Spark学习进度7-综合案例
综合案例
文件排序

解法:
1.读取数据
2.数据清洗,变换数据格式
3.从新分区成一个分区
4.按照key排序,返还带有位次的元组
5.输出
@Test
def filesort(): Unit ={
val source=sc.textFile("dataset/filesort.txt",3)
var index=0
/*
partitionBy:把所有的分区相关的数据组成一个新的分区
HashPartitioner(1):分成一个分区,使得在一个分区内总体有序
*/
val result= source.filter(_.trim().length>0).map(n => (n.trim.toInt,""))
.partitionBy(new HashPartitioner(1))
.sortByKey().map( t=> {
index+=1
(index,t._1)
})
result.foreach(println(_))
}
二次排序
题目大意:先按照第一个比,相同则按照第二个比
题意思路:
1.读取数据
2.转换格式如下


可用图片展示:

class SecondarySortKey(val first:Int,val second:Int) extends Ordered
[SecondarySortKey] with Serializable{ override def compare(that: SecondarySortKey): Int = {
if(this.first-that.first!=0){
this.first-that.first
}else {
this.second-that.second
}
}
}
//二次排序
@Test
def sortsecond(): Unit ={ val source=sc.textFile("dataset/secondsort.txt",3)
val secondrdd = source.map(item => (new SecondarySortKey(item.split(" ")(0).toInt, item.split(" ")(1).toInt), item))
.partitionBy(new HashPartitioner(1))
secondrdd.sortByKey(false)
.map(item => item._2)
.foreach(println(_)) }
连接操作
案例介绍:
有两个表:movie表,和score表
score:包含的信息为:用户ID,电影ID,电影评分
movie:电影ID,电影名字
我们想要得到,评分超过4分的(电影ID,电影名字,电影评分)
思路如下:
首先先弄score表:
1.获取想要的信息
2.获取对应电影ID的平均值
3.更换格式:keyBy,如下

对于movie表进行连接,连接前需要变化下格式
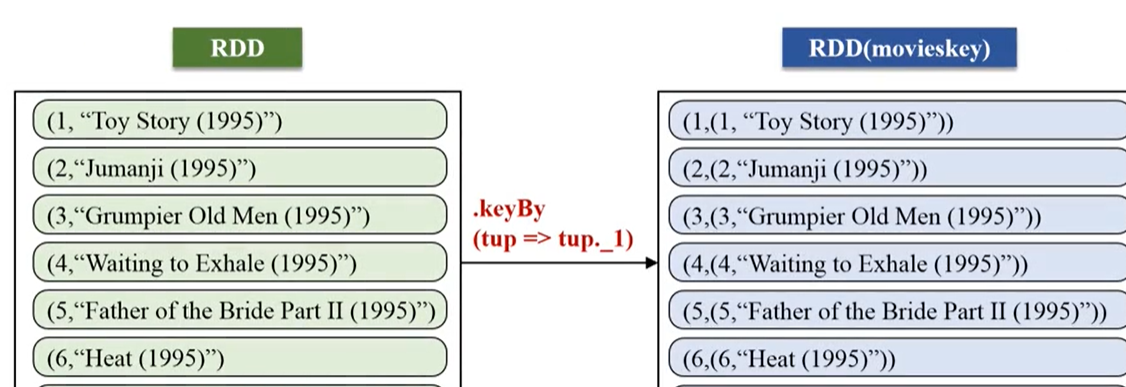
然后可通过相同的key进行连接join,后的结果如下:
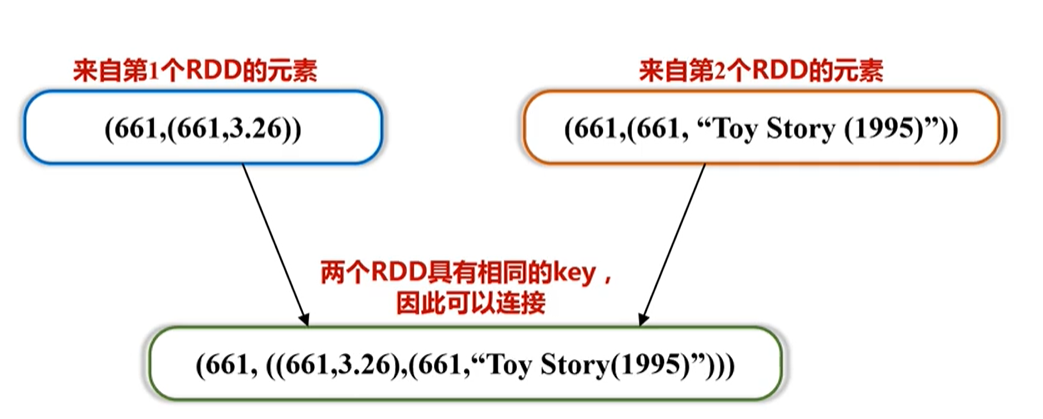
进行评分的过滤,然后取出需要的数据
@Test
/*
score:包含的信息为:用户ID,电影ID,电影评分
movie:电影ID,电影名字
*/
def joinTest(): Unit ={
val scoreRDD=sc.textFile("dataset/score.txt")
.map(line => {
val filed=line.split(",")
(filed(1).toInt,filed(2).toDouble)
})
.groupByKey()
.map(data =>{
val avg=data._2.sum/data._2.size
(data._1,avg)
})
.keyBy(it =>it._1) val movie=sc.textFile("dataset/movie.txt")
.map(line => {
val filed=line.split(",")
(filed(0).toInt,filed(1))
})
.keyBy(it =>it._1) scoreRDD.join(movie)
.filter(item => item._2._1._2>4.0)
.map(it => (it._1,it._2._2._2,it._2._1._2))
.foreach(println(_))
}
输出:
score表:

movie表:

最终输出:

Spark学习进度7-综合案例的更多相关文章
- Spark学习进度11-Spark Streaming&Structured Streaming
Spark Streaming Spark Streaming 介绍 批量计算 流计算 Spark Streaming 入门 Netcat 的使用 项目实例 目标:使用 Spark Streaming ...
- Spark学习进度-Spark环境搭建&Spark shell
Spark环境搭建 下载包 所需Spark包:我选择的是2.2.0的对应Hadoop2.7版本的,下载地址:https://archive.apache.org/dist/spark/spark-2. ...
- Spark学习进度-实战测试
spark-shell 交互式编程 题目:该数据集包含了某大学计算机系的成绩,数据格式如下所示: Tom,DataBase,80 Tom,Algorithm,50 Tom,DataStructure ...
- SparkSQL学习进度9-SQL实战案例
Spark SQL 基本操作 将下列 JSON 格式数据复制到 Linux 系统中,并保存命名为 employee.json. { "id":1 , "name&quo ...
- Spark学习进度10-DS&DF基础操作
有类型操作 flatMap 通过 flatMap 可以将一条数据转为一个数组, 后再展开这个数组放入 Dataset val ds1=Seq("hello spark"," ...
- Spark学习进度-RDD
RDD RDD 是什么 定义 RDD, 全称为 Resilient Distributed Datasets, 是一个容错的, 并行的数据结构, 可以让用户显式地将数据存储到磁盘和内存中, 并能控制数 ...
- Spark学习进度-Transformation算子
Transformation算子 intersection 交集 /* 交集 */ @Test def intersection(): Unit ={ val rdd1=sc.parallelize( ...
- spark 学习路线及参考课程
一.Scala编程详解: 第1讲-Spark的前世今生 第2讲-课程介绍.特色与价值 第3讲-Scala编程详解:基础语法 第4讲-Scala编程详解:条件控制与循环 第5讲-Scala编程详解:函数 ...
- 【原创 Hadoop&Spark 动手实践 13】Spark综合案例:简易电影推荐系统
[原创 Hadoop&Spark 动手实践 13]Spark综合案例:简易电影推荐系统
随机推荐
- WEB安全漏洞挖掘向入坑指北
这个指北不会给出太多的网站和方向建议,因为博主相信读者能够从一个点从而了解全局,初期的时候就丢一大堆安全网址导航只会浇灭人的热情,而且我也不适合传道授业解惑hhh 安全论坛: 先知社区 freebuf ...
- javascript (JS组成、书写位置、基本概念、作用域、内存问题、变量)
1 JavaScript的组成和书写位置 Javascript:运行在客户端(浏览器)的脚本语言,JavaScript的解释器被称为JavaScript引擎,为浏览器的一部分,与java没有直接的关系 ...
- python+request+unittest+HTMLTestRunner
https://www.imooc.com/article/details/id/20813 https://www.cnblogs.com/fennudexiaoniao/p/7771931.htm ...
- dataframe 检查缺失值
s = df.isnull().any() #返回series形式,可以用enumerate打印s #true代表有空值 null_index = [] for i,j in enumerate(s) ...
- 添加和读取Resources嵌入资源文件(例如.dll和.ssk文件)
前言:有些程序运行的时候,可能调用外部的dll,用户使用时可能会不小心丢失这些dll,导致程序无法正常运行,因此可以考虑将这些dll嵌入到资源中,启动时自动释放.对于托管的dll,我们可以用打包软件合 ...
- Codeforces Edu Round 56 A-D
A. Dice Rolling 把\(x\)分解为\(a * 6 + b\),其中\(a\)是满6数,\(b\)满足\(1 <= b < 6\),即可... #include <io ...
- Jwt令牌创建
添加依赖 <dependencies> <!-- jwt --> <dependency> <groupId>io.jsonwebtoken</g ...
- I/O-基本概念
目录 演变过程 I/O系统基本组成 I/O接口 I/O方式简介 小结 演变过程 I/O系统基本组成 分成软件和硬件 I/O接口 接口可以看作是两个部件之间的交接部分 I/O方式简介 小结
- 00-JAVA语法基础
1. 原码为数的二进制数,反码是将其二进制数每一位按位取反.补码则不同,正数的补码是其原码本身,负数的补码是其除符号位以外其他每一位按位取反再加一,符号位不变. int a=100; a=a>& ...
- Service Cloud 零基础(二)Knowledge浅谈
本篇参考:https://trailhead.salesforce.com/content/learn/projects/set-up-salesforce-knowledge https://tra ...