XJOI NOI训练2 传送
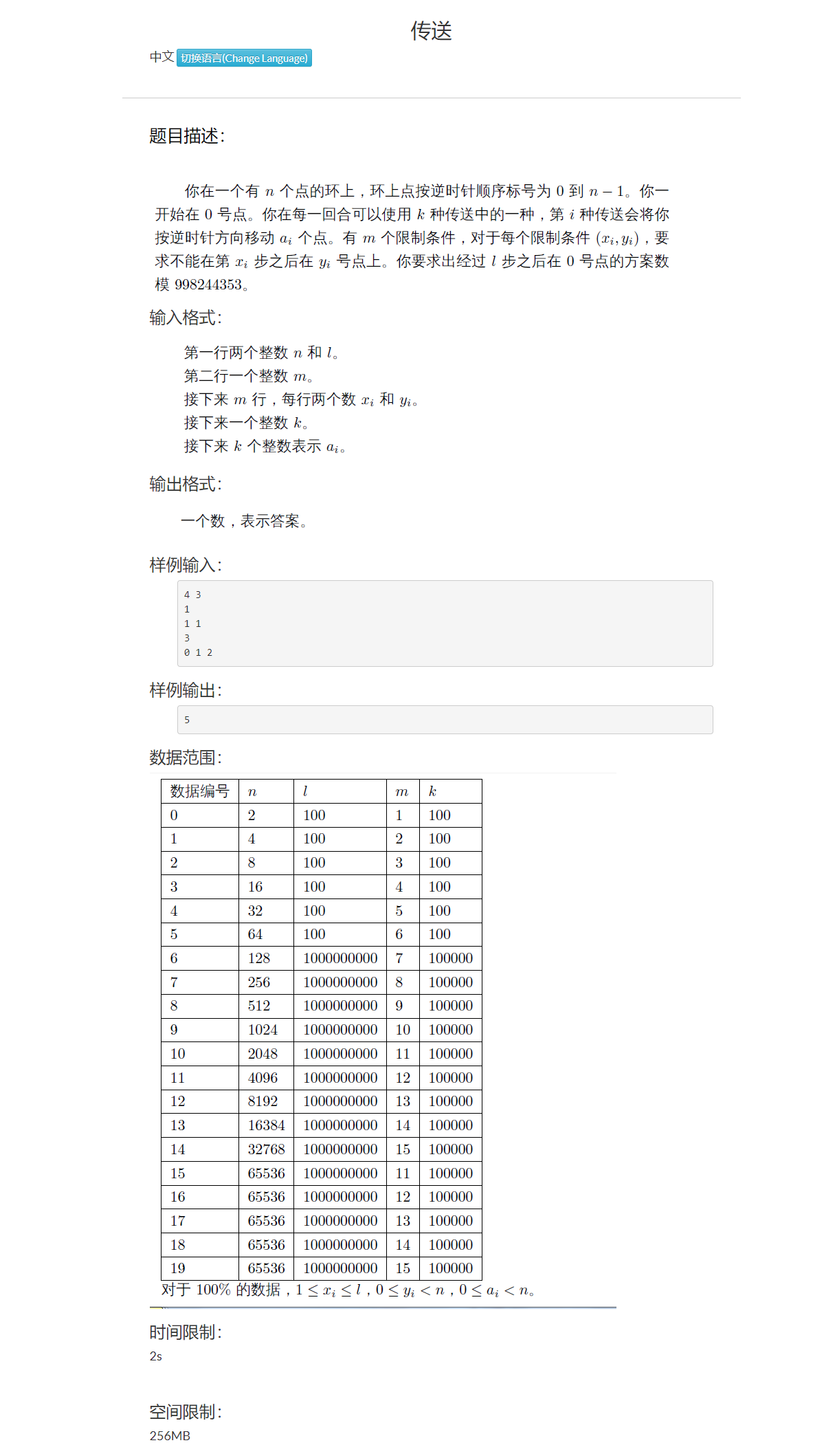
NTT循环卷积
30分:
可以发现这是一个很明显的分层$DP$,设$dp[i][j]$表示当前走了j步走到i号节点的方案数。如果当前走的步数对节点有限制就直接将这个点的$DP$值赋成$0$
#include <bits/stdc++.h>
#define mod 998244353
#define ll long long
using namespace std;
const int N=1e5+100,M=21;
int n,l,m,k,x[M],y[M],a[N];
inline void add(ll &x,ll y){x=(x+y)%mod;}
inline void mul(ll &x,ll y){x=(x*y)%mod;}
inline void del(ll &x,ll y){x=(x-y+mod)%mod;}
namespace subtask1
{
ll dp[210][210];
int vi[210][210];
void solve()
{
dp[0][0]=1;
for (int i=1;i<=m;i++) vi[y[i]][x[i]]=1;
for (int i=0;i<l;i++)
{
for (int j=0;j<n;j++)
{
if (dp[j][i]==0 || vi[j][i]) continue;
for (int p=1;p<=k;p++) add(dp[(j+a[p])%n][i+1],dp[j][i]);
}
}
printf("%lld\n",dp[0][l]);
}
}
int main()
{
scanf("%d%d",&n,&l);
scanf("%d",&m);
for (int i=1;i<=m;i++) scanf("%d%d",&x[i],&y[i]);
scanf("%d",&k);
for (int i=1;i<=k;i++) scanf("%d",&a[i]);
subtask1::solve();
}
45分:
这个$DP$方程很明显可以用矩阵快速幂优化,因为有限制的点只有$m$个,数量很小,那么最两个限制之间用矩阵快速幂加速递推,当遇到一个限制的时候就停下来,将有限制的点在矩阵中的数改成$0$。不断重复这个过程直到递推到$l$
时间复杂度$O(mn^{3}logL)$
然而这个复杂度和暴力在分数上没有区别
for (int i=0;i<n;i++)
{
for (int j=1;j<=k;j++) tr.a[i+1][(i+a[j])%n+1]++;
}
这个转移的矩阵其实是一个循环矩阵,一个向量也可以看作一个循环矩阵,那么初始矩阵可以跟转移矩阵直接循环乘积
循环矩阵相乘只要记录第一行的数字相乘
$m_{x}=\sum_{(i+j-2)\%n+1=x} m_{i}m_{j}$
利用上面的方法计算即可
时间复杂度$O(mn^{2}logL)$
#pragma GCC optimize(2)
#pragma GCC optimize(3)
#include <bits/stdc++.h>
#define mod 998244353
#define ll long long
using namespace std;
const int N=1e5+100,M=21;
int n,l,m,k,a[N];
struct node
{
int x,y;
}sh[M];
struct matrix
{
ll a[600][600],n;
inline void clear(){memset(a,0,sizeof(a));}
inline void init(){for(int i=1;i<=n;i++)a[i][i]=1;}
}tr;
matrix st;
inline int read()
{
int f=1,x=0;char s=getchar();
while(s<'0'||s>'9'){if(s=='-')f=-1;s=getchar();}
while(s>='0'&&s<='9'){x=x*10+s-'0';s=getchar();}
return x*f;
}
inline void add(ll &x,ll y){x=(x+y)%mod;}
inline void mul(ll &x,ll y){x=(x*y)%mod;}
inline void del(ll &x,ll y){x=(x-y+mod)%mod;}
matrix operator *(matrix a,matrix b)
{
matrix ans;
ans.n=a.n;
ans.clear();
for (int i=1;i<=a.n;i++)
{
for (int j=1;j<=a.n;j++)
{
for (int k=1;k<=a.n;k++)
add(ans.a[i][j],(a.a[i][k]*b.a[k][j])%mod);
}
}
return ans;
}
matrix m_pow(matrix a,int b)
{
matrix ans;
ans.n=a.n;
ans.clear();
ans.init();
while (b)
{
if (b&1) ans=ans*a;
b>>=1;
a=a*a;
}
return ans;
}
bool cmp(node a,node b)
{
return a.x<b.x;
}
namespace subtask2
{
void solve()
{
st.n=tr.n=n;
for (int i=0;i<n;i++)
{
for (int j=1;j<=k;j++) tr.a[i+1][(i+a[j])%n+1]++;
}
st.a[1][1]=1;
sort(sh+1,sh+1+m,cmp);
sh[0].x=0;
for (int i=1;i<=m;i++)
{
st=st*m_pow(tr,sh[i].x-sh[i-1].x);
st.a[1][sh[i].y+1]=0;
}
st=st*m_pow(tr,l-sh[m].x);
printf("%lld\n",st.a[1][1]);
}
}
int main()
{
scanf("%d%d",&n,&l);
scanf("%d",&m);
for (int i=1;i<=m;i++) scanf("%d%d",&sh[i].x,&sh[i].y);
scanf("%d",&k);
for (int i=1;i<=k;i++) scanf("%d",&a[i]);
subtask2::solve();
}
65分:
对于循环矩阵的乘积可以发现这是一个循环卷积的形式,直接用$NTT$优化
细节:要将下标减一做$NTT$
时间复杂度$O(nmlognlogL)$
其实到这里离正解只差了一步
jzy就此与$AC$失之交臂
太棒了
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef pair<int,int> pii;
#define mk make_pair
const int N=260;
const int LEN=66000;
const int STEP=505;
const int MOD=998244353;
int ADD(int x,int y){return x+y>=MOD ? x+y-MOD : x+y;}
int MUL(int x,int y){return 1ll*x*y%MOD;}
ll dp[STEP][N],bl[STEP][N];
pii limit[35]; int n,l,m,K,aa[100005];
void init()
{
scanf("%d%d",&n,&l);
scanf("%d",&m);
for(int i=1;i<=m;i++) scanf("%d%d",&limit[i].first,&limit[i].second);
scanf("%d",&K);
for(int i=1;i<=K;i++) scanf("%d",&aa[i]);
} void subtask1()
{
for(int i=1;i<=m;i++)
bl[limit[i].first][limit[i].second]=1;
dp[0][0]=1;
for(int i=1;i<=l;i++)
{
for(int j=0;j<n;j++)
{
for(int t=1;t<=K;t++)
{
int pos=(j+aa[t])%n;
if(bl[i][pos]) continue;
dp[i][pos]=(dp[i][pos]+dp[i-1][j])%MOD;
}
}
}
printf("%lld\n",dp[l][0]);
} int Qpow(int x,int y)
{
int ret=1;
while(y)
{
if(y&1) ret=MUL(ret,x);
x=MUL(x,x);
y>>=1;
}
return ret;
} struct matrix{
int n,a[LEN];
matrix(){
memset(a,0,sizeof(a));
}
matrix(int n):n(n){
memset(a,0,sizeof(a));
}
}; int rev[LEN*2],len,k;
void change(int len,int k)
{
rev[0]=0; rev[len-1]=len-1;
for(int i=1;i<len-1;i++)
{
rev[i]=rev[i>>1]>>1;
if(i&1) rev[i]+=(1<<(k-1));
}
} int Wn[LEN*2],Wn_1[LEN*2];
int inv_len;
void ntt(int a[],int len,int flag)
{
for(int i=0;i<len;i++) if(i<rev[i]) swap(a[i],a[rev[i]]);
for(int h=1;h<len;h<<=1)
{
int wn=Wn[h<<1];
if(flag==-1) wn=Wn_1[h<<1];
int tmp1,tmp2;
for(int i=0;i<len;i+=h*2)
{
int w=1;
for(int j=i;j<i+h;j++)
{
//w=w*wn;
tmp1=a[j],tmp2=1LL*a[j+h]*w%MOD;
a[j]=(tmp1+tmp2)%MOD;
a[j+h]=(tmp1-tmp2+MOD)%MOD;
w=1LL*w*wn%MOD;
}
}
}
if(flag==-1)
{
for(int i=0;i<=len;i++) a[i]=1LL*a[i]*inv_len%MOD;
}
} int a[LEN*2],b[LEN*2];
matrix operator * (matrix A,matrix B)
{
memset(a,0,sizeof(a));
memset(b,0,sizeof(b));
for(int i=0;i<n;i++) a[i]=A.a[i];
for(int i=0;i<n;i++) b[i]=B.a[i];
ntt(a,len,1); ntt(b,len,1);
for(int i=0;i<len;i++) a[i]=MUL(a[i],b[i]);
ntt(a,len,-1);
for(int i=0;i<n;i++) A.a[i]=ADD(a[i],a[i+n]);
return A;
} matrix qpow(matrix A,int y)
{
matrix C(A.n); C.a[0]=1;
while(y)
{
if(y&1) C=C*A;
A=A*A;
y>>=1;
}
return C;
} matrix ans,Base;
int exi_step[LEN];
void build()
{
memset(exi_step,0,sizeof(exi_step));
for(int i=1;i<=K;i++) exi_step[aa[i]]++;
for(int i=0;i<n;i++) Base.a[i]=exi_step[i];
} void subtask2()
{
int now_step=0;
ans.n=n; Base.n=n; ans.a[0]=1;
build();
sort(limit+1,limit+m+1);
matrix tmp(n);
for(int i=1,j;i<=m;i=j+1)
{
j=i;
while(j<m&&limit[j+1].first==limit[i].first) j++;
tmp=qpow(Base,limit[i].first-now_step); now_step=limit[i].first;
ans=ans*tmp;
for(int t=i;t<=j;t++) ans.a[limit[t].second]=0;
}
Base=qpow(Base,l-now_step);
ans=ans*Base;
printf("%d\n",ans.a[0]);
} signed main()
{
init();
k=0,len=1;
while(len<n+n) len<<=1,k++;
change(len,k);
for(int h=1;h<=len;h<<=1)
{
Wn[h]=Qpow(3,(MOD-1)/h);
Wn_1[h]=Qpow(Wn[h],MOD-2);
}
inv_len=Qpow(len,MOD-2);
subtask2();
}
100分:
其实65分的那个做法是在每一次矩阵的乘法中的时候都要做一遍$NTT$
其实并不需要,可以把一个循环矩阵看作一个多项式,其实就是一个多项式的快速幂(循环卷积)
将多项式$DFT$后转为点值表示形式后,直接对每一个点的点值做快速幂,然后$IDFT$还原回去
然后有一个细节,其实$DFT$实现的就是$len$长度的循环卷积,平时使用的$FFT$,$NTT$都是通过补$0$,来用循环卷积实现线性卷积
这道题中保证了$n$是$2$的次幂,直接$DFT$后做快速幂就可以了
$P.S.$对于任意长度循环卷积$CZT$,利用Bluestein’s Algorithm,网址
#pragma GCC optimize(2)
#pragma GCC optimize(3)
#pragma GCC optimize("Ofast")
#pragma GCC optimize("inline")
#include <bits/stdc++.h>
#define mod 998244353
#define ll long long
#define re register int
using namespace std;
const int N=1e5+100,M=21;
int n,l,m,k,a[N],cnt,rev[N];
ll st[N],tr[N];
struct node
{
int x,y;
}sh[M];
inline int read()
{
int f=1,x=0;char s=getchar();
while(s<'0'||s>'9'){if(s=='-')f=-1;s=getchar();}
while(s>='0'&&s<='9'){x=x*10+s-'0';s=getchar();}
return x*f;
}
inline void add(ll &x,ll y){x=(x+y)%mod;}
inline void mul(ll &x,ll y){x=(x*y)%mod;}
inline void del(ll &x,ll y){x=(x-y+mod)%mod;}
inline ll m_pow(ll a,int b)
{
ll ans=1;
while (b)
{
if (b&1) ans=(ans*a)%mod;
b>>=1;
a=(a*a)%mod;
}
return ans;
}
bool cmp(node a,node b)
{
return a.x<b.x;
}
inline void change(int len)
{
for (int i=0;i<len;i++)
{
rev[i]=rev[i>>1]>>1;
if (i&1) rev[i]|=len>>1;
}
}
inline void ntt(ll y[],int len,int v)
{
for (int i=0;i<len;i++) if (i<rev[i]) swap(y[i],y[rev[i]]);
for (int i=2;i<=len;i<<=1)
{
ll step=m_pow(3,(mod-1)/i);
if (v==-1) step=m_pow(step,mod-2);
for (int j=0;j<len;j+=i)
{
ll x=1;
for (int k=j;k<j+i/2;k++)
{
ll a=y[k],b=(x*y[k+i/2])%mod;
y[k]=(a+b)%mod;
y[k+i/2]=(a-b+mod)%mod;
x=(x*step)%mod;
}
}
}
if (v==-1)
{
int invlen=m_pow(len,mod-2);
for (int i=0;i<len;i++) y[i]=(y[i]*invlen)%mod;
}
}
int main()
{
scanf("%d%d",&n,&l);
scanf("%d",&m);
for (re i=1;i<=m;++i) scanf("%d%d",&sh[i].x,&sh[i].y);
scanf("%d",&k);
for (re i=1;i<=k;++i) scanf("%d",&a[i]);
for (re i=1;i<=k;++i) tr[a[i]%n]++;
st[0]=1;
sort(sh+1,sh+1+m,cmp);
sh[0].x=0;
change(n);
ntt(tr,n,1);
for (re i=1;i<=m;++i)
{
ntt(st,n,1);
for (re j=0;j<n;j++) st[j]=(st[j]*m_pow(tr[j],sh[i].x-sh[i-1].x))%mod;
ntt(st,n,-1);
st[sh[i].y]=0;
}
ntt(st,n,1);
for (re i=0;i<n;i++) st[i]=(st[i]*m_pow(tr[i],l-sh[m].x))%mod;
ntt(st,n,-1);
printf("%lld\n",st[0]);
}
XJOI NOI训练2 传送的更多相关文章
- 9.19[XJOI] NOIP训练37
上午[XJOI] NOIP训练37 T1 同余方程 Problem description 已知一个整数a,素数p,求解 $x^{2}\equiv a(mod p) $ 是否有整数解 Solution ...
- [XJOI NOI02015训练题7] B 线线线 【二分】
题目链接:XJOI - NOI2015-07 - B 题目分析 题意:过一个点 P 的所有直线,与点集 Q 的最小距离是多少?一条直线与点集的距离定义为点集中每个点与直线距离的最大值. 题解:二分答案 ...
- 学军NOI训练13 T3 白黑树
唉,大学军有自己的OJ就是好,无限orz 只有周六的比赛是开放的囧,这场比赛最后因为虚拟机卡住没有及时提交…… 否则就能让大家看到我有多弱了…… 前两题题解写的很详细,可以自己去看,我来随便扯扯T3好 ...
- 9.18[XJOI] NOIP训练36
***在休息了周末两天(好吧其实只有半天),又一次投入了学车的怀抱,重新窝在这个熟悉的机房 今日9.18(今天以后决定不写打卡了) 日常一日总结 一个昏昏欲睡的早晨 打了一套不知道是谁出的题目,空间限 ...
- 9.14[XJOI] NOIP训练33
今日9.14 洛谷打卡:大凶!!!(换个字体玩玩qwq) -------------------------------------------------------- 一个超颓的上午 今天又是fl ...
- 9.13[XJOI] NOIP训练32
今日9.13 洛谷打卡:小吉(今天心情不错,决定取消密码) (日常记流水账) 上午 今天听说是鏼鏼的题目,题面非常的清真啊,也没有当初以为的爆零啊 T1 排排坐 非常非常清真的模拟或是结论题,再次将难 ...
- tensorflow中常量(constant)、变量(Variable)、占位符(placeholder)和张量类型转换reshape()
常量 constant tf.constant()函数定义: def constant(value, dtype=None, shape=None, name="Const", v ...
- NOI前训练日记
向别人学习一波,记点流水帐.17.5.29开坑. 5.29 早晨看了道据说是树状数组优化DP的题(hdu5542),然后脑补了一个复杂度500^3的meet in the middle.然后死T... ...
- 【XJOI】【NOI考前模拟赛7】
DP+卡常数+高精度/ 计算几何+二分+判区间交/ 凸包 首先感谢徐老师的慷慨,让蒟蒻有幸膜拜了学军的神题.祝NOI2015圆满成功 同时膜拜碾压了蒟蒻的众神QAQ 填填填 我的DP比较逗比……( ...
随机推荐
- K8S环境的Jenkin性能问题处理续篇(任务Pod设置)
欢迎访问我的GitHub 这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos K8S环境的Jenkin性能问题处理 本文是<K ...
- Vim最强调试插件:vimspector
最近看到了韦大在知乎的回答后,想去试用一下vimspector,却发现vimspector诞生两年了却没有介绍它的中文资料.我查阅官方文档遇到不少困难,在这里记录折腾出来的结果,与大家分享. vims ...
- hasura的golang反向代理
概述 反向代理代码 对请求的处理 对返回值的处理 遇到的问题 概述 一直在寻找一个好用的 graphql 服务, 之前使用比较多的是 prisma, 但是 prisma1 很久不再维护了, 而 pri ...
- 微信小程序 audio组件 默认控件 无法隐藏/一直显示/改了controls=‘false’也没用2019/5/28
<audio>默认控件,如果需要隐藏,不需要特意设置controls = 'false',直接把这个属性删除即可,不然无论如何都会存在 之前,设置了controls = 'false' & ...
- 晋城6397.7539(薇)xiaojie:晋城哪里有xiaomei
晋城哪里有小姐服务大保健[微信:6397.7539倩儿小妹[晋城叫小姐服务√o服务微信:6397.7539倩儿小妹[晋城叫小姐服务][十微信:6397.7539倩儿小妹][晋城叫小姐包夜服务][十微信 ...
- 从Linux源码看Socket(TCP)的bind
从Linux源码看Socket(TCP)的bind 前言 笔者一直觉得如果能知道从应用到框架再到操作系统的每一处代码,是一件Exciting的事情. 今天笔者就来从Linux源码的角度看下Server ...
- JavaSE学习笔记03流程控制
Java流程控制 1.顺序结构 java的基本结构就是顺序结构,除非特别指明,否则就按照顺序一句一句往下执行. 顺序结构是最简单的算法结构,它是任何一个算法都离不开的一种基本算法结构. 2. 选择结构 ...
- Anderson《空气动力学基础》5th读书笔记 第4记——黏性流动入门
目录 一.边界层的概念 二.边界层的产生原因 三.剪切力的公式 四.温度分布情况 五.雷诺数与层流.湍流 一.边界层的概念 我们先来介绍边界层的概念(边界层正是黏性流动的产物),边界层是紧挨物体的薄层 ...
- Prometheus入门教程(三):Grafana 图表配置快速入门
文章首发于[陈树义]公众号,点击跳转到原文:https://mp.weixin.qq.com/s/sA0nYevO8yz6QLRz03qJSw 前面我们使用 Prometheus + Grafana ...
- Vue踩坑日记-This dependency was not found:element-ui.js
该问题为在Vue启动项目时候报错找不到element-ui模块 解决办法:打开CMD 控制台 CD到项目根目录 我的目录(C:\Users\Administrator\Desktop\cms-heli ...