Express工作原理和源码分析一:创建路由
Express是一基于Node的一个框架,用来快速创建Web服务的一个工具,为什么要使用Express呢,因为创建Web服务如果从Node开始有很多繁琐的工作要做,而Express为你解放了很多工作,从而让你更加关注于逻辑业务开发。举个例子:
创建一个很简单的网站:
1. 使用Node来开发:
var http = require('http');
var url = require("url");
http.createServer(function(req, res) {
res.writeHead(200, {
'Content-Type': 'text/plain'
});
var url_str = url.parse(req.url,true);
res.end('Hello World\n' + url_str.query);
}).listen(8080, "127.0.0.1");
console.log('Server running at http://127.0.0.1:8080/');
这是一个简单的 hello world,运行以后访问http://127.0.0.1会打印相关字符串,这是最普通的页面,但实际上真正的网站要比这个复杂很多,主要有:
(1) 多个页面的路由功能
(2) 对请求的逻辑处理
那么使用node原生写法就要进行以下处理
// 加载所需模块
var http = require("http"); // 创建Server
var app = http.createServer(function(request, response) {
if(request.url == '/'){
response.writeHead(200, { "Content-Type": "text/plain" });
response.end("Home Page!\n");
} else if(request.url == '/about'){
response.writeHead(200, { "Content-Type": "text/plain" });
response.end("About Page!\n");
} else{
response.writeHead(404, { "Content-Type": "text/plain" });
response.end("404 Not Found!\n");
}
}); // 启动Server
app.listen(1984, "localhost");
代码里在createServer函数里传递一个回调函数用来处理http请求并返回结果,在这个函数里有两个工作要做:
(1)路由分析,对于不同的路径需要进行分别处理
(2)逻辑处理和返回,对某个路径进行特别的逻辑处理
在这里会有什么问题?如果一个大型网站拥有海量的网站(也就是路径),每个网页的处理逻辑也是交错复杂,那这里的写法会非常混乱,没法维护,为了解决这个问题,TJ提出了Connect的概念,把Java里面的中间件概念第一次进入到JS的世界,Web请求将一个一个经过中间件,并通过其中一个中间件返回,大大提高了代码的可维护性和开发效率。
// 引入connect模块
var connect = require("connect");
var http = require("http"); // 建立app
var app = connect(); // 添加中间件
app.use(function(request, response) {
response.writeHead(200, { "Content-Type": "text/plain" });
response.end("Hello world!\n");
});
// 启动应用 http.createServer(app).listen(1337);
但是TJ认为还应该更好一点,于是Express诞生了,通过Express开发以上的例子:
2. 使用Express来开发:
var express = require('express');
var app = express();
app.get('/', function (req, res) {
res.send('Hello World!');
});
app.get('/about', function (req, res) {
res.send('About');
});
var server = app.listen(3000, function () { var host = server.address().address; var port = server.address().port; console.log('Example app listening at http://%s:%s', host, port); });
从Express例子可以看出,使用Express大大减少了代码函数,而且逻辑更为简洁,所以使用Express可以提高开发效率并降低工程维护成本。
首先Express有几个比较重要的概念:路由,中间件和模版引擎
开发人员可以为Web页面注册路由,将不同的路径请求区分到不同的模块中去,从而避免了上面例子1所说的海量路径问题,例如
var express = require("express");
var http = require("http");
var app = express();
app.all("*", function(request, response, next) {
response.writeHead(404, { "Content-Type": "text/plain" });
next();
});
app.get("/", function(request, response) {
response.end("Welcome to the homepage!");
});
app.get("/about", function(request, response) {
response.end("Welcome to the about page!");
});
app.get("*", function(request, response) {
response.end("404!");
});
http.createServer(app).listen(1337);
开发人员可以为特定的路由开发中间件模块,中间件模块可以复用,从而解决了复杂逻辑的交错引用问题,例如
var express = require('express');
var app = express();
// 没有挂载路径的中间件,应用的每个请求都会执行该中间件
app.use(function (req, res, next) {
console.log('Time:', Date.now());
next();
});
// 挂载至 /user/:id 的中间件,任何指向 /user/:id 的请求都会执行它
app.use('/user/:id', function (req, res, next) {
console.log('Request Type:', req.method);
next();
});
// 路由和句柄函数(中间件系统),处理指向 /user/:id 的 GET 请求
app.get('/user/:id', function (req, res, next) {
res.send('USER');
});
var server = app.listen(3000, function () {
var host = server.address().address;
var port = server.address().port;
console.log('Example app listening at http://%s:%s', host, port);
});
同时Express对Request和Response对象进行了增强,添加了很多工具函数。
其中路由和中间件还有很多细节问题,可以参考http://www.expressjs.com.cn/来学习
下面我们来看看Express的工作原理
我们首先来看看Express的源码结构:
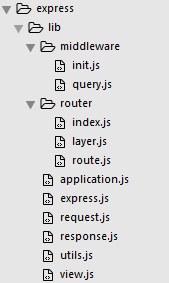
简单介绍下:
Middleware:中间件
init.js 初始化request,response
query.js 格式化url,将url中的rquest参数剥离, 储存到req.query中
Router:路由相关
index.js: Router类,用于存储中间件数组
layer.js 中间件实体类
route.js route类,用于处理不同Method
Application.js 对外API
Express.js 入口
Request.js 请求增强
Response.js 返回增强
Utils.js 工具函数
View.js 模版相关
现在看不明白没关系,可以先看看后面的解释然后再回头看就明白了:
我们前面有说道路由和中间件,那么我们就需要有地方来保存这些信息,比如路由信息,比如中间件回调函数等等,express中有一个对象Router对象专门用来存储中间件对象,他有一个数组叫stack,保存了所有的中间件对象,而中间件对象是Layer对象。
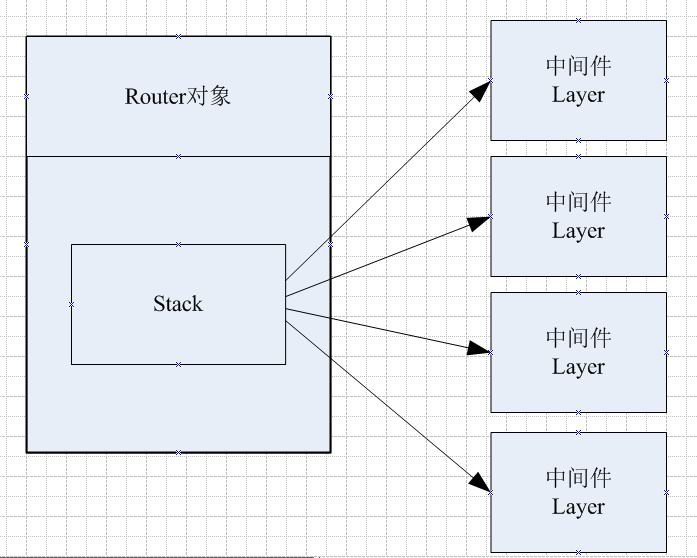
Router对象就是router/index.js文件,他的代码是:

Router对象的主要作用就是存储中间件数组,对请求进行处理等等。
Layer对象在router/layer.js文件中,是保存中间件函数信息的对象,主要属性有:

源码见:
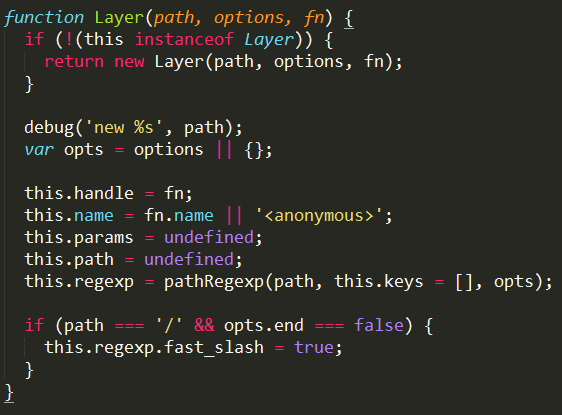
这里面的细节先不多考虑,只需要了解关键的信息path,handler和route
handler是保存中间件回调函数的地方,path是路由的url,route是一个指针,指向undefined或者一个route对象,为何会有两种情况呢,是因为中间件有两种类型:
(1)普通中间件:普通中间件就是不管是什么请求,只要路径匹配就执行回调函数
(2)路由中间件:路由中间件就是区分了HTTP请求的类型,比如get/post/put/head 等等(有几十种)类型的中间件,就是说还有区分请求类型才执行。
所以有两种Layer,一种是普通中间件,保存了name,回调函数已经undefined的route变量。
另外一种是路由中间件,除了保存name,回调函数,route还会创建一个route对象:
route对象在router/route.js文件中,
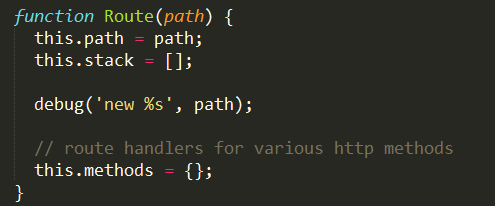
我们看到route对象有path变量,一个methods对象,也有一个stack数组,stack数组其实保存的也是Layer对象,这个Layer对象保存的是对于不同HTTP方法的不同中间件函数(handler变量)。
也许你会问,这个route的数组里面的Layer和上面router的数组里面的Layer有何不同,他们有一些相同之处也有一些不同之处,主要是因为他们的作用不同:
相同之处:他们都是保存中间件的实例对象,当请求匹配到指定的中间件时,该对象实例将会触发。
不同之处:
Router对象的Layer对象有route变量,如果为undefined表示为普通中间件,如果指向一个route对象表示为路由中间件,没有method对象。而route对象的Layer实例是没有route变量的,有method对象,保存了HTTP请求类型。
所以Router对象中的Layer对象是保存普通中间件的实例或者路由中间件的路由,而route对象中的Layer是保存路由中间件的真正实例。
我们来看个例子,加入有段设置路由器的代码:
app.use("/index.html",function(){ //此处省略一万行代码});
app.use("/contract.html",function(){ //此处省略一万行代码});
app.get("/index.html",function(){ //此处省略一万行代码});
app.post("/index.html",function(){ //此处省略一万行代码});
app.get("/home.html",function(){ //此处省略一万行代码});
代码中注册了2个普通中间件about.html和contract.html,两个路由中间件,index.html和home.html,对index.html有get和post两种中间件函数,对home.html只有get中间件函数,在内存中存储的形式就是:
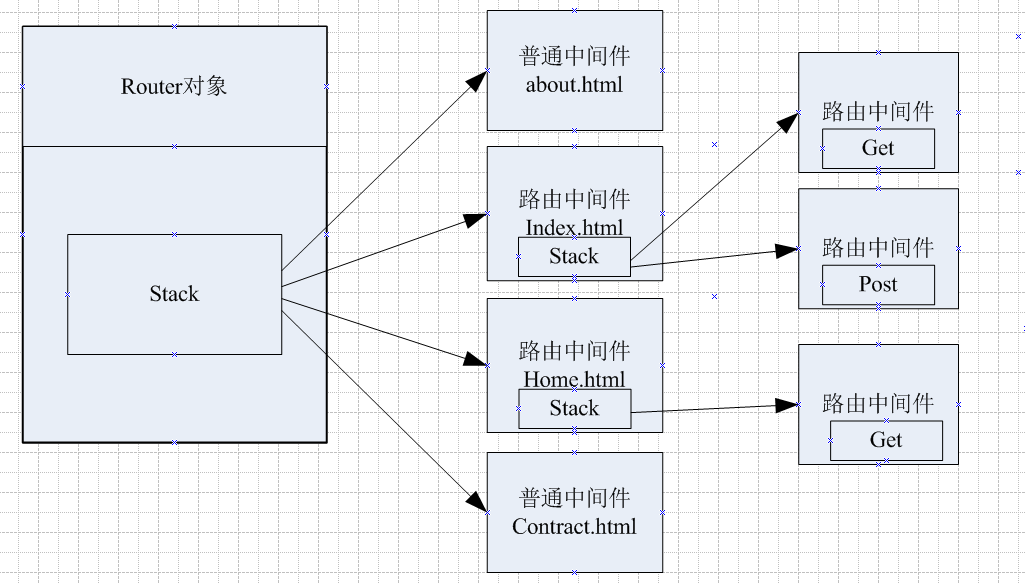
我们上面看到了几种注册中间件的方式,下面就来介绍下路由器的几个动作逻辑:
route对象:
router.METHOD(path,callback);//METHOD是HTTP请求方法(get/post等),他的实现过程在这里:

methods变量是一个数组包含了几十个http请求类型,这段代码给route对象添加了几十个方法,主要逻辑就是创建一个Layer对象,保存中间件函数对象和Method方法,添加到route的stack数组中去。
我们再来看看Router对象的方法:
proto.use = function use(fn) {
var offset = 0;
var path = '/';
// default path to '/'
// disambiguate router.use([fn])
if (typeof fn !== 'function') {
var arg = fn;
while (Array.isArray(arg) && arg.length !== 0) {
arg = arg[0];
}
// first arg is the path
if (typeof arg !== 'function') {
offset = 1;
path = fn;
}
}
var callbacks = flatten(slice.call(arguments, offset));
if (callbacks.length === 0) {
throw new TypeError('Router.use() requires middleware functions');
}
for (var i = 0; i < callbacks.length; i++) {
var fn = callbacks[i];
if (typeof fn !== 'function') {
throw new TypeError('Router.use() requires middleware function but got a ' + gettype(fn));
}
// add the middleware
debug('use %s %s', path, fn.name || '<anonymous>');
var layer = new Layer(path, {
sensitive: this.caseSensitive,
strict: false,
end: false
}, fn);
layer.route = undefined;
this.stack.push(layer);
}
return this;
};
这个就是app.use的实现方法,实际上app.use就是调用了router.use,后面详细介绍,先看看这个方法做了什么,当我们调用app.use(function(){XXX});的时候,这里的函数首先判断了参数类型,看看有没有path传递进来,没有path就是"/"有的话保存到path变量,然后对后面的所有中间件函数进行了以下处理:
创建了一个layer对象,保存了路径,中间件函数并且设置了route变量为undefined,最后把这个变量保存到router的stack数组中去,到此一个普通中间件函数创建完成,为何要设置route变量为undefined,因为app.use创建的中间件肯定是普通中间件,app.METHOD创建的才是路由中间件。
当我面调用app.get("",function(){XXX})的时候调用的其实是router对象的route方法:
proto.route = function route(path) {
var route = new Route(path);
var layer = new Layer(path, {
sensitive: this.caseSensitive,
strict: this.strict,
end: true
}, route.dispatch.bind(route));
layer.route = route;
this.stack.push(layer);
return route;
};
route方法也创建了一个layer对象,但是因为本身是路由中间件,所以还会创建一个route对象,并且保存到layer的route变量中去。
现在我们总结一下:
1. route对象的主要作用是创建一个路由中间件,并且创建多个方法的layer保存到自己的stack数组中去。
2. router对象的主要作用是创建一个普通中间件或者路由中间件的引导着(这个引导着Layer对象链接到一个route对象),然后将其保存到自己的stack数组中去。
所以route对象的stack数组保存的是中间件的方法的信息(get,post等等)而router对象的stack数组保存的是路径的信息(path)
好了,说完了这些基础组件,下面说一下真正暴露给开发者的对外接口,很显然刚才说的都是内部实现细节,我们开发者通常不需要了解这些细节,只需要使用application提供的对外接口。

application在application.js文件下,主要保存了一些配置信息和配置方法,然后是一些对外操作接口,也就是我们说的app.use,app.get/post等等,有几个重要的方法:
app.use = function use(fn) {
var offset = 0;
var path = '/';
// default path to '/'
// disambiguate app.use([fn])
if (typeof fn !== 'function') {
var arg = fn;
while (Array.isArray(arg) && arg.length !== 0) {
arg = arg[0];
}
// first arg is the path
if (typeof arg !== 'function') {
offset = 1;
path = fn;
}
}
var fns = flatten(slice.call(arguments, offset));
if (fns.length === 0) {
throw new TypeError('app.use() requires middleware functions');
}
// setup router
this.lazyrouter();
var router = this._router;
fns.forEach(function (fn) {
// non-express app
if (!fn || !fn.handle || !fn.set) {
return router.use(path, fn);
}
debug('.use app under %s', path);
fn.mountpath = path;
fn.parent = this;
// restore .app property on req and res
router.use(path, function mounted_app(req, res, next) {
var orig = req.app;
fn.handle(req, res, function (err) {
req.__proto__ = orig.request;
res.__proto__ = orig.response;
next(err);
});
});
// mounted an app
fn.emit('mount', this);
}, this);
return this;
};
我们看到app.use在进行了一系列的参数处理后,最终调用的是router的use方法创建一个普通中间件。
methods.forEach(function(method){
app[method] = function(path){
if (method === 'get' && arguments.length === 1) {
// app.get(setting)
return this.set(path);
}
this.lazyrouter();
var route = this._router.route(path);
route[method].apply(route, slice.call(arguments, 1));
return this;
};
});
同route一样,将所有的http请求的方法创建成函数添加到application对象中去,从而可以使用app.get/post/等等,最终的效果是调用router的route方法创建一个路由中间件。
所有的方法再通过express入口文件暴露在对外接口中去。而middleware中的两个文件是对application做的一些初始化操作,request.js和response.js是对请求的两个对象的一些增强。
到此我们基本了解了express的创建路由和中间件函数的基本原理,下一篇我们来了解如何调用这些路由和中间件函数。
Express工作原理和源码分析一:创建路由的更多相关文章
- Kubernetes Job Controller 原理和源码分析(一)
概述什么是 JobJob 入门示例Job 的 specPod Template并发问题其他属性 概述 Job 是主要的 Kubernetes 原生 Workload 资源之一,是在 Kubernete ...
- Kubernetes Job Controller 原理和源码分析(二)
概述程序入口Job controller 的创建Controller 对象NewController()podControlEventHandlerJob AddFunc DeleteFuncJob ...
- Kubernetes Job Controller 原理和源码分析(三)
概述Job controller 的启动processNextWorkItem()核心调谐逻辑入口 - syncJob()Pod 数量管理 - manageJob()小结 概述 源码版本:kubern ...
- Java并发编程(七)ConcurrentLinkedQueue的实现原理和源码分析
相关文章 Java并发编程(一)线程定义.状态和属性 Java并发编程(二)同步 Java并发编程(三)volatile域 Java并发编程(四)Java内存模型 Java并发编程(五)Concurr ...
- ☕【Java深层系列】「并发编程系列」让我们一起探索一下CyclicBarrier的技术原理和源码分析
CyclicBarrier和CountDownLatch CyclicBarrier和CountDownLatch 都位于java.util.concurrent这个包下,其工作原理的核心要点: Cy ...
- 深入ReentrantLock的实现原理和源码分析
ReentrantLock是Java并发包中提供的一个可重入的互斥锁.ReentrantLock和synchronized在基本用法,行为语义上都是类似的,同样都具有可重入性.只不过相比原生的Sync ...
- Java1.7 HashMap 实现原理和源码分析
HashMap 源码分析是面试中常考的一项,下面一篇文章讲得很好,特地转载过来. 本文转自:https://www.cnblogs.com/chengxiao/p/6059914.html 参考博客: ...
- Alibaba-技术专区-RocketMQ 延迟消息实现原理和源码分析
痛点背景 业务场景 假设有这么一个需求,用户下单后如果30分钟未支付,则该订单需要被关闭.你会怎么做? 之前方案 最简单的做法,可以服务端启动个定时器,隔个几秒扫描数据库中待支付的订单,如果(当前时间 ...
- Android AsyncTask运作原理和源码分析
自10年大量看源码后,很少看了,抽时间把最新的源码看看! public abstract class AsyncTask<Params, Progress, Result> { p ...
随机推荐
- 雇佣K个工人的最小费用 Minimum Cost to Hire K Workers
2018-10-06 20:17:30 问题描述: 问题求解: 问题规模是10000,已经基本说明是O(nlogn)复杂度的算法,这个复杂度最常见的就是排序算法了,本题确实是使用排序算法来进行进行求解 ...
- django-simple-captcha 验证码插件介绍 django-simple-captcha 使用 以及添加动态ajax刷新验证
django-simple-captcha作为一款django的验证码插件,使用方法非常简单,能够快速应用到web应用中. 文档官网地址:django-simple-captcha 参考博客:http ...
- mysql5.6以上版本: timestamp current_timestamp报1064/1067错误
mysql5.6以上版本: timestamp current_timestamp报1064/1067错误 在创建时间字段的时候 DEFAULT CURRENT_TIMESTAMP表示当插入数据的时候 ...
- ado.net常用操作
目录 一.ADO.NET概要 二.ADO.NET的组成 三.Connection连接对象 3.1.连接字符串 3.1.1.SQL Server连接字符串 3.1.2.Access连接字符串 3.1.3 ...
- spring boot ----> jpa连接和操作mysql数据库
环境: centos6.8,jdk1.8.0_172,maven3.5.4,vim,spring boot 1.5.13,mysql-5.7.23 1.引入jpa起步依赖和mysql驱动jar包 &l ...
- BGP - 2,BGP报文和BGP状态
1,BGP报文 Open:建邻居,交换version.AS号.holdtime.BGP identifier(即RouterID).可选参数长度.可选参数. Keepalive:保 ...
- spring boot(二)web综合开发
上篇文章介绍了Spring boot初级教程:spring boot(一):入门,方便大家快速入门.了解实践Spring boot特性:本篇文章接着上篇内容继续为大家介绍spring boot的其它特 ...
- input上传限定文件类型
input上传限定文件类型 accept="image/*" 限定为只能上传图片 accept=”audio/* 限定为只能上传音频 accept=”video/*” 限定 ...
- Oracle11g ADG环境实施文档-1204
Oracle11g adg 环境搭建实施手册-1204 2017年8月30日 9:16 11g adg 环境搭建实施手册-0824 2017年8月24日 10:18 ################# ...
- linux过滤旧文件中的空行和注释行剩余内容组成新文件
一.说明 在某些场景下我们想要将旧文件中空行和注释行过滤掉,将产生实际效果的行保留. 比如redis提供的配置示例文件中有很多用于说明的空行和注释行,我们想把产生实际效果的配置行筛选出来组成新的简洁的 ...