Fault-Tolerance, Fast and Slow: Exploiting Failure Asynchrony in Distributed Systems
本文(OSDI 18')主要介绍一种新的副本复制协议:SAUCR(场景可感知的更新与故障恢复)。它是一种混合的协议:
在一定场景(正常情况)下:副本复制的数据缓存在内存中。
故障发生时(多个节点挂掉,处于系统无法正常运行的边缘):副本复制的数据缓存同步刷入磁盘。
该协议在保证高性能的同时,保证了很强的持久性和可用性。
Introduction
分布式存储系统通常通过维护多个副本来进行容错,这些协议都是基于Majority Based 复制协议进行的,例如raft,Paxos协议。这些Majority Based 复制协议也是leader-based 实现的。它们运行的时候有如下的特点:
- 这些节点组成的系统都每一时刻都会有一个leader去维护整个系统的运行。客户端发送更新请求到会发送到Leader进行响应处理。Leader收到更新请求,将这些请求打包成一个log,转发给其他的follower。当leader收到多数节点日志写入完成的响应信息后,就会执行更新操作(同时也指示副本节点执行相应的操作),回复客户端的请求。
- 每一个leader都会有一个epoch相关联,且在每一个epoch期间只有一个leader。
- 每一条更新操作的日志消息中都会带有一个log的索引号和epoch信息。
- Leader通过心跳检查follower是否正常。如果在一定的时间内follower长时间没有收到心跳,就会怀疑leder挂掉了,就会重新发一起一次选举,新的leader有epoll号。当选的leader必须满足日志完整性约束,即本节点种拥有系统所有已经commited的日志信息。
motivation
论文将传统的复制协议分成了两种类型:
Disk-durable :Leader将log同步到各个节点后,立即将日志数据持久化到 disk 中,优点是,可用性好,可靠性好,但是由于每次要调用写磁盘函数,数据持久化到磁盘中,数据复制的性能不好;因为一条log的确认需要半数以上的节点做出响应回复,所以当宕机的节点个数超过一半时,整个分布式系统就无法运行了,当节点恢复后,运行的节点个数超过一半后,这个系统就会恢复过来。
Memory-durable :将log保存到内存中,启动后台进程异步的将log持久到磁盘上,优点是,性能好。如下图的对比:
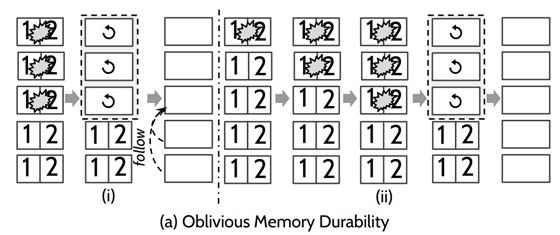
但是该方法可靠性和可用性比较差,存在较大的丢失数据的风险。如下图:五个节点,挂了三个节点的时候,数据都会丢失掉,后期三个节点恢复后,这三个节点会成为一个多数派,会从他们三个之中选出一个leader,这个leader会把正常的两个节点的数据给覆盖掉,造成数据的丢失。
针对Memory-Durability在节点恢复时,丢失数据的节点可能会将正常节点数据给覆盖掉的问题,有人提出了Loss-Aware Memory Durability协议。当节点从故障恢复时,把自己标记为recovering,表示自己不能参与Leader选举(包括成为候选者和投票),向其他正在运行(不在recovering状态)的节点发送一个消息,拉取最新的数据(其它节点不能是recovering),并收到大多数节点的响应(必须包括Leader)。如下图,该协议可以保证正常节点数据不被覆盖。但是这个协议有一个问题就是如果多数节点都挂掉的话,系统会永远无法运行。

这篇论文提出了一个分布式复制协SAUCR议在Disk-durable和Memory-durable之间切换,在保证系统性能的同时,也可以尽量保证数据不被丢失的风险。
SAUCR Overview
论文提出的方法基于一个假设:非同时性猜想,也就说多个副本节点同时宕机的可能性非常非常低。同时,极大部分情况下节点之间的宕机存在一定的时间差。作者从Google集群中过去某一段时间的数据观察到,每次随机取5台机器,观察这些机器宕机间隔,99.9999%的故障事件,它们的时间差超过50ms。
这个协议不像raft协议一样能保证很高的可用性,它也是有可能出现系统不可用的情况。如果多台机器独立的宕机或者相互之间有关联,但多数节点不会同时挂机,以一定时间间隔的挂机的情况,这个协议是可以保证数据正确的,可以实现log的持久化。针对同时发生的宕机的问题,会分为两种情况:
第一种是宕机节点的个数等于半数⌈n/2⌉,是可以保证数据不会丢失。
第二种是宕机的节点个数超过大多数(1/5, 4/6)同时挂掉,不能保证数据的持久性,整个系统都不可用。
SAUCR content
基于leader base的选举协议 和raft协议类似,有选举的过程。运行这个协议的系统有两种模式:Fast mode和Slow mode
Fast Mode 和memorydurablity类似,所有的更新都会被缓存到大部分节点的内存当中,就可以确认这笔交易,更新的log异步的刷到磁盘上。并不会同步的等大多数节点都刷到磁盘之后才去确认。一个请求被commit的条件比原来的raft协议要严格一点,要求leader收到⌈n/2⌉ + 1个节点的确认回复,这笔交易才算成功(4/ 5)。因此,系统要在Fast Mode 下运行,正常运行的节点个数必然要大于等于n/2+1个节点,这样才可以处理用户的请求。
Slow Mode 慢模式和raft协议很类似,节点收到更新请求后,会将log同步的刷到磁盘,leader提交一条数据更新的要求就是收到大多数节点的完成数据持久化操作的响应。(3/5)
SAUCR:Failure Reaction
Follower宕机
Leader会通过发送心跳信号检测follower是否正常,如果丢失了心跳信号,leader就会怀疑follower挂掉了。 如果Leader检测到系统中运行的节点个数只有半数(3/5),整个系统就会马上切换到slow-mode。从慢速模式切换到快速模式(检测到系统中运行的节点个数多余半数(4/5)),需要等待一定的时间,比如多个心跳,才会切换回快速模式。
Leader宕机
Follower通过心跳发现leader挂掉之后(有可能leader并没有挂掉,只是心跳信号来的晚),follower会立即将内存中的数据都落盘。数据落盘的时间和开始选举的时间是没有关联的,follower在一段时间内如果没有收到来自leader的心跳,从follower切换到候选者。而数据刷盘的时间是当Follower没有收到Leader的一两次心跳就会促发落盘机制。
SAUCR:Enabling Safe Mode-Aware Recovery
宕机恢复策略:SAUCR 在不同的 mode 下,恢复的策略和方法是不一样的,那么 crash 重启开始恢复的节点,首先需要知道自己之前处在一个什么 mode 下。
在 fast mode 下,节点在处理第一个操作的时候,会同时持久化一个 fast-switch-entry 到 disk 中,这个 entry 是当前的 (epoch,log-index)。
在Slow mode下,在切换到 slow mode 的时候,会刷 memory buffer 到盘中,同时也会刷 latest-on-disk-entry 到盘中,这个 entry 也是一个 (epoch,log-index)。
如果节点重启,发现 fast-switch-entry 在前面,则说明 crash 的时候,节点处于 fast mode,相反,如果 latest-on-disk-entry 在前面,说明节点 crash 的时候,节点处在 slow mode。
LLE Map是一个保存了目前系统正在运行时,所有节点所处在的epoch时期,以及节对应节点目前最新的log_entry index.(就是正在复制的 log entry index,而不是已经成功复制的 log entry index,这样是为了保证 crash 起来的节点获取到的 LLE 一定是包含已经 commit 的 log 的,这样才不会出现数据丢失。)
节点在选举的时候,会根据这个LLE Map中epoch和log-index来做判断。每次leader向follow发送心跳的时候都会带上这个LLE map信息,在 fast mode 的时候,LLE map 写在内存中,所以节点宕机恢复得时候,就会丢失掉所有得LLE信息,因此论文提出了一种Max-Among-Minority的算法来恢复LLE,将在后文做介绍。而在 slow mode 的时候 LLE Map 写在 disk,只需从磁盘恢复就可以了。
宕机恢复的主要步骤:
1. 从磁盘中恢复 (last logged entry )LLE,实际上就是知道自己到底拥有多少日志
在慢模式下,这个LLE是持久化到磁盘上的,直接可以从磁盘读取数据。
在快模式下,磁盘中读不到最新得log entry,会运行一个Max-Among-Minority 算法获取自己的LLE
2. 等待并参加下一次选举,通过选举来判断哪个节点的LLE是最新的(主节点)。
3. 从主节点去复制数据。
Max-Among-Minority
1. 首先待恢复节点将自己标记状态为recovering,
2. 向其它节点获取自己的LLE
3. 其它节点若是正常运行的节点或者已经恢复的节点,则返回响应,否则忽略请求 (2/5)
4. 待恢复节点要收到⌈n/2⌉−1个节点回复LLE,并选择最大的最大得值作为自己要恢复的LLE。
为什么⌈n/2⌉−1个消息是安全的?
L`表示通过Max-Among-Minority 恢复的LLE值, L表示当掉的时候机器内存中存在的真实的LLE。
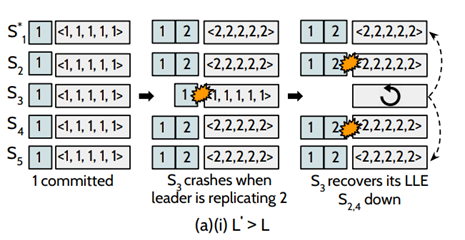
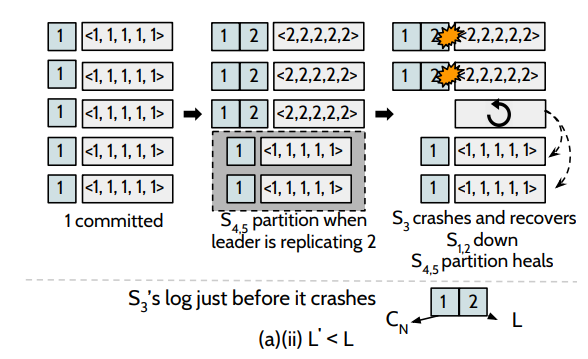
若L`大于L的情况下,如图:初始时刻,系统已经成功提交了第1条日志,此时,leader正打算复制第2条日志到其他节点的时候,S3挂掉了(L = 1),但此时系统中仍然存在四个节点,这个更新操作是可以被提交,在S3恢复的过程中, S2和S4也挂掉了,这个时候,⌈n/2⌉-1 = 2,S3可以收到S1和S5的LLE,去恢复自己的数据,可以保证数据的安全性。
若L`小于L的情况下,假设这个恢复的节点为 N,其 log 是 D, Cn 为 D 最后一条被 committed 的 log entry。 L 为 actual last-logged entry (LLE),L' 为通过 max-among-minority algorithm 恢复的 LLE,如果能证明 L' ≥ Cn,那么就不会出现丢失数据。反证法证明 L' <Cn是不可能产生的:
假设五个节点的情况下,在 fast mode 情况下,由于一个 entry 的提交是需要 bare majority + 1,也就是 4 个副本复制成功,那么必定和 bare mniority,也就是 2 个副本有交集,4+2 > 5,那么意味着要么 Cn 不可能提交,从而与假设矛盾;如图,假设某种情况下存在下图的中间状态,L = 2 D = {1, 2} Cn = {1, 2}? L' = 1。可知Cn必定是错误的。只能是Cn={1}。
SAUCR:Summary
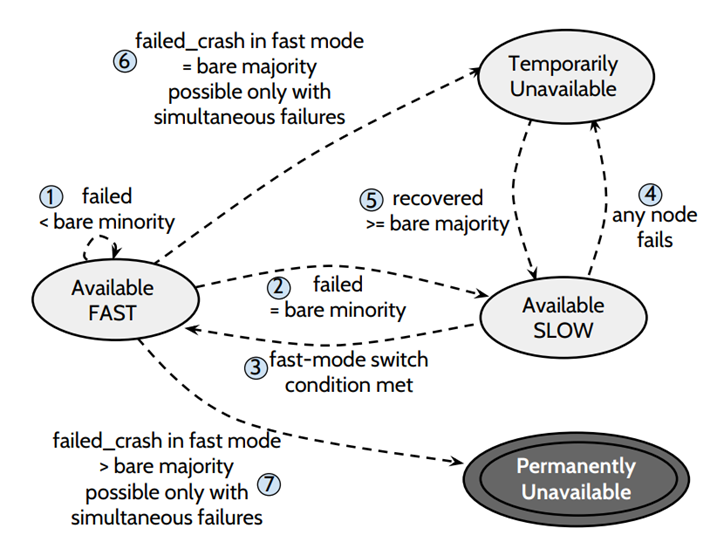
(1)离线节点的个数 < bare minotiry (5个中当掉1个) ,集群处于 fast mode,可用
(2)离线节点个数 = bare minority 节点离线 (5个中宕掉2个),集群处于 slow mode,可用
(3)有节点恢复,又回到 < bare minority 节点离线,集群处于 fast mode,可用
(4)在 slow 状态下,出现任意数量的节点离线,集群都将处于不可用的状态
(5)恢复到 >= bare majority 个节点在线,进去 slow mode,可用
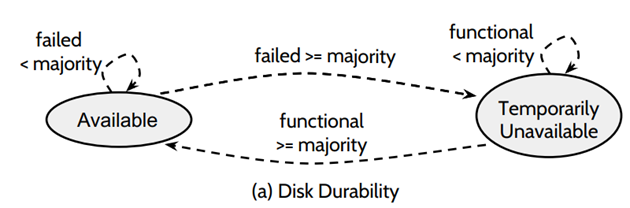
(6)当有 =bare majority 个节点同时离线,将会造成 Temporarily unavailable,为什么是临时的不可用,因为,其他节点加入或者恢复,集群还可以进入可用状态
(7)如果在 fast mode 下,> bare majority 个节点同时离线,那么集群将处于 Permanently unavailable,因为 recovery 至少收到 bare minority 个节点的 response,所以即使通过配置变更加节点或者 crash 节点 recovery 也都不好使了。一般这种时候需要人工介入。
Evaluation
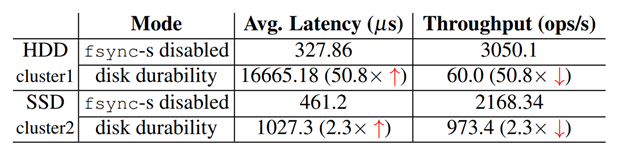
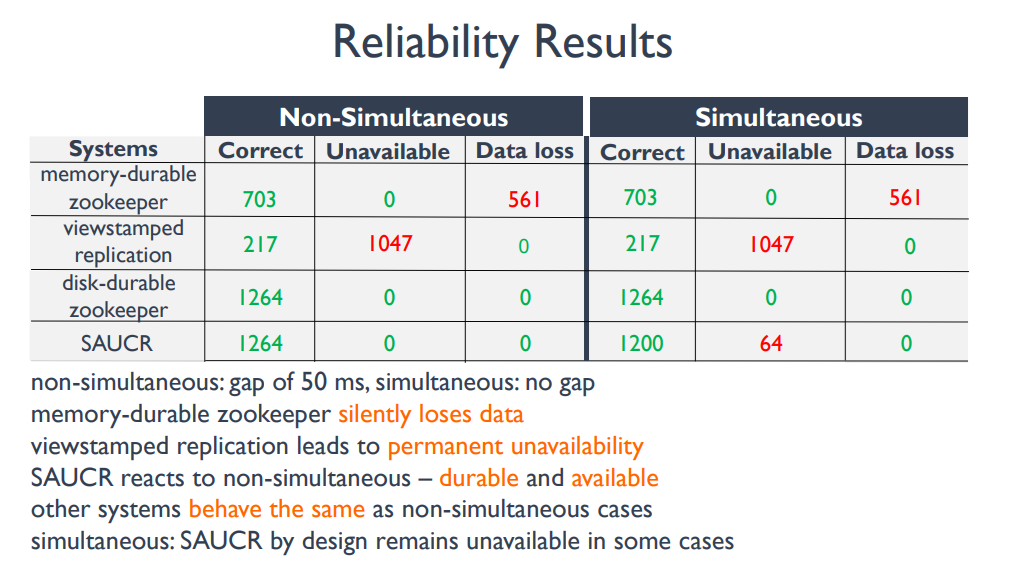
如下图,SAUCR 在非 NSC 的猜想前提下,可用性和可靠性都没有降低;而且即使考虑 SC 的情况,也只是可用性降低了一些,但是数据可靠性并没有降低。
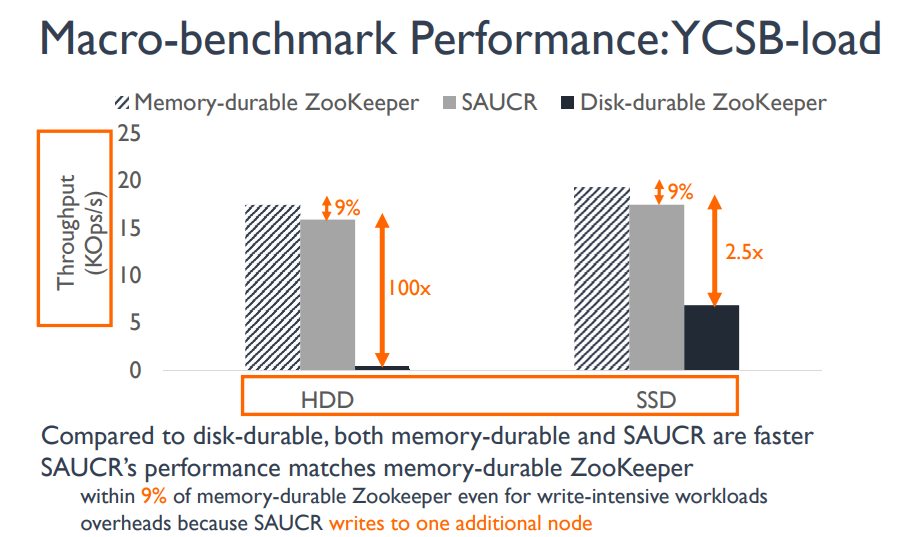
SAUCR还可以保持一个很好的性能(虽然是在快模式下测试的)
Summary

Fault-Tolerance, Fast and Slow: Exploiting Failure Asynchrony in Distributed Systems的更多相关文章
- Flink Program Guide (8) -- Working with State :Fault Tolerance(DataStream API编程指导 -- For Java)
Working with State 本文翻译自Streaming Guide/ Fault Tolerance / Working with State ---------------------- ...
- Flink Program Guide (7) -- 容错 Fault Tolerance(DataStream API编程指导 -- For Java)
false false false false EN-US ZH-CN X-NONE /* Style Definitions */ table.MsoNormalTable {mso-style-n ...
- Fault Tolerance —— Storm的故障容错性
——本文讲解了Storm故障容忍性(Fault-Tolerance)的设计细节:当Worker.节点.Nimbus或者Supervisor出现故障时是如何实现故障容忍性,以及Nimbus是否存在单点 ...
- Flink Program Guide (9) -- StateBackend : Fault Tolerance(Basic API Concepts -- For Java)
State Backends 本文翻译自文档Streaming Guide / Fault Tolerance / StateBackend ----------------------------- ...
- VMware vSphere服务器虚拟化实验十一高可用性之三Fault Tolerance
VMware vSphere服务器虚拟化实验十一高可用性之三Fault Tole ...
- VMware Fault Tolerance 概述及功能
VMware Fault Tolerance - 为您的应用程序提供全天候可用性 通过为虚拟机启用 VMware Fault Tolerance,最大限度地延长数据中心的正常运行时间,减少停机管理成本 ...
- leetcode 141 Linked List Cycle Hash fast and slow pointer
Problem describe:https://leetcode.com/problems/linked-list-cycle/ Given a linked list, determine if ...
- Reinforcement Learning, Fast and Slow
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! 1 DeepMind, London, UK2 University College London, London, UK3 Prince ...
- 跨时钟域设计【二】——Fast to slow clock domain
跨时钟域设计中,对快时钟域的Trigger信号同步到慢时钟域,可以采用上面的电路实现,Verilog HDL设计如下: // Trigger signal sync, Fast clock dom ...
随机推荐
- Redis RDB 分析工具 rdbtools 说明
背景 Redis是基于内存的KV数据库,内存作为存储介质,关注其内存的使用情况是一个重要指标,解析其内部的存储信息是给出优化方法和维护的最基本要求.解析内存有二种方法:第一个是通过scan遍历所有ke ...
- Win10 环境变量
在你的环境变量前面加入下面的目录; 有奇效 %USERPROFILE%\AppData\Local\Microsoft\WindowsApps\
- Python并发编程01 /操作系统发展史、多进程理论
Python并发编程01 /操作系统发展史.多进程理论 目录 Python并发编程01 /操作系统发展史.多进程理论 1. 操作系统 2. 进程理论 1. 操作系统 定义:管理控制协调计算机中硬件与软 ...
- python 面向对象专题(二):类的空间问题、类与对象之间的关系、类与类之间的关系
https://www.cnblogs.com/liubing8/p/11308127.html 目录 Python面向对象02/类的空间问题.类与对象之间的关系.类与类之间的关系 1. 类的空间问题 ...
- 5分钟带你快速入门和了解 OAM Kubernetes
什么是 OAM? OAM 的全称为开放应用模型(Open Application Model),由阿里巴巴宣布联合微软共同推出. OAM 解决了什么问题? OAM 本质是为了解耦K8S中现存的形形色色 ...
- OSCP Learning Notes - Capstone(1)
Kioptrix Level 1.1 Walkthrough Preparation: Download the virtual machine from the following website ...
- P1433 吃奶酪(洛谷)状压dp解法
嗯?这题竟然是个绿题. 这个题真的不(很)难,我们只是不会计算2点之间的距离,他还给出了公式,这个就有点…… 我们直接套公式去求出需要的值,然后普通的状压dp就可以了. 是的状压dp. 这个题的数据加 ...
- [开源硬件DIY] 自制一款精致炫酷的蓝牙土壤温湿度传感器,用于做盆栽呵护类产品(API开放,开发者可自行DIY微信小程序\安卓IOS应用)
目录 前言: 1. 成品展示 2. 原理图解析 3. pcb设计 4. 嵌入式对外提供接口 4.1 蓝牙广播 4.2 蓝牙服务和属性 4.3 数据包格式 4.4 数据通信模型 重要 . 前言: 本期给 ...
- CSS帧动画
CSS帧动画 基础知识 通过定义一段动画中的关键点.关键状态来创建动画.@Keyframes相比transition对动画过程和细节有更强的控制. 过渡动画是两个状态间的变化,帧动画可以处理动画过程中 ...
- Winform开发中的困境及解决方案
在我们开发各种应用的时候,都会碰到很多不同的问题,这些问题涉及架构.模块组合.界面处理.共同部分抽象等方面,我们这里以Winform开发为例,从系统模块化.界面组件选择.业务模块场景划分.界面基类和辅 ...