redis源码之dict
大家都知道redis默认是16个db,但是这些db底层的设计结构是什么样的呢?
我们来简单的看一下源码,重要的字段都有所注释
typedef struct redisDb {
dict *dict; /* The keyspace for this DB 字典数据结构,非常重要*/
dict *expires; /* Timeout of keys with a timeout set 过期时间*/
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP) list一些数据结构中用到的阻塞api*/
dict *ready_keys; /* Blocked keys that received a PUSH */
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS 事务相关处理 */
int id; /* Database ID */
long long avg_ttl; /* Average TTL, just for stats */
unsigned long expires_cursor; /* Cursor of the active expire cycle. */
list *defrag_later; /* List of key names to attempt to defrag one by one, gradually. */
} redisDb;
redis中的所有kv都是存放在dict中的,dict类型在redis中非常重要。
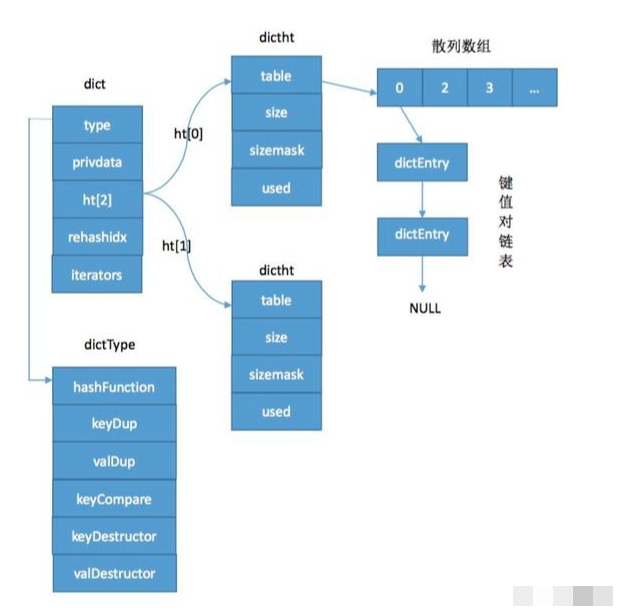
字典disc的数据结构如下
typedef struct dict {
dictType *type; //
void *privdata;
dictht ht[2]; //hashtable,每个dict都有两个这样的数据结构,主要用于hash扩容
long rehashidx; /* rehashing not in progress if rehashidx == -1 rehash的作用 防止链表无限增长*/
unsigned long iterators; /* number of iterators currently running 遍历记录的一些字段*/
} dict;
redis中当出现hash冲突的时候,我们会采用头插法(链表)的方式来解决,但是链表无限增常的话hashtable会退化,退化成一个链表,影响查询效率,这个时候我们就需要对之前的数组进行扩容,把老的数据搬到新数组上面,这个过程就是rehash
接下来咱们来看看dictType的类型
typedef struct dictType {
uint64_t (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key); //key用于数据类型的复制
void *(*valDup)(void *privdata, const void *obj); //value用于数据类型的复制
int (*keyCompare)(void *privdata, const void *key1, const void *key2); //hash冲突的时候需要在冲突的值里面一个一个的对比
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;
typedef struct dictht {
dictEntry **table; //指向数组的首地址 是健值对的核心结构
unsigned long size;//数组的长度
unsigned long sizemask; //恒等于size-1
unsigned long used;
} dictht;
typedef struct {
void *key; //指向SDS的数据结构
union { //联合体表示value类型,只会用到一个字段
void *val; //指向redis对象 redisObject
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next; //头插法解决hash冲突
} dictEntry;
接下来我们看一下内存关系的对应图
typedef struct redisObject {
unsigned type:4; //当前对象类型 list string hash set zset等
unsigned encoding:4; //redis做的底层优化(编码)
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
} robj;
最后咱们有一张总的图来表是redis的内存关系
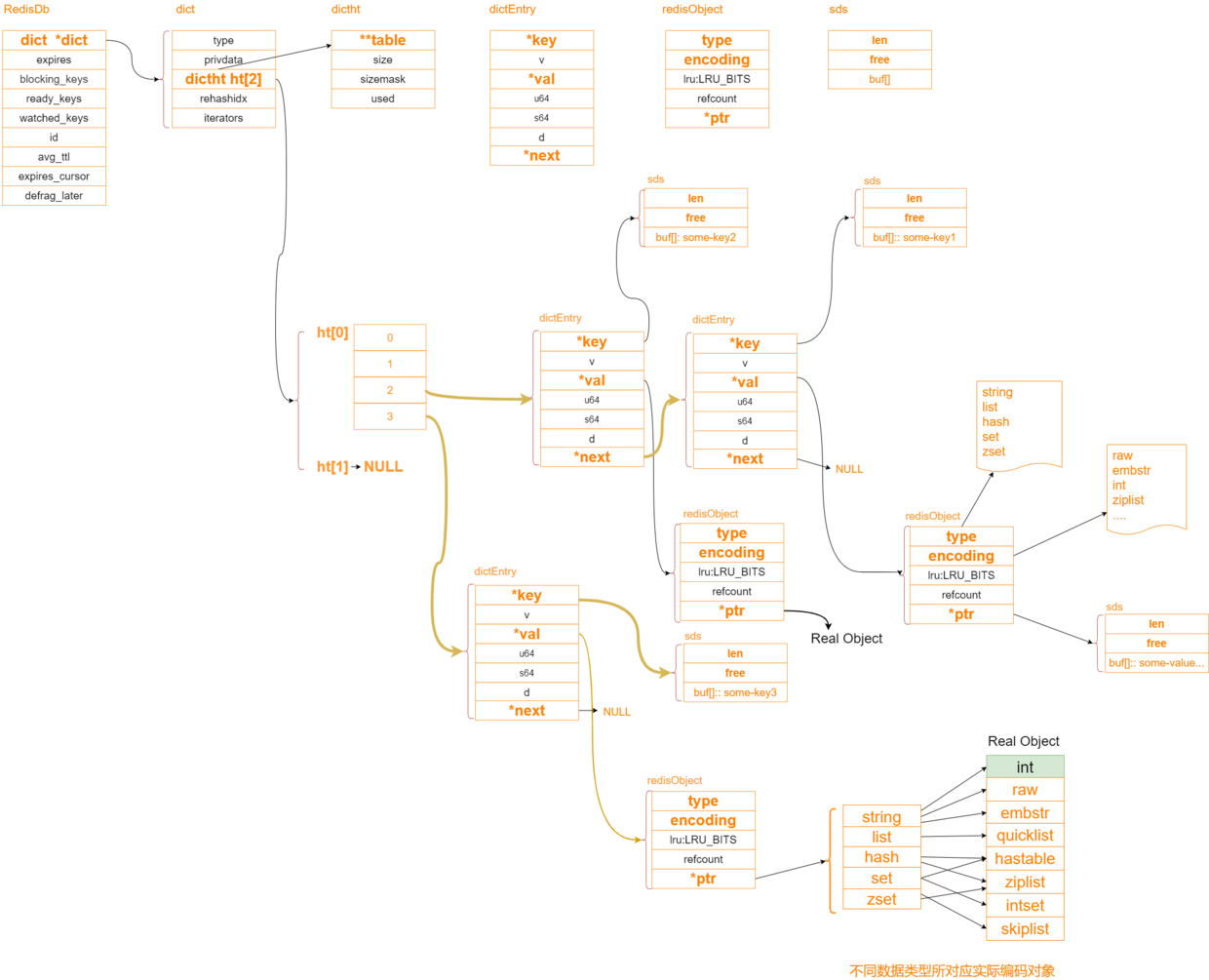
encoding存储的优化策略
1:整型编码的处理
我们先来看一个例子
127.0.0.1:6379> set type-int 12345
OK
127.0.0.1:6379> object encoding type-int
"int"
//返回的encoding类型是int
127.0.0.1:6379> set type-int-long 12345678901234567890
OK
127.0.0.1:6379> object encoding type-int-long
"embstr"
//返回的encoding类型是embstr
我们可以发现,在都是数字的时候,如果长度小于20,就会自动转换为int类型,这是redis中专门做的处理
if (len <= 20 && string2l(s, len, &value))
在一个redisObject中,就可以直接用ptr去存储整型值,而不用重新去开辟一块sds的空间
2:redis对象字符串存储相关优化
127.0.0.1:6379> set type-str-short xxx
OK
127.0.0.1:6379> object encoding type-str-short
"embstr"
127.0.0.1:6379> set type-str-long xxxxxxxxxx-xxxxxxxxxx-xxxxxxxxxx-xxxxxxxxxx-x
//字符串长度45
127.0.0.1:6379> object encoding type-str-long
"raw"
127.0.0.1:6379> set type-str-long2 xxxxxxxxxx-xxxxxxxxxx-xxxxxxxxxx-xxxxxxxxxx-
//字符串长度44
127.0.0.1:6379> object encoding type-str-long2
"embstr"
一个redisobject是存在内存中的,cpu在完成一个io的时候,它是怎么来读数据的呢,其实cup的io中有一个缓冲行的概念,在linux系统中,一个缓冲行一般是64个字节
接下来我们看看一个redis对象大概占多大的内存空间,其实我们可以大概算出来。
typedef struct redisObject {
unsigned type:4; //4bit
unsigned encoding:4; //4bit
unsigned lru:LRU_BITS; //24bit
int refcount; //4byte
void *ptr; //8byte
} robj;
一个redis对象本身就需要占 (4bit+4bit+24bit = 4byte) + 4byte + 8byte = 16byte的大小
这样的话一个缓冲行还剩余48个byte的大小,有点浪费,
48个byte,按照sds的分配策略应该在sdshdr8那个区间中,而sdshdr8本身就需要占3个字节,sds需要兼容c语言的函数库,都会在结尾加上\0,所以sdshdr8本身是占用4个字节,所以一个缓冲行中还剩余44个字节,来存储剩余的数据,所以在redis字符串对象中,当长度小于44的时候,encoding的类型是embstr,没有新开辟一块sds空间
关注我的技术公众号,每周都有优质技术文章推送。
微信扫一扫下方二维码即可关注:

redis源码之dict的更多相关文章
- Redis源码阅读-Dict哈希字典
Dict和Java中的HashMap很相似,都是数组开链法解决冲突. 但是Redis为了高性能, 有很多比较微妙的方法,例如 数组的大小总是2的倍数,初始大小是4. rehash并不是一次就执行完,而 ...
- redis源码学习-dict
1.字典相关的几个结构体 dict由hash table存储key-value, hash table数组每一个元素存放dictEntry链接的链表头结点,dictEntry节点存放key-value ...
- [Redis源码阅读]dict字典的实现
dict的用途 dict是一种用于保存键值对的抽象数据结构,在redis中使用非常广泛,比如数据库.哈希结构的底层. 当执行下面这个命令: > set msg "hello" ...
- Redis源码分析(dict)
源码版本:redis-4.0.1 源码位置: dict.h:dictEntry.dictht.dict等数据结构定义. dict.c:创建.插入.查找等功能实现. 一.dict 简介 dict (di ...
- Redis 源码简洁剖析 03 - Dict Hash 基础
Redis Hash 源码 Redis Hash 数据结构 Redis rehash 原理 为什么要 rehash? Redis dict 数据结构 Redis rehash 过程 什么时候触发 re ...
- Redis源码研究--字典
计划每天花1小时学习Redis 源码.在博客上做个记录. --------6月18日----------- redis的字典dict主要涉及几个数据结构, dictEntry:具体的k-v链表结点 d ...
- Redis源码剖析--源码结构解析
请持续关注我的个人博客:https://zcheng.ren 找工作那会儿,看了黄建宏老师的<Redis设计与实现>,对redis的部分实现有了一个简明的认识.在面试过程中,redis确实 ...
- Redis源码阅读(三)集群-连接初始化
Redis源码阅读(三)集群-连接建立 对于并发请求很高的生产环境,单个Redis满足不了性能要求,通常都会配置Redis集群来提高服务性能.3.0之后的Redis支持了集群模式. Redis官方提供 ...
- 如何阅读 Redis 源码?ZZ
原文链接 在这篇文章中, 我将向大家介绍一种我认为比较合理的 Redis 源码阅读顺序, 希望可以给对 Redis 有兴趣并打算阅读 Redis 源码的朋友带来一点帮助. 第 1 步:阅读数据结构实现 ...
随机推荐
- Spark获取DataFrame中列的方式--col,$,column,apply
Spark获取DataFrame中列的方式--col,$,column,apply 1.官方说明 2.使用时涉及到的的包 3.Demo 原文作者:大葱拌豆腐 原文地址:Spark获取DataFrame ...
- JavaScript中是如何定义私有变量的
前言 JavaScript并不像别的语言,能使用关键字来声明私有变量. 我了解的JavaScript能用来声明私有变量的方式有两种,一种是使用闭包,一种是使用WeakMap. 闭包 闭包的描述有很多种 ...
- Codeforces Round #626 (Div. 2) E. Instant Noodles(二分图,最大公因数)
题意: 给你一个二分图,求左侧端点的所有可能子集中的点相连的右侧端点的权值的和的最大公因数. 题解: 若所有右侧端点均不在同一左侧子集中,则求所有权值的最大公因数即可 . 否则,将在相同左侧子集中的右 ...
- HDU - 3374 String Problem (kmp求循环节+最大最小表示法)
做一个高产的菜鸡 传送门:HDU - 3374 题意:多组输入,给你一个字符串,求它最小和最大表示法出现的位置和次数. 题解:刚刚学会最大最小表示法,amazing.. 次数就是最小循环节循环的次数. ...
- Codeforces Round #648 (Div. 2) E. Maximum Subsequence Value 贪心
题意:E.Maximum Subsequence Value 题意: 给你n 个元素,你挑选k个元素,那么这个 k 集合的值为 ∑2i,其中,若集合内至少有 max(1,k−2)个数二进制下第 i 位 ...
- XML、DTD约束
XML的作用: xml现在主要用于配置文件 文档声明: 如果你使用记事本打开文档,此时如果记事本默认保存数据到硬盘根据的是"GB2312"编码,这个时候如果你在xml文档源码中en ...
- Java中赋值常量的注意事项
写在前面: 从网上学习的赋值规则 摘录自网络,标明出处 byte,short,int,long 比如 int a = 234; 此处的常量234类型默认是int,如果要将大的整数赋值给变量的话 必须 ...
- Codeforces Round #668 (Div. 2) B. Array Cancellation (思维,贪心)
题意:有一个长度为\(n\)并且所有元素和为\(0\)的序列,你可以使\(a_{i}-1\)并且\(a_{j}+1\),如果\(i<j\),那么这步操作就是免费的,否则需要花费一次操作,问最少操 ...
- DNA Sequence POJ - 2778 AC自动机 && 矩阵快速幂
It's well known that DNA Sequence is a sequence only contains A, C, T and G, and it's very useful to ...
- HTTP的传输编码(Transfer-Encoding:chunked) / net::ERR_INVALID_CHUNKED_ENCODING
https://blog.csdn.net/m0_37668842/article/details/89138733 https://www.cnblogs.com/jamesvoid/p/11297 ...