Impala的count(distinct QUESTION_ID) 与ndv(QUESTION_ID)
在impala中,一个select执行多个count(distinct col)会报错,举例:
select C_DEPT2,
count(distinct QUESTION_BUSI_ID) as wo_num,
count(distinct CREATOR_ID) as creator_num
from pdm.kudu_q_basic
where substr(CREATE_DATE, 1, 7) = '2020-10'
group by C_DEPT2
报错信息:
ERROR: AnalysisException: all DISTINCT aggregate functions need to have the same set of parameters as count(DISTINCT QUESTION_BUSI_ID); deviating function: count(DISTINCT CREATOR_ID)
Consider using NDV() instead of COUNT(DISTINCT) if estimated counts are acceptable. Enable the APPX_COUNT_DISTINCT query option to perform this rewrite automatically.
这时候,可通过以下方法解决:
1、得到的是近似值,数据量越大越不准确:
(1)SQL运行前,先运行命令:set APPX_COUNT_DISTINCT=true;
set APPX_COUNT_DISTINCT=true;
select C_DEPT2,
count(distinct QUESTION_BUSI_ID) as wo_num,
count(distinct CREATOR_ID) as creator_num
from pdm.kudu_q_basic
where substr(CREATE_DATE, 1, 7) = '2020-10'
group by C_DEPT2
order by C_DEPT2
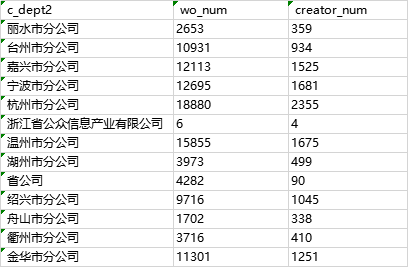
(2)将count(distinct col)用函数ndv(col)代替
select C_DEPT2,
ndv(QUESTION_BUSI_ID) as wo_num,
ndv(CREATOR_ID) as creator_num
from pdm.kudu_q_basic
where substr(CREATE_DATE, 1, 7) = '2020-10'
group by C_DEPT2
order by C_DEPT2
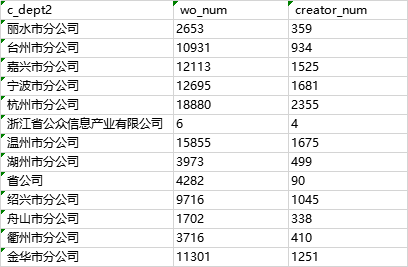
需要注意的是,在set APPX_COUNT_DISTINCT=true;的情况下,使用count(distinct col)会自动转化成ndv(col),得到的是近似值,所以以上两种方法的结果数据一致。
2、精确值。拆分为子查询,再关联,如下:
set APPX_COUNT_DISTINCT = false; -- 将参数置为false,使用count(distinct col),确保不会转化成ndv(col)
select a.C_DEPT2, a.wo_num, b.creator_num
from (select C_DEPT2, count(distinct QUESTION_BUSI_ID) as wo_num
from pdm.kudu_q_basic
where substr(CREATE_DATE, 1, 7) = '2020-10'
group by C_DEPT2) a
left join (select C_DEPT2, count(distinct CREATOR_ID) as creator_num
from pdm.kudu_q_basic
where substr(CREATE_DATE, 1, 7) = '2020-10'
group by C_DEPT2) b on a.C_DEPT2 = b.C_DEPT2
order by a.C_DEPT2
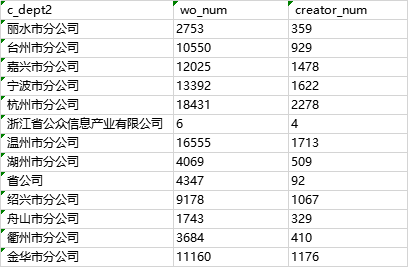
验证:
select C_DEPT2, count(*)
from pdm.kudu_q_basic -- 表中无重复数据
where substr(CREATE_DATE, 1, 7) = '2020-10'
group by C_DEPT2
order by C_DEPT2

总结:解决在impala中一个select执行多个count(distinct col)报错问题,可以用过设置参数set APPX_COUNT_DISTINCT = true;或将count(distinct col)用ndv(col)解决,但得到的是近似值,不准确。还可以通过分别在子查询中进行count(distinct col)再关联得到准确值,但要注意参数 APPX_COUNT_DISTINCT = false,不然会自动转化为ndv(col)得到的还是近似值。
Impala的count(distinct QUESTION_ID) 与ndv(QUESTION_ID)的更多相关文章
- 关于MySQL count(distinct) 逻辑的一个bug【转】
本文来自:http://dinglin.iteye.com/blog/1976026#comments 背景 客户报告了一个count(distinct)语句返回结果错误,实际结果存在值,但是用cou ...
- 使用GROUP BY统计记录条数 COUNT(*) DISTINCT
例如这样一个表,我想统计email和passwords都不相同的记录的条数 CREATE TABLE IF NOT EXISTS `test_users` ( `email_id` ) unsigne ...
- COUNT(*),count(1),COUNT(ALL expression),COUNT(DISTINCT expression)
创建一个测试表 IF OBJECT_ID( 'dbo.T1' , 'U' )IS NOT NULL BEGIN DROP TABLE dbo.T1; END; GO )); GO INSERT INT ...
- SQL server 中 COUNT DISTINCT 函数
目的:统计去重后表中所有项总和. 直观想法: SELECT COUNT(DISTINCT *) FROM [tablename] 结果是:语法错误. 事实上,我们可以一同使用 DISTINCT 和 C ...
- pandas pivot_table或者groupby实现sql 中的count distinct 功能
pandas pivot_table或者groupby实现sql 中的count distinct 功能 import pandas as pd import numpy as np data = p ...
- COUNT DISTINCT ROW_NUMBER DENSE_RANK 以及对COUNT去重(非PARTITION)
1:COUNT DISTINCT SELECT COUNT(DISTINCT [QS_QuestionStem].Id) AS ReqCount1, ...
- count(distinct) 与group by 浅析
x在传统关系型数据库中,group by与count(distinct)都是很常见的操作.count(distinct colA)就是将colA中所有出现过的不同值取出来,相信只要接触过数据库的同学都 ...
- 使用子查询可提升 COUNT DISTINCT 速度 50 倍
注:这些技术是通用的,只不过我们选择使用Postgres的语法.使用独特的pgAdminIII生成解释图形. 很有用,但太慢 Count distinct是SQL分析时的祸根,因此它是我第一篇博客的不 ...
- 【hive】count() count(if) count(distinct if) sum(if)的区别
表名: user_active_day (用户日活表) 表内容: user_id(用户id) user_is_new(是否新用户 1:新增用户 0:老用户) location_city(用户所在地 ...
随机推荐
- 最佳置换算法OPT
原文链接:https://www.jianshu.com/p/544ee20e307c
- JZOJ 11.21 提高B组反思
JZOJ 11.21 提高B组反思 T1 第二类斯特林数 直接套公式 \(S(i,j)=S(i-1,j-1)+S(i-1,j)*j\) 由于过大,\(unsigned\ long\ long\)都存不 ...
- 【NOIP2012模拟8.7】JZOJ2020年8月8日提高组T1 奶牛编号
[NOIP2012模拟8.7]JZOJ2020年8月8日提高组T1 奶牛编号 题目 作为一个神秘的电脑高手,Farmer John 用二进制数字标识他的奶牛. 然而,他有点迷信,标识奶牛用的二进制数字 ...
- moviepy音视频开发:audio_loop实现音频内容循环重复
☞ ░ 前往老猿Python博文目录 ░ 概述 moviepy的audio_loop函数用于将音频剪辑内容循环一定次数,返回值是原剪辑内容重复指定次数对应的剪辑. 调用语法: audio_loop(a ...
- 第8.24节 使用__subclasses__查看类的直接子类
在<第8.9节 Python类中内置的__bases__属性>中介绍了__bases__这个类的特殊变量可以查看类的直接父类,而__subclasses__() 方法的使用则与__base ...
- 关于建立老猿Python研学群的公告
3个月前有人建议老猿建立一个Python学习交流群,老猿自己学习Python也没多久,因此没有考虑这个事情,最近又有几个朋友在请我建立这样一个群,犹豫再三,老猿决定还是答应了,因为最近关注老猿Pyth ...
- Kubernetes的Local Persistent Volumes使用小记
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- 手动 jq 触发 动态的 layui select change 事件
var s= $('#province').val(); //先获取 默认选中的第一个 option 的值 ( value) var select = 'dd[lay-value=' + s ...
- 【学习笔记】动态 dp 入门简易教程
序列 dp 引入:最大子段和 给定一个数列 \(a_1, a_2, \cdots, a_n\)(可能为负),求 \(\max\limits_{1\le l\le r\le n}\left\{\sum_ ...
- CF500G / T148321 走廊巡逻
题目链接 这题是 Codeforces Goodbye 2014 的最后一题 CF500G,只是去掉了 \(u \not= x, v \not = v\) 的条件. 官方题解感觉有很多东西说的迷迷瞪瞪 ...