L=Ein+λ∑j|wj|
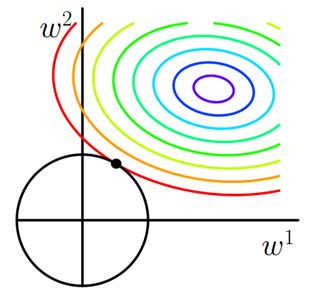
我仍然用一张图来说明如何在 L1 正则化下,对 Ein 进行最小化的优化。
Ein 优化算法不变,L1 正则化限定了 w 的有效区域是一个正方形,且满足 |w| < C。空间中的点 w 沿着 -∇Ein 的方向移动。但是,w 不能离开红色正方形区域,最多只能位于正方形边缘位置。其推导过程与 L2 类似,此处不再赘述。
3. L1 与 L2 解的稀疏性
介绍完 L1 和 L2 正则化的物理解释和数学推导之后,我们再来看看它们解的分布性。
以二维情况讨论,上图左边是 L2 正则化,右边是 L1 正则化。从另一个方面来看,满足正则化条件,实际上是求解蓝色区域与黄色区域的交点,即同时满足限定条件和 Ein 最小化。对于 L2 来说,限定区域是圆,这样,得到的解 w1 或 w2 为 0 的概率很小,很大概率是非零的。
对于 L1 来说,限定区域是正方形,方形与蓝色区域相交的交点是顶点的概率很大,这从视觉和常识上来看是很容易理解的。也就是说,方形的凸点会更接近 Ein 最优解对应的 wlin 位置,而凸点处必有 w1 或 w2 为 0。这样,得到的解 w1 或 w2 为零的概率就很大了。所以,L1 正则化的解具有稀疏性。
扩展到高维,同样的道理,L2 的限定区域是平滑的,与中心点等距;而 L1 的限定区域是包含凸点的,尖锐的。这些凸点更接近 Ein 的最优解位置,而在这些凸点上,很多 wj 为 0。
关于 L1 更容易得到稀疏解的原因,有一个很棒的解释,请见下面的链接:
https://www.zhihu.com/question/37096933/answer/70507353
4. 正则化参数 λ
正则化是结构风险最小化的一种策略实现,能够有效降低过拟合。损失函数实际上包含了两个方面:一个是训练样本误差。一个是正则化项。其中,参数 λ 起到了权衡的作用。
以 L2 为例,若 λ 很小,对应上文中的 C 值就很大。这时候,圆形区域很大,能够让 w 更接近 Ein 最优解的位置。若 λ 近似为 0,相当于圆形区域覆盖了最优解位置,这时候,正则化失效,容易造成过拟合。相反,若 λ 很大,对应上文中的 C 值就很小。这时候,圆形区域很小,w 离 Ein 最优解的位置较远。w 被限制在一个很小的区域内变化,w 普遍较小且接近 0,起到了正则化的效果。但是,λ 过大容易造成欠拟合。欠拟合和过拟合是两种对立的状态。
梯度角度分析
1)、L1正则化
L1正则化的损失函数为:
上式可知,当w大于0时,更新的参数w变小;当w小于0时,更新的参数w变大;所以,L1正则化容易使参数变为0,即特征稀疏化。
2)、L2正则化
L2正则化的损失函数为:
由上式可知,正则化的更新参数相比于未含正则项的更新参数多了
项,当w趋向于0时,参数减小的非常缓慢,因此L2正则化使参数减小到很小的范围,但不为0。
L1 与 L2 正则化的更多相关文章
- 4.机器学习——统计学习三要素与最大似然估计、最大后验概率估计及L1、L2正则化
1.前言 之前我一直对于“最大似然估计”犯迷糊,今天在看了陶轻松.忆臻.nebulaf91等人的博客以及李航老师的<统计学习方法>后,豁然开朗,于是在此记下一些心得体会. “最大似然估计” ...
- 深入理解L1、L2正则化
过节福利,我们来深入理解下L1与L2正则化. 1 正则化的概念 正则化(Regularization) 是机器学习中对原始损失函数引入额外信息,以便防止过拟合和提高模型泛化性能的一类方法的统称.也就是 ...
- Spark2.0机器学习系列之12: 线性回归及L1、L2正则化区别与稀疏解
概述 线性回归拟合一个因变量与一个自变量之间的线性关系y=f(x). Spark中实现了: (1)普通最小二乘法 (2)岭回归(L2正规化) (3)La ...
- day-17 L1和L2正则化的tensorflow示例
机器学习中几乎都可以看到损失函数后面会添加一个额外项,常用的额外项一般有两种,一般英文称作ℓ1-norm和ℓ2-norm,中文称作L1正则化和L2正则化,或者L1范数和L2范数.L2范数也被称为权重衰 ...
- 机器学习中的L1、L2正则化
目录 1. 什么是正则化?正则化有什么作用? 1.1 什么是正则化? 1.2 正则化有什么作用? 2. L1,L2正则化? 2.1 L1.L2范数 2.2 监督学习中的L1.L2正则化 3. L1.L ...
- L1与L2正则化的对比及多角度阐述为什么正则化可以解决过拟合问题
正则化是一种回归的形式,它将系数估计(coefficient estimate)朝零的方向进行约束.调整或缩小.也就是说,正则化可以在学习过程中降低模型复杂度和不稳定程度,从而避免过拟合的危险. 一. ...
- L1与L2正则化
目录 过拟合 结构风险最小化原理 正则化 L2正则化 L1正则化 L1与L2正则化 参考链接 过拟合 机器学习中,如果参数过多.模型过于复杂,容易造成过拟合. 结构风险最小化原理 在经验风险最小化(训 ...
- L1、L2正则化详解
正则化是一种回归的形式,它将系数估计(coefficient estimate)朝零的方向进行约束.调整或缩小.也就是说,正则化可以在学习过程中降低模型复杂度和不稳定程度,从而避免过拟合的危险. 一. ...
- tensorflow 中的L1和L2正则化
import tensorflow as tf weights = tf.constant([[1.0, -2.0],[-3.0 , 4.0]]) >>> sess.run(tf.c ...
随机推荐
- ActiveMQ集群
1.ActiveMQ集群介绍 1.为什么要集群? 实现高可用,以排除单点故障引起的服务中断 实现负载均衡,以提升效率为更多客户提供服务 2.集群方式 客户端集群:让多个消费者消费同一个队列 Broke ...
- maven阿里云镜像
<mirrors> <mirror> <id>nexus-aliyun</id> <mirrorOf>central</mirrorO ...
- python学习笔记:"爬虫+有道词典"实现一个简单的英译汉程序
1.有道的翻译 网页:www.youdao.com Fig1 Fig2 Fig3 Fig4 再次点击"自动翻译"->选中'Network'->选中'第一项',如下: F ...
- string替换字符串,路径的斜杠替换为下划线
场景 替换某个路径的所有"\"为"_". 很多时候取证需要把恶意代码文件取回来,然后清除. 如果在D:\WEB\模板制作插件\需要覆盖\CodeColoring ...
- 故障 -> nginx启动失败
描述:在用saltstack给 minion 安装 nginx 服务 时 提示 nginx 服务下载成功,但是启动失败. ---------- ID: nginx-systemctl Function ...
- mysql报错问题解决MySQL server PID file could not be found!
MySQL server PID file could not be found! 无法启动mysql服务 # service mysqld start MySQL server PID file c ...
- 使用 HTTP/2 提升性能的几个建议
历史悠久的超文本传输协议,即HTTP标准,最近版本升级了.HTTP/2在2015年5月被批准,目前已经在很多Web浏览器和服务器中得到实现(包括NGINX Plus和开源NGINX).大约有三分之二的 ...
- IntelliJ IDEA创建JavaWeb工程及配置Tomcat部署
步骤: 在WEB-INF 下创建classes 和 lib 两个文件夹 右上角一个蓝色的按钮... Modules选项卡,Paths下的配置...输出路径选择classes Dependencies选 ...
- poj3585 树形dp 二次扫描,换根法模板题
#include<iostream> #include<cstring> #include<cstdio> #include<vector> using ...
- oracle分区表彻底删除的办法,处理删不掉的不规则表名
Oracle分区表彻底删除的办法当对一个不再使用的分区表进行drop后,查询user_tab_partitions视图发现出现如下不规则的分区表表名:SQL> select distinct t ...