python机器学习实现逻辑斯蒂回归
逻辑斯蒂回归
关注公众号“轻松学编程”了解更多。
【关键词】Logistics函数,最大似然估计,梯度下降法
1、Logistics回归的原理
利用Logistics回归进行分类的主要思想是:根据现有数据对分类边界线建立回归公式,以此进行分类。这里的“回归” 一词源于最佳拟合,表示要找到最佳拟合参数集。
训练分类器时的做法就是寻找最佳拟合参数,使用的是最优化算法。接下来介绍这个二值型输出分类器的数学原理。
Logistic Regression和Linear Regression的原理是相似的,可以简单的描述为这样的过程:
(1)找一个合适的预测函数,一般表示为h函数,该函数就是我们需要找的分类函数,它用来预测输入数据的判断结果。这个过程是非常关键的,需要对数据有一定的了解或分析,知道或者猜测预测函数的“大概”形式,比如是线性函数还是非线性函数。
(2)构造一个Cost函数(损失函数),该函数表示预测的输出(h)与训练数据类别(y)之间的偏差,可以是二者之间的差(h-y)或者是其他的形式。综合考虑所有训练数据的“损失”,将Cost求和或者求平均,记为J(θ)函数,表示所有训练数据预测值与实际类别的偏差。
(3)显然,J(θ)函数的值越小表示预测函数越准确(即h函数越准确),所以这一步需要做的是找到J(θ)函数的最小值。找函数的最小值有不同的方法,Logistic Regression实现时有梯度下降法(Gradient Descent)。
1) 构造预测函数
Logistic Regression虽然名字里带“回归”,但是它实际上是一种分类方法,用于二分类问题(即输出只有两种)。首先需要先找到一个预测函数(h),显然,该函数的输出必须是两类值(分别代表两个类别),所以利用了Logistic函数(或称为Sigmoid函数),函数形式为:
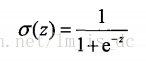
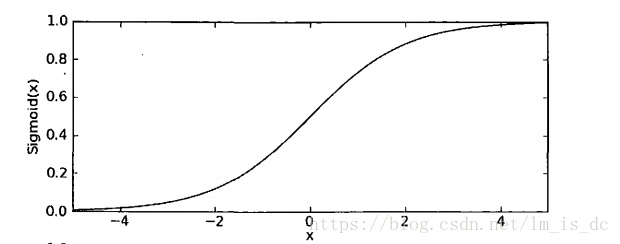
该函数形状为:
2)优缺点
优点:实现简单,计算代价不高,速度很快
缺点:分类精度可能不高
适用场景:样本数据量极大的情况下
2、实战
sklearn.linear_model.LogisticRegression(solver=‘liblinear’)
solver参数的选择:
- “liblinear”:小数量级的数据集
- “lbfgs”, “sag” or “newton-cg”:大数量级的数据集以及多分类问题
- “sag”:极大的数据集
注意:
以下命令都是在浏览器中输入。
cmd命令窗口输入:jupyter notebook
后打开浏览器输入网址http://localhost:8888/
1) 手写数字数据集的分类
使用KNN与Logistic回归两种方法
导包
#导入数据load_digits()
from matplotlib import pyplot as plt
from sklearn.datasets import load_digits
获取数据
digits = load_digits()
#digits
images = digits.images#表示的是真实的图片数据
data = digits.data #样本特征数据
target = digits.target #目标数据
#images.shape返回的(1797,8,8)表示的是一共1717张像素为8*8的图片,
#如果将每张图片作为特征样本,则一共有1717个样本数据。每一个样本数据
#都是一个8*8的二维数据。
#data是images可作为样本特征数据的一种形式。
#images本身不可作为样本的特征数据。
#原因是:特征数据都是二维形式存在的,行表示特征数据的个数,
#列表示特征的不同分类。
#而images是三维的需要进行扁平化处理成二维的才可作为特征数据。
#而data就是images经过扁平化处理之后的数据值。
如果图像样本集中没有把图像扁平化处理成二维数据,那么需要自己手动处理,处理代码如下(本实例中已经有处理好的二维数据data)
#对一个8*8的图片进行扁平化处理,通过循环逐一进行扁平化处理
data_= images[0].ravel().reshape(1,-1)
for i in range(1,images.shape[0]):
data_=np.concatenate((data_,images[i].ravel().reshape(1,-1)))
data_.shape
#得到的data_和data是一样的的
创建模型,训练和预测
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
拆分样本集
X_train,X_test,y_train,y_test = train_test_split(data,target,
test_size=0.2,
random_state=1)
logistic 分类模型
#创建模型对象
logistic = LogisticRegression()
#测试 训练模型花费的时间
%time logistic.fit(X_train,y_train)

#对训练后的模型进行评分
logistic.score(X_test,y_test)
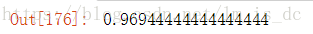
knn分类模型
#创建模型
knn = KNeighborsClassifier(n_neighbors=9)
#测试 训练模型花费的时间
%time knn.fit(X_train,y_train)

#对训练后的模型进行评分
knn.score(X_test,y_test)
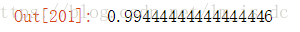
2) 使用make_blobs产生数据集进行分类
导包使用datasets.make_blobs创建一系列点
Logistics模型
导包
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
import matplotlib.pyplot as plt
%matplotlib inline
# make_blobs是一个函数,可以创建一个分类样本集
from sklearn.datasets import make_blobs
from sklearn.linear_model import LogisticRegression
创建分类样本集
设置三个中心点,随机创建150个点
#参数1:样本个数
#参数2:样本特征数
#参数3:表示中心点(分类的类别数量)。一类样本数据会围绕中心点分布
#返回值:样本集(特征数据和目标数据)
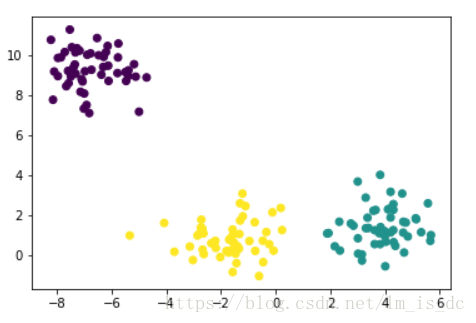
X_train,y_train = make_blobs(n_samples=150,n_features=2,centers=3)
#centers=[[2,6],[4,2],[6,5]],参数centers可以是具体的坐标点
绘制分类样本图
plt.scatter(X_train[:,0],X_train[:,1],c=y_train)
创建logistic分类模型
logistic = LogisticRegression()
训练模型
logistic.fit(X_train,y_train)
获取坐标系所有点作为测试数据
#将整个坐标系中的所有点获取,作为分类测试数据
xmin,xmax = X_train[:,0].min()-0.5,X_train[:,0].max()+0.5
ymin,ymax = X_train[:,1].min()-0.5,X_train[:,1].max()+0.5
x = np.linspace(xmin,xmax,300)
y = np.linspace(ymin,ymax,300)
xx,yy = np.meshgrid(x,y)
X_test = np.c_[xx.ravel(),yy.ravel()]
模型预测
#获得分类测试结果
y_ = logistic.predict(X_test)
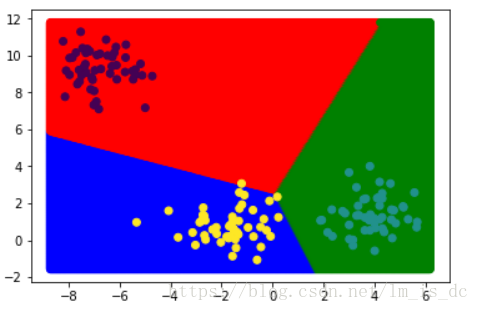
绘制分类边界图
from matplotlib.colors import ListedColormap
cmap = ListedColormap(['r','g','b'])
logistic模型绘制的分类边界是一条直线。
Knn模型
#导入knn模型包
from sklearn.neighbors import KNeighborsClassifier
#创建模型并训练
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train,y_train)
#获取模型预测的数据
y1_ = knn.predict(X_test)
#绘制分类边界图
plt.scatter(X_test[:,0],X_test[:,1],c=y1_,cmap=cmap)
plt.scatter(X_train[:,0],X_train[:,1],c=y_train)
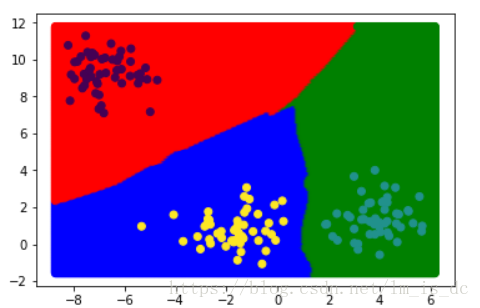
knn模型绘制的分类边界是一条曲线,预测结果更加精准。
结论
KNN和Logistic对比:
KNN:时间和空间复杂度高。准确率高。
Logistic:时间复杂度和空间复杂度低,准确率低于KNN 。
3)预测年收入是否大于50K美元
读取adult.txt文件,并使用逻辑斯底回归算法训练模型,根据种族、职业、工作时长来预测一个人的性别 。
#导包
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
import matplotlib.pyplot as plt
%matplotlib inline
#读取数据
data= pd.read_csv('./adults.txt')
data
#提取特征数据
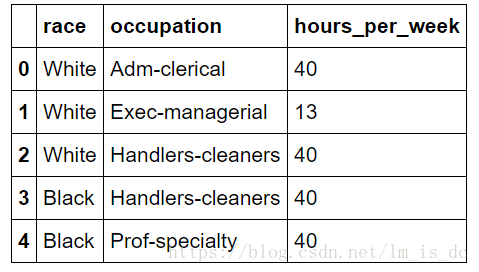
features=data[['race','occupation','hours_per_week']]
features.head()
#提取目标数据
target=data['sex']
target.head()

#‘race’这一列里的数据是字符串,
#需要映射替换成数字才能参与模型训练的运算
#获取种族类型数量
r_unique=features['race'].unique()
r_unique_size=r_unique.size
#创建对角矩阵
dm=np.eye(r_unique_size)
#定义一个映射函数
def trans(r):
index=np.argwhere(r==r_unique)[0][0]
return dm[index]
#映射
features['race']=features['race'].map(trans)
#‘occupation’职业也一样,需要映射替换成数字
o_unique=features['occupation'].unique()
o_unique_size=o_unique.size
#创建对角矩阵
dm=np.eye(o_unique_size)
#定义一个映射函数
def trans(o):
index=np.argwhere(o==o_unique)[0][0]
return dm[index]
#映射
features['occupation']=features['occupation'].map(trans)
features.head()
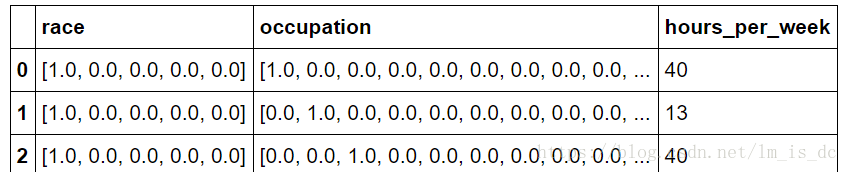
#‘race’里面的每一个数组拆分成n列然后再合并
race=features['race'][0]
for item in features['race'][1:]:
race=np.concatenate((race,item))
race=race.reshape(-1,r_unique_size)
race

#‘occupation’里面的每一个数组拆分成n列然后再合并
occupation=features['occupation'][0]
for item in features['occupation'][1:]:
occupation=np.concatenate((occupation,item))
occupation=occupation.reshape(-1,o_unique_size)
occupation

hours=features['hours_per_week'].values.reshape(-1,1)
hours

#把三个特征数据合并成二维数组
train=np.hstack((race,occupation,hours))
train

#对最后一列进行归一化处理
train[:,-1:] = train[:,-1:]/train[:,-1:].sum()
train[:,-1:]

#导入模型包
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
#把样本集数据拆分成训练数据和测试数据
x_train,x_test,y_train,y_test=train_test_split(train,target,
test_size=0.2,
random_state=1)
logistic模型
#创建logistic模型对象
logistic=LogisticRegression()
#训练模型
logistic.fit(x_train,y_train)
#对模型进行评分
logistic.score(x_test,y_test)
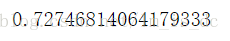
#检测logistic模型训练花费的时间
%time logistic.fit(x_train,y_train)
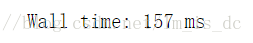
knn模型
knn=KNeighborsClassifier(n_neighbors=99)
knn.fit(x_train,y_train)
#对模型进行评分
knn.score(x_test,y_test)
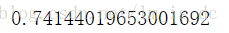
#检测knn模型训练花费的时间
%time knn.fit(x_train,y_train)
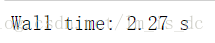
4)从疝气病症预测病马的死亡率
#导入归一化函数处理包
from sklearn.preprocessing import MinMaxScaler,StandardScaler,Normalizer
#读取数据
train = pd.read_csv('./data/horseColicTraining.txt',
sep='\t',header=None)
test = pd.read_csv('./data/horseColicTest.txt',
sep='\t',header=None)
#训练集的特征数据和目标数据
X_train = train.values[:,:21]
y_train = train[21]
#测试集的特征数据和目标数据
X_test = test.values[:,:21]
y_test = test[21]
#使用函数Normalizer()进行归一化处理
X_test1 = Normalizer().fit_transform(X_test)
X_train1 = Normalizer().fit_transform(X_train)
#创建knn模型
knn = KNeighborsClassifier()
#训练模型并评分
knn.fit(X_train1,y_train).score(X_test1,y_test)
使用MinMaxScaler()对特征数据进行归一化
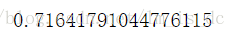
X_train2 = MinMaxScaler().fit_transform(X_train)
X_test2 = MinMaxScaler().fit_transform(X_test)
#训练模型并评分
knn.fit(X_train2,y_train).score(X_test2,y_test)
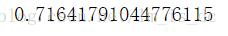
使用StandardScaler()对特征数据进行归一化
X_train3 = StandardScaler().fit_transform(X_train)
X_test3 = StandardScaler().fit_transform(X_test)
#训练模型并评分
knn.fit(X_train3,y_train).score(X_test3,y_test)
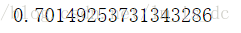
使用logistic模型
#创建logistic模型对象
logistic = LogisticRegression(C=3)
#训练模型并评分
logistic.fit(X_train1,y_train).score(X_test1,y_test)
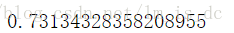
结论:
从评分可以看出在这个例子中logistic模型评分较高,使用这个模型较好。
后记
【后记】为了让大家能够轻松学编程,我创建了一个公众号【轻松学编程】,里面有让你快速学会编程的文章,当然也有一些干货提高你的编程水平,也有一些编程项目适合做一些课程设计等课题。
也可加我微信【1257309054】,拉你进群,大家一起交流学习。
如果文章对您有帮助,请我喝杯咖啡吧!
公众号


关注我,我们一起成长~~
python机器学习实现逻辑斯蒂回归的更多相关文章
- 【转】机器学习笔记之(3)——Logistic回归(逻辑斯蒂回归)
原文链接:https://blog.csdn.net/gwplovekimi/article/details/80288964 本博文为逻辑斯特回归的学习笔记.由于仅仅是学习笔记,水平有限,还望广大读 ...
- 机器学习之LinearRegression与Logistic Regression逻辑斯蒂回归(三)
一 评价尺度 sklearn包含四种评价尺度 1 均方差(mean-squared-error) 2 平均绝对值误差(mean_absolute_error) 3 可释方差得分(explained_v ...
- spark机器学习从0到1逻辑斯蒂回归之(四)
逻辑斯蒂回归 一.概念 逻辑斯蒂回归(logistic regression)是统计学习中的经典分类方法,属于对数线性模型.logistic回归的因变量可以是二分类的,也可以是多分类的.logis ...
- [置顶] 局部加权回归、最小二乘的概率解释、逻辑斯蒂回归、感知器算法——斯坦福ML公开课笔记3
转载请注明:http://blog.csdn.net/xinzhangyanxiang/article/details/9113681 最近在看Ng的机器学习公开课,Ng的讲法循循善诱,感觉提高了不少 ...
- 【分类器】感知机+线性回归+逻辑斯蒂回归+softmax回归
一.感知机 详细参考:https://blog.csdn.net/wodeai1235/article/details/54755735 1.模型和图像: 2.数学定义推导和优化: 3.流程 ...
- 【项目实战】pytorch实现逻辑斯蒂回归
视频指导:https://www.bilibili.com/video/BV1Y7411d7Ys?p=6 一些数据集 在pytorch框架下,里面面有配套的数据集,pytorch里面有一个torchv ...
- [转]逻辑斯蒂回归 via python
# -*- coding:UTF-8 -*-import numpydef loadDataSet(): return dataMat,labelMat def sigmoid(inX): retur ...
- 逻辑斯蒂回归(Logistic Regression)
逻辑回归名字比较古怪,看上去是回归,却是一个简单的二分类模型. 逻辑回归的模型是如下形式: 其中x是features,θ是feature的权重,σ是sigmoid函数.将θ0视为θ0*x0(x0取值为 ...
- 逻辑斯蒂回归VS决策树VS随机森林
LR 与SVM 不同 1.logistic regression适合需要得到一个分类概率的场景,SVM则没有分类概率 2.LR其实同样可以使用kernel,但是LR没有support vector在计 ...
随机推荐
- linux(centos)环境下安装rabbitMq
1.由于rabbitMq是用Erlang语言写的,因此要先安装Erlang环境 下载Erlang :http://www.rabbitmq.com/releases/erlang/erlang-19. ...
- C++ 构造函数 隐式转换 深度探索,由‘类对象的赋值操作是否有可能调用到构造函数’该实验现象引发
Test1 /** Ques: 类对象的赋值操作是否有可能调用到构造函数 ? **/ class mystring { char str[100]; public: mystring() //myst ...
- python双向链表的实现
python双向链表和单链表类似,只不过是增加了一个指向前面一个元素的指针,下面的代码实例了python双向链表的方法 示意图: python双向链表实现代码: # -*- coding: utf-8 ...
- c++中CreateEvent函数
参考:https://blog.csdn.net/u011642774/article/details/52789969 函数原型: HANDLE CreateEvent( LPSECURITY_AT ...
- 《C++primerplus》第8章练习题
1.(简单用一下引用变量,没有采用书中的题目)定义一个替身结构体,存储名字(char[])和力量值(int).使用结构体引用作为形参写两个函数,一个不加const,使得能对定义的结构体做修改,另一个加 ...
- 深入了解如何构建您的第一个多语言ASP。NET MVC 5 Web应用程序
下载demo - 3.9 MB 介绍 这篇文章解释了如何创建一个简单的多语言ASP.NET MVC 5 Web应用程序.该应用程序将能够处理英语(美国),西班牙语和法语.英语将是默认语言.当然,扩展解 ...
- (OK) Android内核(4.9)集成最新版MPTCP---成功
Android内核(4.9)集成最新版MPTCP---成功
- 多测师讲解python函数 _open_高级讲师肖sir
open()函数 #open() 函数用于打开一个文件,创建一个 file 对象 #Python open() 函数用于打开一个文件,并返回文件对象, # 在对文件进行处理过程都需要使用到这个函数,如 ...
- MeteoInfoLab脚本示例:获取一维数据并绘图
气象数据基本为多维数据(通常是4维,空间3维加时间维),只让数据中一维可变,其它维均固定即可提取一维数据.比如此例中固定了时间维.高度维.纬度维,只保留经度维可变:hgt = f['hgt'][0,[ ...
- 2019-2020-1 20209313《Linux内核原理与分析》第二周作业
2019-2020-1 20209313<Linux内核原理与分析>第二周作业 零.总结 阐明自己对"计算机是如何工作的"理解. 一.myod 步骤 复习c文件处理内容 ...