Salesforce 大数据量处理篇(二)Index
本篇参考:
https://baike.baidu.com/item/%E6%95%B0%E6%8D%AE%E5%BA%93%E7%B4%A2%E5%BC%95/8751686?fr=aladdin
https://help.salesforce.com/articleView?id=000325257&type=1&mode=1
https://help.salesforce.com/articleView?id=000334796&type=1&mode=1
我们在做项目得时候,通常会有需求是根据很多入力条件进行SOQL查询,然后展示 List。好多程序最开始跑的是没有问题得,当数据达到一定数据量比如百万级别以后,可能特别慢,或者更不好的情况下,直接崩溃了。针对这种情况有很多种可能情况导致,其中最常见的一种情况是:你当前的SOQL 语句不是selective的,或者是selective的情况下没有达到最大的优化。那什么样的SOQL语句是selective的,有什么定义或者特点去区分,如何去更好的优化SOQL呢?接下来的内容就抛砖引玉,引出相关的话题。
一. selective的SOQL语句
我们想确定一个SOQL是否为selective的,当前SOQL应该具有以下的特征:
1. where后面的filter的字段应该最少有一个索引字段(字段应该是 indexed的)。索引字段的概念我们后面会单独作为一个部分来讲;
2. 如果filter的字段包含了索引字段,我们将确定一下当前的SOQL返回了多少条数据。针对返回的数据的条数,我们需要看当前的索引字段是标准的索引还是自定义索引。对于标准索引,阈值是第一个百万目标记录的30%,以及第一个百万目标记录之后所有记录的15%。此外,标准索引的选择性阈值最大为100万条总目标记录,只有在总记录数超过560万条时才能达到。对于自定义索引,选择性阈值为第一个百万目标记录的10%,以及第一个百万目标记录之后所有记录的5%。此外,自定义索引的,只有在这个表记录数超过5,6百万条的情况下,选择性阈值最大为333333条目标记录被认为是selective的。
(注:阈值我们可以理解成临界值,即当前的SOQL语句在当前系统通过当前 filter能查询出来的最大值)
举个例子。我们搜索一个自定义表,目前数据量有30万条,因为他是100万条以内,所以如果使用了标准的索引,阈值 = 300000 * 30% = 90000条,也就是说当查询的SQL返回的数据如果使用标准索引只要返回的数量在90000条以内,就代表当前的SOQL是selective的。针对自定义要求是10% * 300000 = 30000条,即返回数据在这个以内代表当前的数据是selective的。
所以一言以蔽之,selective的SOQL的语句具备的特性有两个: 1. filter包含 索引字段;2.查询出来的数据满足当前要求的阈值。只有当前的SOQL是selective的情况下,我们才可以使用工具去进行优化。什么工具呢?看下面。
二. Query Plan Tool
概念和使用暂且不提,先看一下Query Plan Tool如何启用以及在哪里。我们打开 develop console,点击menu部分的help,选择 Preferences,然后弹出的地方我们便可以看到针对 Enable Query Plan的设置,默认就是true代表已经启用,这样我们在下面的 Query Editor中输入相关的SOQL以后,便可以使用 Query Plan Tool来了解官方对当前的SOQL的建议了。
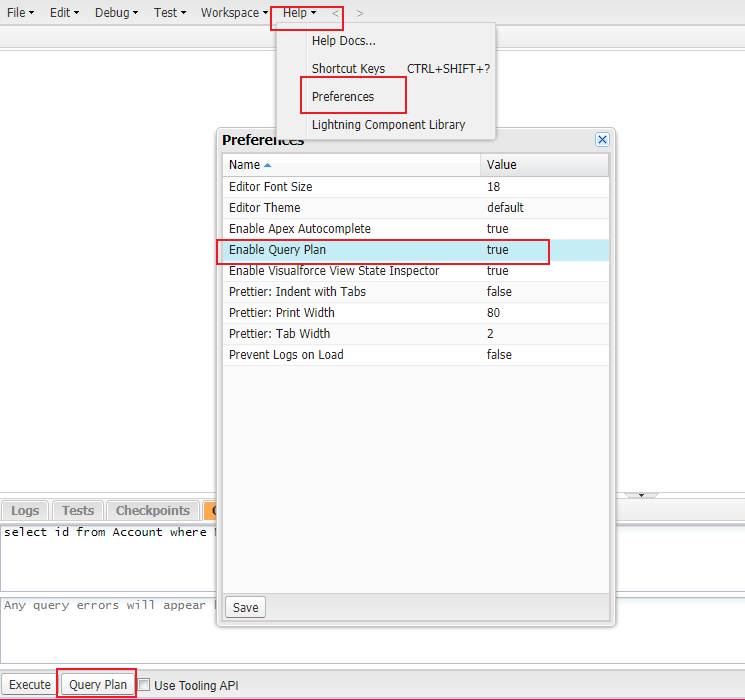
使用Query Plan Tool用于SOQL运行缓慢的检测以及优化建议,所以不是所有的场景都需要了解他,当你的数据量特别大,当前SOQL运行特别缓慢,使用它。否则了解这个概念和工具就好。
我们先写一个SQL看一下效果。下图为使用 Query Plan的效果图。包含两个大部分,上面的列表(Plan List)以及下面的Notes部分。
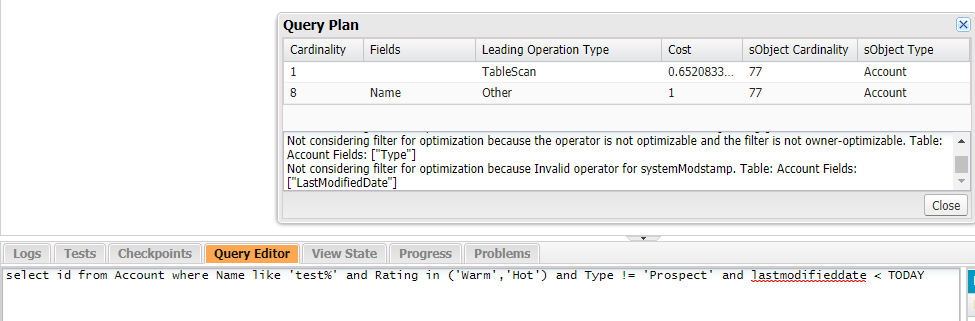
我们看到每个Plan里面都会包括 Cardinality / Fields / Leading Operation Type / Cost / sObject Cardinality / sObject Type。这些列什么含义,如何去理解?
- Cardinality(基数):使用 Leading Operation Type操作方式情况下,预估的返回的数据条数;
- Fields:查询优化器(Query Optimizer)中使用的索引字段。如果 Leading Operation Type是 索引的,则当前的列将会展示索引字段,如果是全表扫描的模式,则当前的这个列将展示空;
- Leading Operation Type:Salesforce将用于优化查询的主要操作类型。这里有4个值:
- Index:当前查询的对象使用索引进行查询;
- Sharing:当前的查询将会使用索引进行查询。当前的索引基于当前执行SQL的人的共享规则来决定的。如果有 sharing rule限制了user可以访问的记录情况下,salesforce可以根据这些共享规则去进行优化;
- TableScan:当前的查询方式为查询当前表的所有数据;
- Other:salesforce将使用内部的优化方式去查询。
- Cost:与Force.com查询优化器的选择性阈值相比,查询的成本。 如果这个值大于1表示查询不会是selective的。
- sObject Cardinality:查询当前对象大概的记录数;
- sObject Type:当前查询表的 object的名字。
以上的就是关于查询的Plan表的各个列的名词解释。下图附上一张 Cost超过1的情况,因为查询的 filter没有索引字段,所以查询非 selective,cost超过了1.

我们通过Notes等信息以及上面的表格便可以查看到对SOQL进行优化建议。细节得 Query Plan Tool介绍我们可以查看上方得链接中官方描述得文档。上面我们提到了 selective的SOQL必须是包含索引字段,那么在salesforce的世界里面哪些是索引字段,怎么设置索引字段呢???
三. Index(索引)
索引这个概念不止针对salesforce的SOQL,其他的类似SQL server以及 Oracle都有索引的概念,查询的filter中通过索引字段可以加快查询的速度。具体的索引的含义也可以查看上面的百度百科的文档。Salesforce针对索引字段有标准和自定义两种。我们如何知道当前哪些字段是索引字段呢?只需要进入field中,查看Indexed这列信息即可,下图展示Account表中的一些索引字段的截图。

1. 标准索引字段
salesforce针对几乎所有的表的以下字段维护了索引。分别是:RecordTypeId 、 Division、 CreatedDate、Systemmodstamp (LastModifiedDate)、Name、Email (for contacts and leads)、Foreign key relationships (lookups and master-detail)、Salesforce记录得 Record Id。也就是说表中的这些的字段,salesforce大部分已经自行维护了索引字段用来优化查询,无需在进行设置索引。
2. 自定义索引字段
当然,一个项目不可能只使用标准字段,我们还是需要创建自定义字段去实现相关得自定义逻辑。针对自定义字段同样可以设置成索引字段。当然不是所有得类型都可以设置索引字段,以下得类型salesforce不支持设置索引字段:multi-select picklists / text area (long) / text area (rich) / non-deterministic formula fields / encrypted text。编辑字段以后,勾选external Id外键以后,便成了被标记成索引得字段。外键仅可以Auto Number / Email / Number / Text类型中创建。当然,凡事不是那么绝对,如果需要在其他得字段类型中创建自定义得索引字段,包括标准字段,可以联系salesforce得support人员,他们可以进行设置。
上面有一个描述是non-deterministic formula fields不支持创建索引字段得,并不是代表formula不支持索引,只是部分情况不支持。上方得index文档中有具体描述,感兴趣自行查看。
这里扩充两个对大量数据的SOQL比较灾难的两个filter,又常常是我们经常用到的。一个是使用 formula字段进行 filter,一个是使用 null 进行filter。怎么样,项目上使用的是不是很常见?数据量少的时候OK,当真正数据量达到一定程度,你会发现这两种都是灾难性的。因为这两个默认的都是不带索引的!!!如果项目中遇到了这两种使用在filter中,并且数据量很庞大,找salesforce提support设置索引,salesforce可以针对 null单独设置索引。比如我们针对某个自定义字段 XX__c设置了 index,我们的SOQL :
select Id,Name from Account where XX__c = null
即使XX__c是索引字段也不行,需要额外的联系salesforce,将这个字段设置显示的 index用来支持null索引。
总结:当我们运行得SOQL随着数据量增加而变缓慢或者超时等错误情况下,我们可以使用 Query Plan Tool去查看是否有优化得解决方案。了解哪些类型可以进行索引设置,掌握哪些条件可以满足一个SOQL是 selective。针对上面得各个点讲的都很浅,感兴趣得查看上方提供得各个官方得文档以便更深入学习。篇中有错误欢迎指出,有不懂欢迎留言。
Salesforce 大数据量处理篇(二)Index的更多相关文章
- Salesforce 大数据量处理篇(一)Skinny Table
本篇参考:https://developer.salesforce.com/docs/atlas.en-us.salesforce_large_data_volumes_bp.meta/salesfo ...
- 大数据量时Mysql的优化
(转自网络) 如今随着互联网的发展,数据的量级也是撑指数的增长,从GB到TB到PB.对数据的各种操作也是愈加的困难,传统的关系性数据库已经无法满足快速查询与插入数据的需求.这个时候NoSQL的出现暂时 ...
- MySQL数据库如何解决大数据量存储问题
利用MySQL数据库如何解决大数据量存储问题? 各位高手您们好,我最近接手公司里一个比较棘手的问题,关于如何利用MySQL存储大数据量的问题,主要是数据库中的两张历史数据表,一张模拟量历史数据和一张开 ...
- elasticsearch5.0集群大数据量迁移方法及注意事项
当es集群的数据量较小的情况下elasticdump这个工具比较方便,但是当数据量达到一定级别比如上百G的时候,elasticdump速度就很慢了,此时我们可以使用快照的方法进行备份 elasticd ...
- DB开发之大数据量高并发的数据库优化
一.数据库结构的设计 如果不能设计一个合理的数据库模型,不仅会增加客户端和服务器段程序的编程和维护的难度,而且将会影响系统实际运行的性能.所以,在一个系统开始实施之前,完备的数据库模型的设计是必须的. ...
- POI读写大数据量EXCEL
另一篇文章http://www.cnblogs.com/tootwo2/p/8120053.html里面有xml的一些解释. 大数据量的excel一般都是.xlsx格式的,网上使用POI读写的例子比较 ...
- 大数据量高并发的数据库优化详解(MSSQL)
转载自:http://www.jb51.net/article/71041.htm 如果不能设计一个合理的数据库模型,不仅会增加客户端和服务器段程序的编程和维护的难度,而且将会影响系统实际运行的性能. ...
- 利用MySQL数据库如何解决大数据量存储问题?
提问:如何设计或优化千万级别的大表?此外无其他信息,个人觉得这个话题有点范,就只好简单说下该如何做,对于一个存储设计,必须考虑业务特点,收集的信息如下:1.数据的容量:1-3年内会大概多少条数据,每条 ...
- MySQL数据库解决大数据量存储问题
转载自:https://www.cnblogs.com/ryanzheng/p/8334915.html 提问:如何设计或优化千万级别的大表?此外无其他信息,个人觉得这个话题有点范,就只好简单说下该如 ...
随机推荐
- 【Alpha冲刺阶段】Scrum Meeting Daily6
[Alpha冲刺阶段]Scrum Meeting Daily6 1.会议简述 会议开展时间 2020/5/27 8:00 - 8:15 PM 会议基本内容摘要 每日汇报 个人进度.遇到的困难.明日的计 ...
- Acwing 405. 将他们分好队
大型补档计划 题目链接 看到分成两组,想到二分图判定 + 染色. 二分图的特点是两个有矛盾的点连一条边,考虑在这道题中,如果 \(a, b\) 中有一个人不认识对方(或者两个人互不认识),就不可能分在 ...
- 数据结构与算法——图(游戏中的自动寻路-A*算法)
在复杂的 3D 游戏环境中如何能使非玩家控制角色准确实现自动寻路功能成为了 3D 游戏开 发技术中一大研究热点.其中 A*算法得到了大量的运用,A*算法较之传统的路径规划算法,实时性更高.灵活性更强, ...
- 聚焦LS-MIMO的四大层面,浅谈5G关键技术
摘要:本文简要讲述了5G关键技术之一的LS-MIMO,分别从导频污染.信道估计.预编码技术.信号检测四个部分入手. 导频污染 理想情况下,时分复用(TDD)系统中上行链路和下行链路之间各个导频符号之间 ...
- [水题日常]UVA1625 Color Length
来整理一下思路- 一句话题意:给两个大写字母的序列,每次取出其中一个数列的第一个元素放到新序列里面,对每个字母\(c\)记它的跨度\(L(c)\)为这个字母最后出现的位置-第一次出现的位置,求新序列所 ...
- 一个 Spark 应用程序的完整执行流程
一个 Spark 应用程序的完整执行流程 1.编写 Spark Application 应用程序 2.打 jar 包,通过 spark-submit 提交执行 3.SparkSubmit 提交执行 4 ...
- Python高级语法-对象实例对象属性-类与实例,class方法静态方法等(4.6.1)
@ 目录 1.说明 2.代码 关于作者 1.说明 python中属性:类属性,实例属性 方法:类方法,实例方法,静态方法 想修改类属性,只能是类方法,因为只有类方法把cls(类)传入数据里面 静态方法 ...
- Laravel Argument 1 passed to App\Models\Recipients\AlertRecipient::__construct() must be an instance of App\Models\Recipients\string, string given,
今天测试snipet的计划任务,库存低于警告值的时候,时候会会自动发送邮件到邮箱 class SendInventoryAlerts extends Command { /** * The name ...
- 推荐系统实践 0x12 什么是Embedding
做过深度学习的小伙伴,大家应该多多少少都听说过Embedding,这么火的Embedding到底是什么呢?这篇文章就用来介绍Embedding.另外,基于深度学习的推荐系统方法或者论文还没有结束,我打 ...
- Python 的 10 个开发技巧!太实用了
1. 如何在运行状态查看源代码? 查看函数的源代码,我们通常会使用 IDE 来完成. 比如在 PyCharm 中,你可以 Ctrl + 鼠标点击 进入函数的源代码. 那如果没有 IDE 呢? 当我们想 ...