JVM 学习笔记(五)
前言:
前面的文件介绍了JVM的内存模型以及各个区域存放了那些内容,本编文章将介绍JVM中的垃圾回收Garbage Collector,和大家一起探讨一下。
如何确定一个对象是垃圾:
这里介绍两种方法:
引用计数法
可达性分析
垃圾回收算法:
标记-清除(Mark-Sweep)
标记
找出内存中需要回收的对象,并且把它们标记出来。此时堆中所有的对象都会被扫描一遍,从而才能确定需要回收的对象,比较耗时。
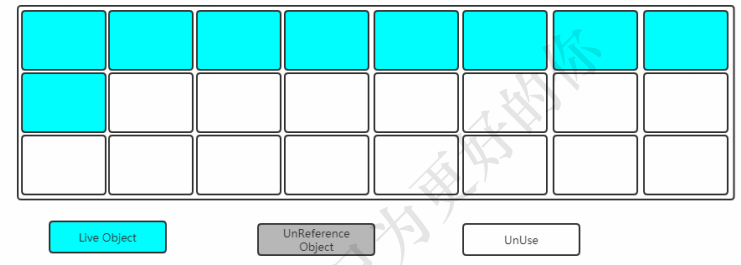
如图:绿色的区域表示当前存活的对象,灰色表示垃圾对象,白色表示没有用到的内存碎片。

2. 清除
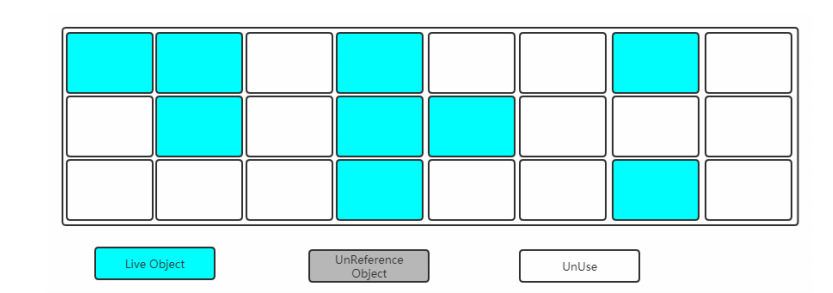
有以下缺点:
复制(Copying)
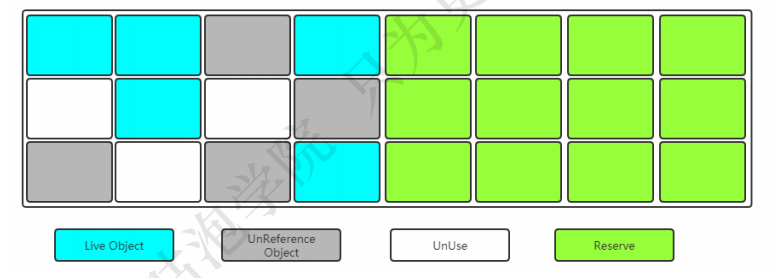
当其中一块内存使用完了,就将还存活的对象复制到另外一块上面,然后把已经使用过的内存空间一次清除掉。
下图的清理过后的内存模型:
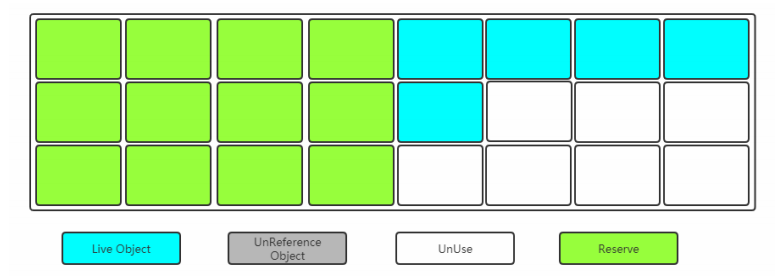
缺点:
因为这种方法保留的两个大小一样的内存区域,而同一时刻只会用到其中的一个,所以该方法内存的空间利用率比较低。
标记-整理(Mark-Compact)
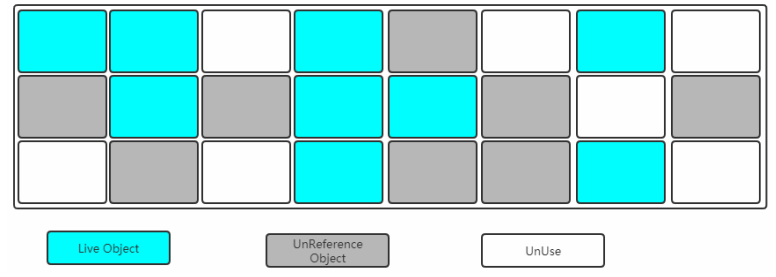
下图是整理阶段,该阶段会将被标记的区域清除,并把存活的对象往一端移动,这样内存区域就会连续化,不会有空间碎片。
分代收集算法:
垃圾收集器的介绍:
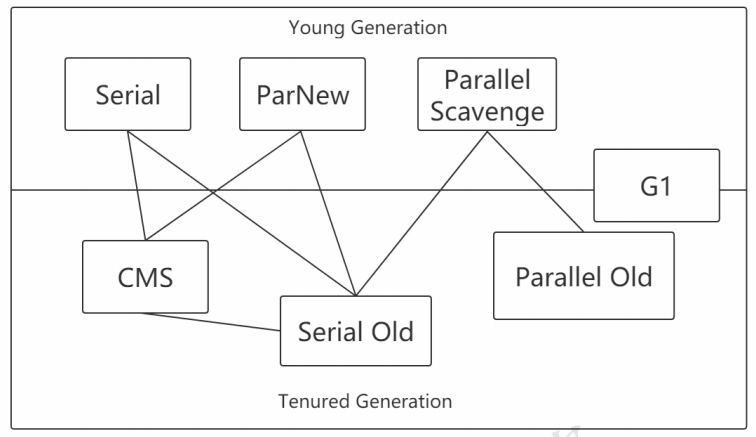
下面来介绍这几种垃圾收集器:
1.Serial收集器
优点:简单高效,拥有很高的单线程收集效率
缺点:收集过程需要暂停所有线程
算法:复制算法
适用范围:新生代
应用:Client模式下的默认新生代收集器
下图是该模式下的应用线程状态图:

2. ParNew收集器
简单理解为是Serial收集器的多线程版本。
简单总结一下该收集器:
优点:在多CPU时,比Serial效率高。
缺点:收集过程暂停所有应用程序线程,单CPU时比Serial效率差。
算法:复制算法
适用范围:新生代
应用:运行在Server模式下的虚拟机中首选的新生代收集器
3. Parallel Scavenge收集器
这里解释一下什么是吞吐量:
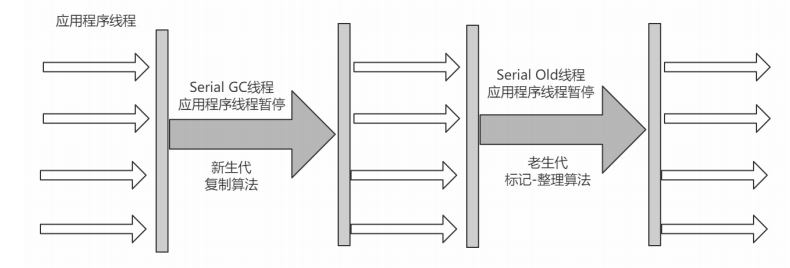
4. Serial Old收集器
下图是该模式下的应用线程状态图:
5. Parallel Old收集器
Parallel Old收集器是Parallel Scavenge收集器的老年代版本,使用多线程和"标记-整理算法"进行垃圾回收。
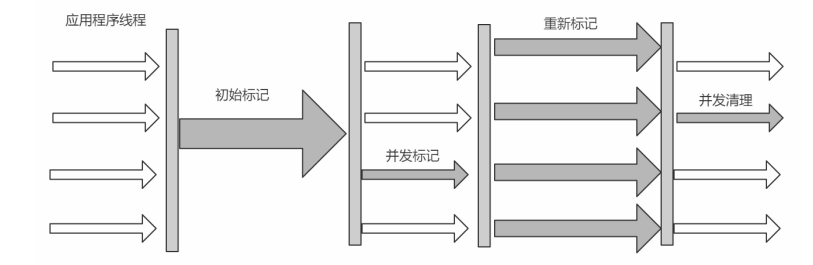
6. CMS收集器
7. G1收集器
G1 (Garbage-First)是一款面向服务器的垃圾收集器,主要针对配备多颗处理器及大容量内存的机器. 以极高概率满足GC停顿时间要求的同时,还具备高吞吐量性能特征. 在Oracle JDK 7 update 4 及以上版本中得到完全支持, 专为以下应用程序设计:
- 可以像CMS收集器一样,GC操作与应用的线程一起并发执行
- 紧凑的空闲内存区间且没有很长的GC停顿时间.
- 需要可预测的GC暂停耗时.
- 不想牺牲太多吞吐量性能.
- 启动后不需要请求更大的Java堆.
G1的长期目标是取代CMS(Concurrent Mark-Sweep Collector, 并发标记-清除). 因为特性的不同使G1成为比CMS更好的解决方案. 一个区别是,G1是一款压缩型的收集器.G1通过有效的压缩完全避免了对细微空闲内存空间的分配,不用依赖于regions,这不仅大大简化了收集器,而且还消除了潜在的内存碎片问题。除压缩以外,G1的垃圾收集停顿也比CMS容易估计,也允许用户自定义所希望的停顿参数(pause targets)
归纳总结一下G1收集器的特点:
1.并行与并发
2.分代收集(仍然保留了分代的概念)
3.空间整合(整体上属于“标记-整理”算法,不会导致空间碎片)
4.可预测的停顿(比CMS更先进的地方在于能让使用者明确指定一个长度为M毫秒的时间片段内,消耗在垃圾收集 上的时间不得超过N毫秒)。
初始标记(Initial Marking) 标记一下GC Roots能够关联的对象,并且修改TAMS的值,需要暂 停用户线程
并发标记(Concurrent Marking) 从GC Roots进行可达性分析,找出存活的对象,与用户线程并发 执行
最终标记(Final Marking) 修正在并发标记阶段因为用户程序的并发执行导致变动的数据,需 暂停用户线程
筛选回收(Live Data Counting and Evacuation) 对各个Region的回收价值和成本进行排序,根据 用户所期望的GC停顿时间制定回收计划
垃圾收集器分类:
串行收集器->Serial和Serial Old
并行收集器[吞吐量优先]->Parallel Scanvenge、Parallel Old
并发收集器[停顿时间优先]->CMS、G1
理解吞吐量和停顿时间:
如何选择合适的垃圾收集器:
首先我们了解一下官网是如何建议的:

简单翻译一下就是:
1.优先调整堆的大小让服务器自己来选择
2.如果内存小于100M,使用串行收集器
3.如果是单核,并且没有停顿时间要求,使用串行或JVM自己选
4.如果允许停顿时间超过1秒,选择并行或JVM自己选
5.如果响应时间最重要,并且不能超过1秒,使用并发收集器
JVM 学习笔记(五)的更多相关文章
- java之jvm学习笔记五(实践写自己的类装载器)
java之jvm学习笔记五(实践写自己的类装载器) 课程源码:http://download.csdn.net/detail/yfqnihao/4866501 前面第三和第四节我们一直在强调一句话,类 ...
- java jvm学习笔记五(实践自己写的类装载器)
欢迎装载请说明出处:http://blog.csdn.net/yfqnihao 课程源码:http://download.csdn.net/detail/yfqnihao/4866501 前面第三和 ...
- JVM学习笔记五:虚拟机类加载机制
类加载生命周期 类加载生命周期:加载.验证.准备.解析.初始化.使用.卸载 类加载或初始化过程什么时候开始? 遇到new.getstatic.putstatic或invokestatic这4条字节码指 ...
- java之jvm学习笔记六-十二(实践写自己的安全管理器)(jar包的代码认证和签名) (实践对jar包的代码签名) (策略文件)(策略和保护域) (访问控制器) (访问控制器的栈校验机制) (jvm基本结构)
java之jvm学习笔记六(实践写自己的安全管理器) 安全管理器SecurityManager里设计的内容实在是非常的庞大,它的核心方法就是checkPerssiom这个方法里又调用 AccessCo ...
- java之jvm学习笔记十三(jvm基本结构)
java之jvm学习笔记十三(jvm基本结构) 这一节,主要来学习jvm的基本结构,也就是概述.说是概述,内容很多,而且概念量也很大,不过关于概念方面,你不用担心,我完全有信心,让概念在你的脑子里变成 ...
- JVM学习笔记-第六章-类文件结构
JVM学习笔记-第六章-类文件结构 6.3 Class类文件的结构 本章中,笔者只是通俗地将任意一个有效的类或接口锁应当满足的格式称为"Class文件格式",实际上它完全不需要以磁 ...
- JVM学习笔记-第七章-虚拟机类加载机制
JVM学习笔记-第七章-虚拟机类加载机制 7.1 概述 Java虚拟机描述类的数据从Class文件加载到内存,并对数据进行校验.转换解析和初始化,最终形成可以被虚拟机直接使用的Java类型,这个过程被 ...
- JVM学习笔记——垃圾回收篇
JVM学习笔记--垃圾回收篇 在本系列内容中我们会对JVM做一个系统的学习,本片将会介绍JVM的垃圾回收部分 我们会分为以下几部分进行介绍: 判断垃圾回收对象 垃圾回收算法 分代垃圾回收 垃圾回收器 ...
- JVM学习笔记——类加载和字节码技术篇
JVM学习笔记--类加载和字节码技术篇 在本系列内容中我们会对JVM做一个系统的学习,本片将会介绍JVM的类加载和字节码技术部分 我们会分为以下几部分进行介绍: 类文件结构 字节码指令 编译期处理 类 ...
- C#可扩展编程之MEF学习笔记(五):MEF高级进阶
好久没有写博客了,今天抽空继续写MEF系列的文章.有园友提出这种系列的文章要做个目录,看起来方便,所以就抽空做了一个,放到每篇文章的最后. 前面四篇讲了MEF的基础知识,学完了前四篇,MEF中比较常用 ...
随机推荐
- HTTP协议浅析(一)
先来看看百度百科对HTTP的解释 http是一个简单的请求-响应协议,它通常运行在TCP之上.它指定了客户端可能发送给服务器什么样的消息以及得到什么样的响应.请求和响应消息的头以ASCII码形式给出: ...
- 一网打尽枚举操作 .net core
本文介绍如何使用枚举以及,如何将枚举类型更好的应用于项目中,看完本文可以有序的将项目中的枚举更容易的使用到每个角落. 1,分析枚举 /// <summary> /// 性别 /// < ...
- .NET Core加解密实战系列之——RSA非对称加密算法
目录 简介 功能依赖 生成RSA秘钥 PKCS1格式 PKCS8格式 私钥操作 PKCS1与PKCS8格式互转 PKCS1与PKCS8私钥中提取公钥 PEM操作 PEM格式密钥读取 PEM格式密钥写入 ...
- Linux系统管理——初学者建议
学习Linux的注意事项(一) Linux严格区分大小写 Linux是严格区分大小写的,这一点和Windows不一样,所以操作时要注意区分大小写的不同,包括文件名和目录名.命令.命令选项.配置文件配置 ...
- 线上服务的FGC问题排查,看这篇就够了!
线上服务的GC问题,是Java程序非常典型的一类问题,非常考验工程师排查问题的能力.同时,几乎是面试必考题,但是能真正答好此题的人并不多,要么原理没吃透,要么缺乏实战经验. 过去半年时间里,我们的广告 ...
- Jmeter基础002----Jmeter简单使用
一.Jmeter概述 1.概述 JMeter是Apache公司使用JAVA开发的一款开源测试工具,它的功能强大.高效,可以模拟一些高并发或多次循环等测试场景,使用方便灵活. 2.使用 安装配置java ...
- IntelliJ IDEA中项目import与open的区别
场景: 从原来公司离职来到新的公司,接手公司项目,先将项目从git或svn项目版本管理上clone下来,如果项目原先是用Eclipse开发的,而你更习惯于使用IntelliJ IDEA,下面是针对使用 ...
- mongoDB的基本使用方法
MongoDB 安装(乌班图系统) apt install mongodb mongoDB与sql的对比 SQL术语/概念 MongoDB术语/概念 解释/说明 database database 数 ...
- 乌班图设置C++11
zsh: echo "alias g++='g++ -std=c++11'" >> ~/.zshrc source ~/.zshrc bash: echo " ...
- 微信小程序-页面跳转与参数传递
QQ讨论群:785071190 微信小程序页面跳转方式有很多种,可以像HTML中a标签一样添加标签进行跳转,也可以通过js中方法进行跳转. navigator标签跳转 <view class=& ...