Spark在处理数据的时候,会将数据都加载到内存再做处理吗?
对于Spark的初学者,往往会有一个疑问:Spark(如SparkRDD、SparkSQL)在处理数据的时候,会将数据都加载到内存再做处理吗?
很显然,答案是否定的!
对该问题产生疑问的根源还是对Spark计算模型理解不透彻。
对于Spark RDD,它是一个分布式的弹性数据集,不真正存储数据。如果你没有在代码中调用persist或者cache算子,Spark是不会真正将数据都放到内存里的。
此外,还要考虑persist/cache的缓存级别,以及对什么进行缓存(比如是对整张表生成的DataSet缓存还是列裁剪之后生成的DataSet缓存)(关于Spark RDD的特性解析参考《Spark RDD详解》
既然Spark RDD不存储数据,那么它内部是如何读取数据的呢?其实Spark内部也实现了一套存储系统:BlockManager。为了更深刻的理解Spark RDD数据的处理流程,先抛开BlockManager本身原理,从源码角度阐述RDD内部函数的迭代体系。
我们都知道RDD算子最终会被转化为shuffle map task和result task,这些task通过调用RDD的iterator方法获取对应partition数据,而这个iterator方法又会逐层调用父RDD的iterator方法获取数据(通过重写scala.collection.iterator的hasNext和next方法实现)。主要过程如下:
首先看ShuffleMapTask和ResultTask中runTask方法的源码:
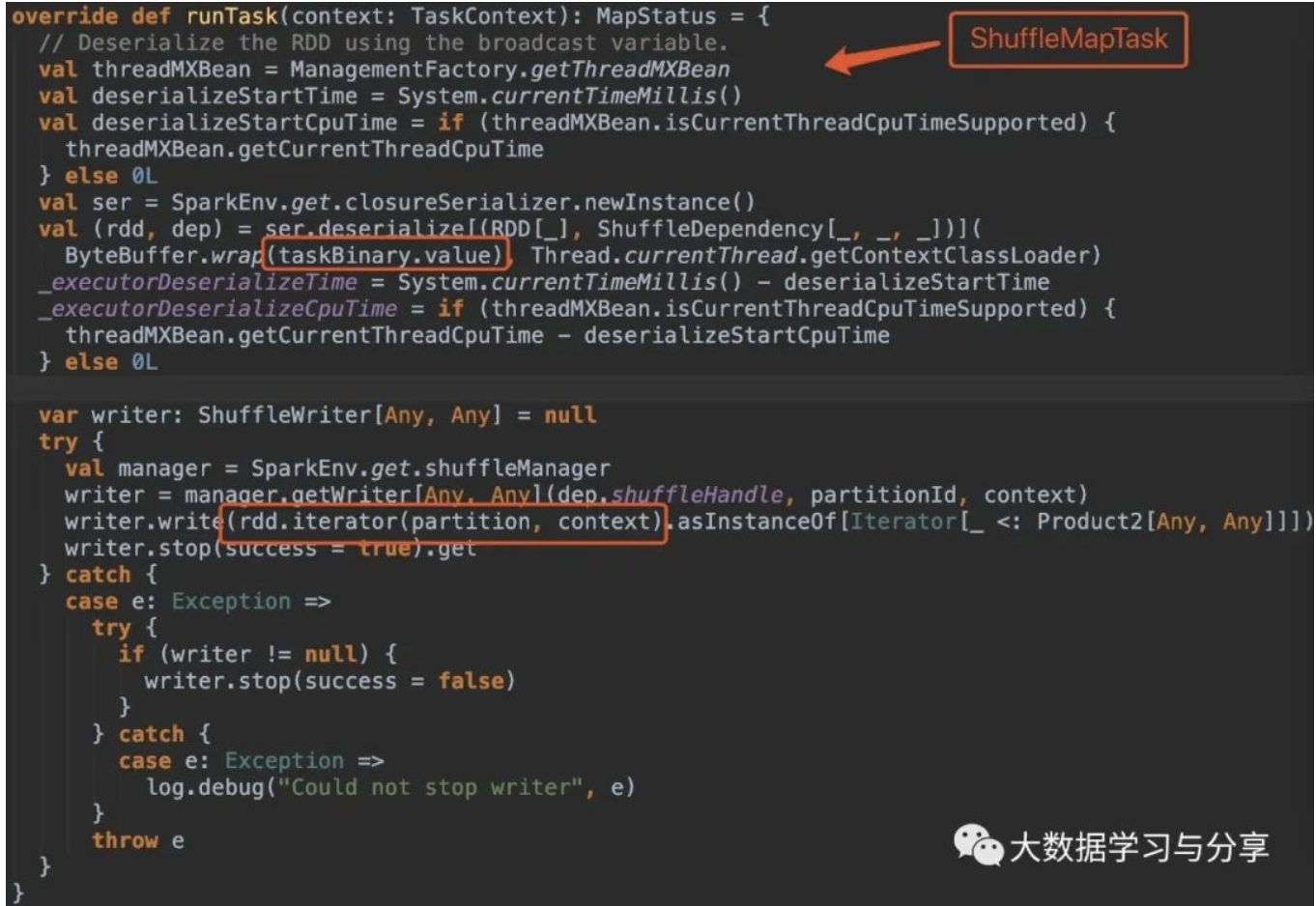
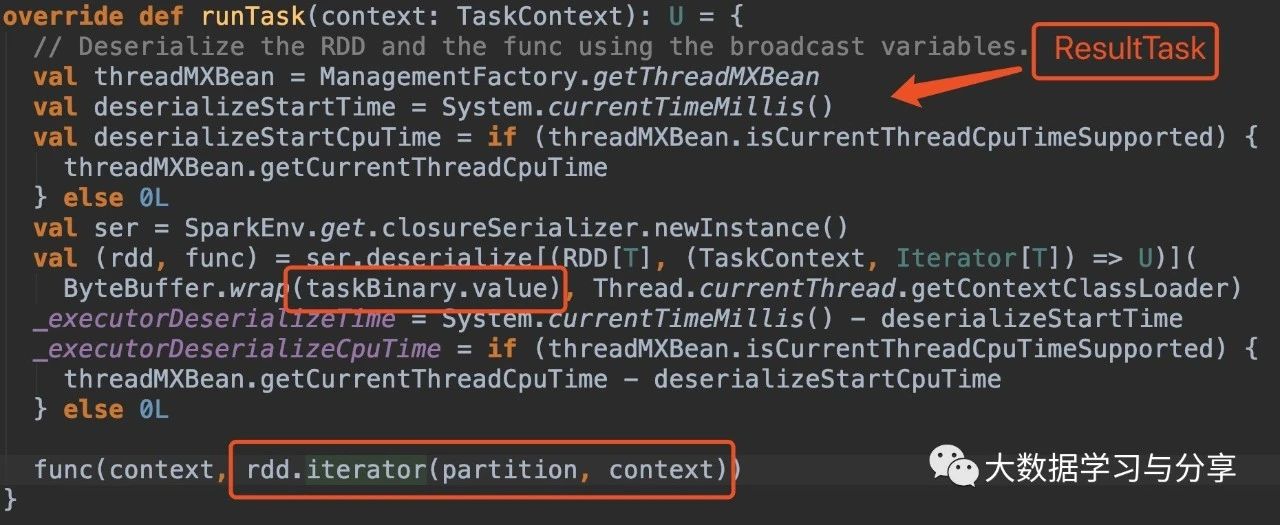
关键看这部分处理逻辑:
rdd.iterator(partition, context)
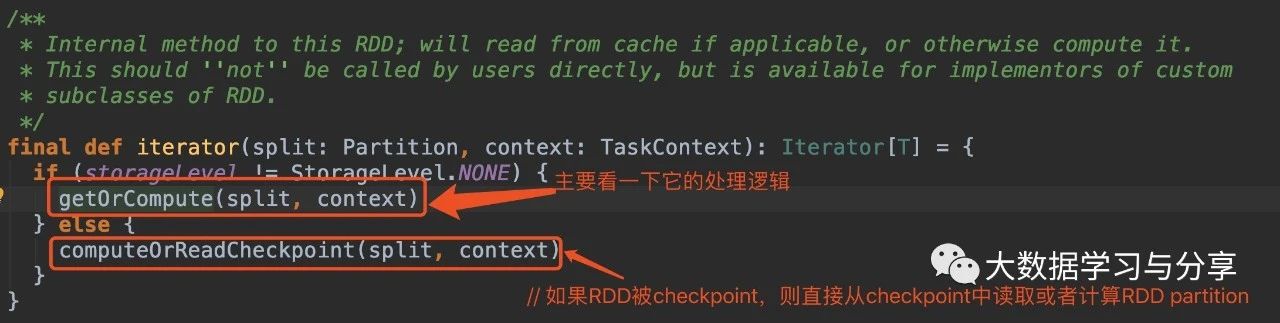
getOrCompute方法会先通过当前executor上的BlockManager获取指定blockId的block,如果block不存在则调用computeOrReadCheckpoint,如果要处理的RDD没有被checkpoint或者materialized,则接着调用compute方法进行计算。
compute方法是RDD的抽象方法,由继承RDD的子类具体实现。
以WordCount为例:
sc.textFile(input)
.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
.saveAsTextFile(output)
textFile会构建一个HadoopRDD
flatMap/map会构建一个MapPartitionsRDD
reduceByKey触发shuffle时会构建一个ShuffledRDD
saveAsTextFile作为action算子会触发整个任务的执行
以flatMap/map产生的MapPartitionsRDD实现的compute方法为例:
override def compute(split: Partition, context: TaskContext): Iterator[U] =
f(context, split.index, firstParent[T].iterator(split, context))
底层调用了parent RDD的iterator方法,然后作为参数传入到了当前的MapPartitionsRDD。而f函数就是对parent RDD的iterator调用了相同的map类函数以执行用户给定的函数。
所以,这是一个逐层嵌套的rdd.iterator方法调用,子RDD调用父RDD的iterator方法并在其结果之上调用Iterator的map函数以执行用户给定的函数,逐层调用直到调用到最初的iterator(比如上述WordCount示例中HadoopRDD partition的iterator)。
而scala.collection.Iterator的map/flatMap方法返回的Iterator就是基于当前Iterator重写了next和hasNext方法的Iterator实例。比如,对于map函数,结果Iterator的hasNext就是直接调用了self iterator的hasNext,next方法就是在self iterator的next方法的结果上调用了指定的map函数。
flatMap和filter函数稍微复杂些,但本质上一样,都是通过调用self iterator的hasNext和next方法对数据进行遍历和处理。
所以,当我们调用最终结果iterator的hasNext和next方法进行遍历时,每遍历一个数据元素都会逐层调用父层iterator的hasNext和next方法。各层的map函数组成一个pipeline,每个数据元素都经过这个pipeline的处理得到最终结果。
这也是Spark的优势之一,map类算子整个形成类似流式处理的pipeline管道,一条数据被该链条上的各个RDD所包裹的函数处理。
再回到WordCount例子。HadoopRDD直接跟数据源关联,内存中存储多少数据跟读取文件的buffer和该RDD的分区数相关(比如buffer*partitionNum,当然这是一个理论值),saveAsTextFile与此类似。MapPartitionsRDD里实际在内存里的数据也跟partition数有关系。ShuffledRDD稍微复杂些,因为牵扯到shuffle,但是RDD本身的特性仍然满足(记录文件的存储位置)。
说完了Spark RDD,再来看另一个问题:Spark SQL对于多表之间join操作,会先把所有表中数据加载到内存再做处理吗?
当然,肯定也不需要!
具体可以查看Spark SQL针对相应的Join SQL的查询计划,以及在之前的文章《Spark SQL如何选择join策略》中,针对目前Spark SQL支持的join方式,任何一种都不要将join语句中涉及的表全部加载到内存。即使是Broadcast Hash Join也只需将满足条件的小表完整加载到内存。
推荐文章:
通过spark.default.parallelism谈Spark谈并行度
Spark为什么只有在调用action时才会触发任务执行呢(附算子优化和使用示例)?
关注微信公众号:大数据学习与分享,获取更对技术干货
Spark在处理数据的时候,会将数据都加载到内存再做处理吗?的更多相关文章
- [WP8.1UI控件编程]Windows Phone大数据量网络图片列表的异步加载和内存优化
11.2.4 大数据量网络图片列表的异步加载和内存优化 虚拟化技术可以让Windows Phone上的大数据量列表不必担心会一次性加载所有的数据,保证了UI的流程性.对于虚拟化的技术,我们不仅仅只是依 ...
- Tomcat启动时加载数据到缓存---web.xml中listener加载顺序(例如顺序:1、初始化spring容器,2、初始化线程池,3、加载业务代码,将数据库中数据加载到内存中)
最近公司要做功能迁移,原来的后台使用的Netty,现在要迁移到在uap上,也就是说所有后台的代码不能通过netty写的加载顺序加载了. 问题就来了,怎样让迁移到tomcat的代码按照原来的加载顺序进行 ...
- js 鼠标滚动到某屏时,加载那一屏的数据,仿京东首页楼层异步加载模式
js用处:在做商城时,首页图片太多,严重影响首页打开速度,所以我们需要用到异步加载楼层.js名称:鼠标滚动到某屏时,加载那一屏的数据,仿京东首页楼层模式js解释:1.用于商城的楼层内容异步加载,滚动条 ...
- Tomcat启动时加载数据到缓存---web.xml中listener加载顺序(优先初始化Spring IOC容器)
JavaWebSpringTomcatCache 最近用到在Tomcat服务器启动时自动加载数据到缓存,这就需要创建一个自定义的缓存监听器并实现ServletContextListener接口,并且 ...
- Highcharts 基本曲线图;Highcharts 带有数据标签曲线图表;Highcharts 异步加载数据曲线图表
Highcharts 基本曲线图 实例 文件名:highcharts_line_basic.htm <html> <head> <meta charset="U ...
- python数据可视化-matplotlib入门(7)-从网络加载数据及数据可视化的小总结
除了从文件加载数据,另一个数据源是互联网,互联网每天产生各种不同的数据,可以用各种各样的方式从互联网加载数据. 一.了解 Web API Web 应用编程接口(API)自动请求网站的特定信息,再对这些 ...
- html ajax请求 php 下拉 加载更多数据 (也可点击按钮加载更多)
<input type="hidden" class="total_num" id="total" value="{$tot ...
- EF如何操作内存中的数据以及加载相关联表的数据:延迟加载、贪婪加载、显示加载
之前的EF Code First系列讲了那么多如何配置实体和数据库表的关系,显然配置只是辅助,使用EF操作数据库才是每天开发中都需要用的,这个系列讲讲如何使用EF操作数据库.老版本的EF主要是通过Ob ...
- EF如何操作内存中的数据和加载外键数据:延迟加载、贪婪加载、显示加载
EF如何操作内存中的数据和加载外键数据:延迟加载.贪婪加载.显示加载 之前的EF Code First系列讲了那么多如何配置实体和数据库表的关系,显然配置只是辅助,使用EF操作数据库才是每天开发中都需 ...
随机推荐
- SLAM01
上周末发现了一个巨大的问题,就是我们目前构建的室内定位的方法中,一个基本的假设是错的----这就非常尴尬了. 于是乎赶紧抱一波佛脚,学习一下slam里相关的问题是怎么解决的,找找灵感. 结果看了个开头 ...
- Go语言学习-import
import我们在写Go代码的时候经常用到import这个命令用来导入包文件,而我们经常看到的方式参考如下:import("fmt")然后我们代码里面可以通过如下的方式调用fmt. ...
- 【xml】Button背景色无法修改
由于新版本的主题问题,导致Android Studio的Button背景无法修改,一直呈现亮紫色. 解决方法:将app/res/values目录下的themes代码加上.Bridge即可 修改前: & ...
- 浅谈Winform控件开发(一):使用GDI+美化基础窗口
写在前面: 本系列随笔将作为我对于winform控件开发的心得总结,方便对一些读者在GDI+.winform等技术方面进行一个入门级的讲解,抛砖引玉. 别问为什么不用WPF,为什么不用QT.问就是懒, ...
- Python爬虫入门教程:豆瓣Top电影爬取
基本开发环境 Python 3.6 Pycharm 相关模块的使用 requests parsel csv 安装Python并添加到环境变量,pip安装需要的相关模块即可. 爬虫基本思路 一. ...
- 2019牛客暑期多校训练营(第七场)H.Pair(数位dp)
题意:给你三个数A,B,C 现在要你找到满足 A and B >C 或者 A 异或 B < C 的对数. 思路:我们可以走对立面 把既满足 A and B <= C 也满足 A 异 ...
- hdu2049 不容易系列之(4)——考新郎(组合,错排)
题意: n 个数中 m 个数错排的情况个数. 思路: 先从 n 个数中选出 m 个,即 $C_n^m$, 再算出 m 个数的错排数,即 ${f_{\left( m \right)}}$. 错排: 当n ...
- Java多线程同步和异步问题
我们首先来说一下多线程: 多线程很形象的例子就是:在一个时刻下,一个班级的学生有人在拖地,有人在擦窗户,有人在擦桌子 按照单线程程序,肯定是先去拖地,再去擦窗户,再去擦桌子.但是在多线程就好像他们在一 ...
- Linunx系统引导过程及MBR/GRUB故障
Linunx系统引导过程 系统初始化进程 init进程 Systemd Systemd单元类型 允许级别所对应的systemd目标 修复MBR扇区故障 解决思路 操作 修复GRUB引导故障 解决思路 ...
- ES-Next @Decorator All In One
ES-Next @Decorator All In One @装饰器 import { logged } from "./logged.mjs"; class C { @logge ...