2. Linear Regression with One Variable
Speaker:Andrew Ng
这一次主要讲解的是单变量的线性回归问题。
1.Model Representation
先来一个现实生活中的例子,这里的例子是房子尺寸和房价的模型关系表达。
通过学习Linear Regression可以进行预测某一size的房子prices是多少。

Regression问题属于Supervised Learning监督学习问题,预测连续值,Classification分类是预测离散值,上一个Introduction已经介绍过。

在上一张图的坐标点就是这里的训练集合。这里我们定义m是训练数据的数量或组数,x是输入变量或特征feature,y是输出变量target。) 代表一组训练数据,例如
代表一组训练数据,例如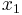 = 2104,
= 2104, 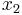 = 1416,
= 1416, 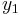 = 460.
= 460.

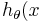=\theta_0+\theta_1x) 也可以简写成
也可以简写成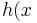) .那么我们如何来计算他的参数
.那么我们如何来计算他的参数 和
和 ?下面继续。和的值。, so that
?下面继续。和的值。, so that 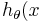) is close to
is close to 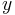 for out training examples
for out training examples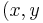) .
.









such that
2. Linear Regression with One Variable的更多相关文章
- Stanford机器学习---第二讲. 多变量线性回归 Linear Regression with multiple variable
原文:http://blog.csdn.net/abcjennifer/article/details/7700772 本栏目(Machine learning)包括单参数的线性回归.多参数的线性回归 ...
- Stanford机器学习---第一讲. Linear Regression with one variable
原文:http://blog.csdn.net/abcjennifer/article/details/7691571 本栏目(Machine learning)包括单参数的线性回归.多参数的线性回归 ...
- 机器学习笔记1——Linear Regression with One Variable
Linear Regression with One Variable Model Representation Recall that in *regression problems*, we ar ...
- Machine Learning 学习笔记2 - linear regression with one variable(单变量线性回归)
一.Model representation(模型表示) 1.1 训练集 由训练样例(training example)组成的集合就是训练集(training set), 如下图所示, 其中(x,y) ...
- Ng第二课:单变量线性回归(Linear Regression with One Variable)
二.单变量线性回归(Linear Regression with One Variable) 2.1 模型表示 2.2 代价函数 2.3 代价函数的直观理解 2.4 梯度下降 2.5 梯度下 ...
- 【cs229-Lecture2】Linear Regression with One Variable (Week 1)(含测试数据和源码)
从Ⅱ到Ⅳ都在讲的是线性回归,其中第Ⅱ章讲得是简单线性回归(simple linear regression, SLR)(单变量),第Ⅲ章讲的是线代基础,第Ⅳ章讲的是多元回归(大于一个自变量). 本文的 ...
- MachineLearning ---- lesson 2 Linear Regression with One Variable
Linear Regression with One Variable model Representation 以上篇博文中的房价预测为例,从图中依次来看,m表示训练集的大小,此处即房价样本数量:x ...
- 斯坦福第二课:单变量线性回归(Linear Regression with One Variable)
二.单变量线性回归(Linear Regression with One Variable) 2.1 模型表示 2.2 代价函数 2.3 代价函数的直观理解 I 2.4 代价函数的直观理解 I ...
- 机器学习 (一) 单变量线性回归 Linear Regression with One Variable
文章内容均来自斯坦福大学的Andrew Ng教授讲解的Machine Learning课程,本文是针对该课程的个人学习笔记,如有疏漏,请以原课程所讲述内容为准.感谢博主Rachel Zhang的个人笔 ...
- Lecture0 -- Introduction&&Linear Regression with One Variable
Introduction What is machine learning? Tom Mitchell provides a more modern definition: "A compu ...
随机推荐
- linux安装ftp步骤
1,查看是否安装了FTP:rpm -qa |grep vsftpd 2,如果没有安装,可以使用如下命令直接安装 yum -y install vsftpd 默认安装目录:/etc/vsftpd 3,添 ...
- If you see someone without smile
If you see someone without smile, give them one of yours. 难怪我每次和不认识的人说话都放肆大笑.
- innnodb_doublewrite
有写场景下,双写缓冲确实没必要,例如,你也许像在备库上禁用双写缓冲,此外,一些文件系统,例如zfs做了同样的事,所以,没必要再让innodb做一遍. innodb_double_write=0 即可关 ...
- 如何查看U盘的VID和PID
1.将USB插入电脑 2.右键单击[此电脑],选择[管理] 3.在弹出的对话框中选择[设备管理器],选择[USB大容量存储设备] 4.右键单击[USB大容量存储设备],选择[属性],在弹出的对话框中选 ...
- 训练分类器 - 基于 PyTorch
训练分类器 目前为止,我们已经掌握了如何去定义神经网络.计算损失和更新网络中的权重. 关于数据 通常来讲,当你开始处理图像.文字.音频和视频数据,你可以使用 Python 的标准库加载数据进入 Num ...
- 1.2V升压5V和2.4V升压5V芯片,适用于镍氢电池产品
一节镍氢电池1.2V升压5V电路芯片,两节镍氢电池2.4V升压到5V的电源芯片 PW5100具有宽范围的输入工作电压,从很低的0.7V到5V电压. PW5100输出电压固定3V,3.3V,5V可选固定 ...
- Vue的核心思想
Vue的核心思想主要分为两部分: 1.数据驱动 2.组件系统 1.数据驱动 在传统的前端交互中,我们是通过Ajax向服务器请求数据,然后手动的去操作DOM元素,进行数据的渲染,每当前端数据交互变化时 ...
- Ubuntu创建桌面图标
以火狐为例 创建"~/.local/share/applications/firefox_dev.desktop"文件, 文件内容为: [Desktop Entry] Name=F ...
- SpringBoot 2.0 中 HikariCP 数据库连接池原理解析
作为后台服务开发,在日常工作中我们天天都在跟数据库打交道,一直在进行各种CRUD操作,都会使用到数据库连接池.按照发展历程,业界知名的数据库连接池有以下几种:c3p0.DBCP.Tomcat JDBC ...
- [已完结]CMU数据库(15-445)实验2-B+树索引实现(下)
4. Index_Iterator实现 这里就是需要实现迭代器的一些操作,比如begin.end.isend等等 下面是对于IndexIterator的构造函数 template <typena ...