kafka rebalance解决方案 -incremental cooperative协议和static membership功能
apache kafka的重平衡(rebalance),一直以来都为人诟病。因为重平衡过程会触发stop-the-world(STW),此时对应topic的资源都会处于不可用的状态。小规模的集群还好,如果是大规模的集群,比如几百个节点的consumer或kafka connect等,那么重平衡就是一场灾难。所以我们要尽可能避免重平衡,在之前的文章中也有介绍过这点,有关重平衡的基础内容可以参阅:
在kafka2.4的时候,社区推出两个新feature来解决重平衡过程中STW的问题。
- Incremental Rebalance Protocol(以下简称cooperative协议):改进了eager协议(即旧重平衡协议)的问题,避免STW的发生,具体怎么避免,后面介绍
- static membership:避免重起或暂时离开的消费者触发重平衡
本篇接下来主要介绍这两点,另外注意,这两个功能都是kafka2.4推出的,如果想尝鲜建议升级到kafka2.4,升级方案参见官网:Upgrading to 2.4.0 from any version 0.8.x through 2.3.x。
apache kafak2.4 incremental cooperative rebalancing协议
背景
负载均衡,基本是分布式系统中必不可少一个功能,apache kafka也不例外。为了让消费数据这个过程在kafka集群中尽可能地均衡,kafka推出了重平衡的功能,重平衡能够帮助kafka客户端(consumer client,kafka connect,kafka stream)尽可能实现负载均衡。
但是在kafka2.3之前,重平衡各种分配策略基本都是基于eager协议的(包括RangeAssignor,RoundRobinAssignor等,这部分内容最前面给出的文章有介绍),也就是我们以前熟知的kafka重平衡。eager协议重平衡的细节,推荐看极客时间胡夕大佬的文章,讲得很详细,具体的链接就不放了,也可以直接搜kafak重平衡流程解析。
值得一提的是,此前kafka就有推出一个重平衡的新分配策略,StickyAssignor粘性分配策略,主要作用是保证客户端,比如consumer消费者在重平衡后能够维持原本的分配方案,可惜的是这个分配策略依旧是在eager协议的框架之下,重平衡仍然需要每个consumer都先放弃当前持有的资源(分区)。
在2.x的时候,社区就意识到需要对现有的rebalance作出改变。所以在kafka2.3版本首先在kafka connect应用cooperative协议,然后在kafka2.4的时候也在consumer client添加了该协议的支持。
incremental cooperative rebalancing协议解析
接下来我们介绍cooperative协议和eager协议的具体区别。一句话介绍,cooperative协议将一次全局重平衡,改成每次小规模重平衡,直至最终收敛平衡的过程。
这里我们主要针对一种场景举个例子,来对比两种协议的区别。
假设有这样一种场景,一个topic有三个分区,分别是p1,p2,p3。有两个消费者c1,c2在消费这三个分区,{c1 -> p1, p2},{c2 -> p3}。
当然这样说不平衡的,所以加入一个消费者c3,此时触发重平衡。我们先列出在eager协议的框架下会执行的大致步骤,然后再列出cooperative发生的步骤,以做比对。
eager 协议版本
先说下各个名词:
- group coordinator:重平衡协调器,负责处理重平衡生命周期中的各种事件
- hearbeat:consumer和broker的心跳,重平衡时会通过这个心跳通知信息
- join group request:consumer客户端加入组的请求
- sync group request:重平衡后期,group coordinator向consumer客户端发送的分配方案
如果在 eager 版本中,会发生如下事情。
- 最开始的时候,c1 c2 各自发送hearbeat心跳信息给到group coordinator(负责重平衡的协调器)
- 这时候group coordinator收到一个join group的request请求,group coordinator知道有新成员加入组了
- 在下一个心跳中group coordinator 通知 c1 和 c2 ,准备rebalance
- c1 和 c2 放弃(revoke)各自的partition,然后发送joingroup的request给group coordinator
- group coordinator处理好分配方案(交给leader consumer分配的),发送sync group request给 c1 c2 c3,附带新的分配方案
- c1 c2 c3接收到分配方案后,重新开始消费
用一张图表示如下:
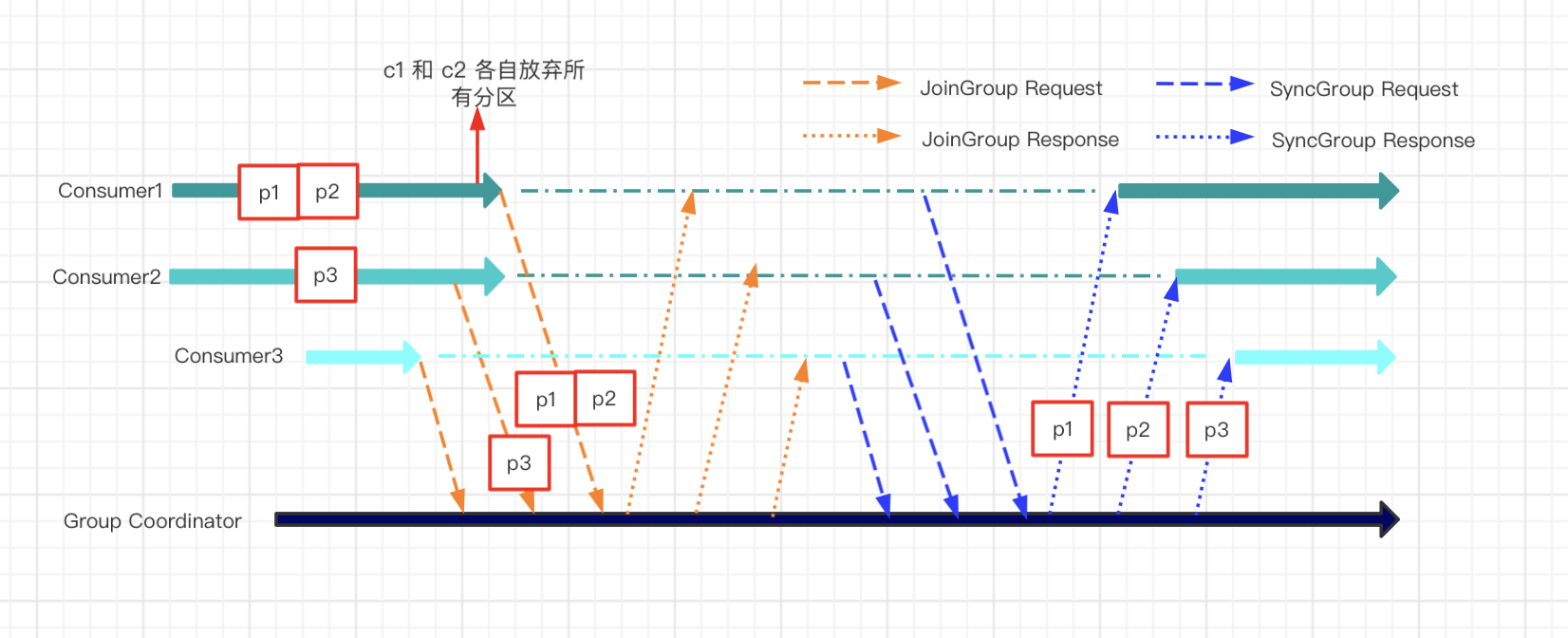
这里省略了一些细节,不过整体上应该会更方便理解这个过程。接下来再看看cooperative协议会怎么处理。
到了cooperative协议就会变成这样:
cooperative rebalancing protocol 版本
如果在cooperative版本中,会发生如下事情。
- 最开始的时候c1 c2各自发送hearbeat心跳信息给到group coordinator
- 这时候group coordinator收到一个join group的request请求,group coordinator知道有新成员加入组了
- 在下一个心跳中 group coordinator 通知 c1 和 c2 ,准备 rebalance,前面几部分是一样的
- c1 和 c2发送joingroup的request给group coordinator,但不需要revoke其所拥有的partition,而是将其拥有的分区编码后一并发送给group coordinator,即 {c1->p1, p2},{c2->p3}
- group coordinator 从元数据中获取当前的分区信息(这个称为assigned-partitions),再从c1 c2 的joingroup request中获取分配的分区(这个称为 owned-partitions),通过assigned-partitions和owned-partitions知晓当前分配情况,决定取消c1一个分区p2的消费权,然后发送sync group request({c1->p1},{c2->p3})给c1 c2,让它们继续消费p1 p2
- c1 c2 接收到分配方案后,重新开始消费,一次 rebalance 完成,当然这时候p2处于无人消费状态
- 再次触发rebalance,重复上述流程,不过这次的目的是把p2分配给c3(通过assigned-partitions和owned-partitions获取分区分配状态)
同样用一张图表示如下:
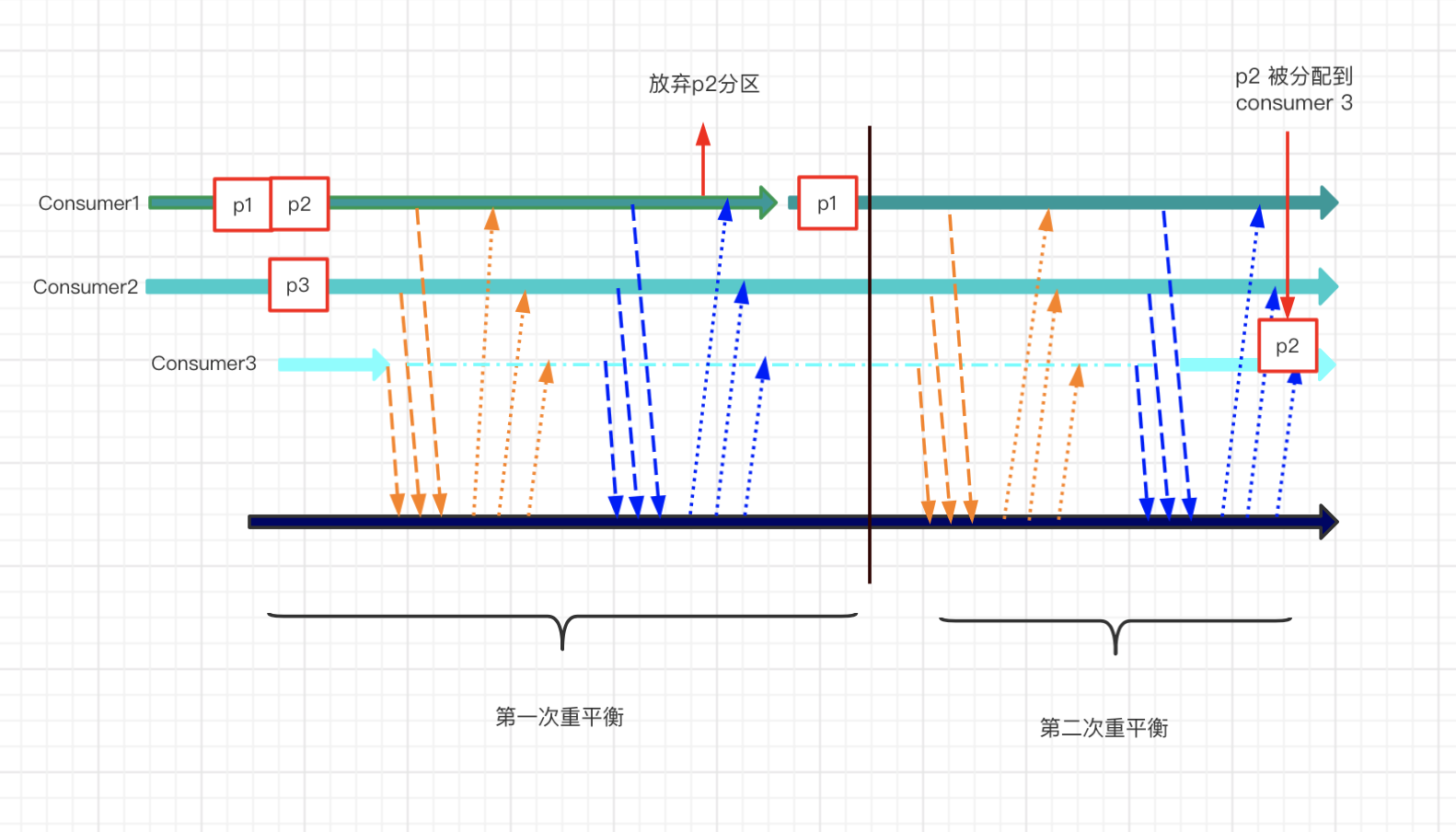
cooperative协议版重平衡的一个核心,是assigned-partitions和owned-partitions,group coordinator通过这两者,可以保存和获取分区的消费状态,以便进行多次重平衡并达到最终的均衡状态。
除了消费者崩溃离场的场景,其他场景也是类似的思路。具体重平衡算法相对比较复杂,这里留给感兴趣的同学自行探索:KIP-429: Kafka Consumer Incremental Rebalance Protocol。
apache kafka2.4 static membership功能
我们知道,当前重平衡发生的条件有三个:
- 成员数量发生变化,即有新成员加入或现有成员离组(包括主动离组和崩溃被动离组)
- 订阅主题数量发生变化
- 订阅主题分区数量发生变化
其中成员加入或成员离组是最常见的触发重平衡的情况。新成员加入这个场景必然发生重平衡,没办法优化(针对初始化多个消费者的情况有其他优化,即延迟进行重平衡),但消费者崩溃离组却可以优化。因为一个消费者崩溃离组通常不会影响到其他{partition - consumer}的分配情况。
因此在 kafka 2.3~2.4 推出一项优化,即此次介绍的Static Membership功能和一个consumer端的配置参数 group.instance.id。一旦配置了该参数,成员将自动成为静态成员,否则的话和以前一样依然被视为是动态成员。
静态成员的好处在于,其静态成员ID值是不变的,因此之前分配给该成员的所有分区也是不变的。即假设一个成员挂掉,在没有超时前静态成员重启回来是不会触发 Rebalance 的(超时时间为session.timeout.ms,默认10 sec)。在静态成员挂掉这段时间,broker会一直为该消费者保存状态(offset),直到超时或静态成员重新连接。
如果使用了 static membership 功能后,触发 rebalance 的条件如下:
- 新成员加入组:这个条件依然不变。当有新成员加入时肯定会触发 Rebalance 重新分配分区
- Leader 成员重新加入组:比如主题分配方案发生变更
- 现有成员离组时间超过了
session.timeout.ms超时时间:即使它是静态成员,Coordinator 也不会无限期地等待它。一旦超过了 session 超时时间依然会触发 Rebalance - Coordinator 接收到 LeaveGroup 请求:成员主动通知 Coordinator 永久离组。
所以使用static membership的两个条件是:
- consumer客户端添加配置:props.put("group.instance.id", "con1");
- 设置
session.timeout.ms为一个合理的时间,这个参数受限于group.min.session.timeout.ms(6 sec)和group.max.session.timeout.ms(30 min),即大小不能超过这个上下限。但是调的过大也可能造成broker不断等待挂掉的消费者客户端的情况,个人建议根据使用场景,设置合理的参数。
以上~
参考:
Apache Kafka Rebalance Protocol, or the magic behind your streams applications
Incremental Cooperative Rebalancing in Apache Kafka: Why Stop the World When You Can Change It?
From Eager to Smarter in Apache Kafka Consumer Rebalances
KIP-429: Kafka Consumer Incremental Rebalance Protocol
Incremental Cooperative Rebalancing: Support and Policies
KIP-345: Introduce static membership protocol to reduce consumer rebalances
kafka rebalance解决方案 -incremental cooperative协议和static membership功能的更多相关文章
- ZAB协议和Paxos算法
前言在上一篇文章Paxos算法浅析中主要介绍了Paxos一致性算法应用的场景,以及对协议本身的介绍:Google Chubby是一个分布式锁服务,其底层一致性实现就是以Paxos算法为基础的:但这篇文 ...
- (1)基于tcp协议的编程模型 (2)tcp协议和udp协议的比较 (3)基于udp协议的编程模型 (4)反射机制
1.基于tcp协议的编程模型(重中之重)1.1 编程模型服务器: (1)创建ServerSocket类型的对象,并提供端口号: (2)等待客户端的连接请求,调用accept()方法: (3)使用输入输 ...
- Java基础之UDP协议和TCP协议简介及简单案例的实现
写在前面的废话:马上要找工作了,做了一年的.net ,到要找工作了发现没几个大公司招聘.net工程师,真是坑爹呀.哎,java就java吧,咱从头开始学呗,啥也不说了,玩命撸吧,我真可怜啊. 摘要: ...
- RabbitMQ MQTT协议和AMQP协议
RabbitMQ MQTT协议和AMQP协议 1 序言... 1 1.1 RabbitMq结构... 1 1.2 RabbitMq消息接收... 4 1.3 Ex ...
- python语法基础-网络编程-TCP协议和UDP协议
############### 网络编程 ############## """ 网络编程 学习了Python基础之后,包括函数,面向对象等,你就可以开发了,你 ...
- 网络协议学习笔记(八)DNS协议和HttpDNS协议
概述 上一篇主要讲解了流媒体协议和p2p协议,现在我给大家讲解一下关于DNS和HttpDNS的相关知识. DNS协议:网络世界的地址簿 在网络世界,也是这样的.你肯定记得住网站的名称,但是很难记住网站 ...
- 页面解耦—— 统跳协议和Rewrite引擎
原文: http://pingguohe.net/2015/11/24/Navigator-and-Rewrite.html 解耦神器 —— 统跳协议和Rewrite引擎 Nov 24, 2015 • ...
- http协议和web应用有状态和无状态浅析
http协议和web应用有状态和无状态浅析 (2013-10-14 10:38:06) 转载▼ 标签: it 我们通常说的web应用程序的无状态性的含义是什么呢? 直观的说,“每次的请求都是独立的 ...
- 在线聊天室的实现(1)--websocket协议和javascript版的api
前言: 大家刚学socket编程的时候, 往往以聊天室作为学习DEMO, 实现简单且上手容易. 该Demo被不同语言实现和演绎, 网上相关资料亦不胜枚举. 以至于很多技术书籍在讲解网络相关的编程时, ...
随机推荐
- pytest测试框架入门
安装pytest 命令行输入: pip install -U pytest 检查是否安装了正确的版本: λ pytest --version This is pytest version 5.3.5, ...
- NOIP2020 游记
为了防止被禁赛三年,这里说明一下,本篇游记是提前开坑的. 10.9 上午模拟赛,下午初赛改成了全天初赛. 但还是想了会儿题,写了两道水题找找信心吧,毕竟前几天挂分挺严重的. 机房还是挺乱的,甚至连自己 ...
- Java基础教程——抽象类
抽象类 抽象类是介于普通类(class)和接口(interface)之间的一种特殊类. 接口的方法都不实现,类的方法都必须实现,抽象类里的方法可以实现,可以不实现. Java 8之后接口中可以实现方法 ...
- dubbo 扩展点里自动包装
在看protrocol扩展点时,发现很费解的一点:当前invoker的url是register协议,在export的时候都会从qos->lister->filer这3个包装类开始,看了一下 ...
- @RequestParam,@RequestBody,@PathVariable注解还分不清吗?
前言 在使用 SpringMVC 开发时,经常遇到前端传递的各种参数,比如 form 表单,JSON 数据,String[] 数组,再或者是最常见的 String 字符串等等,总之大部分场景都是在标题 ...
- django+channels+dephne实现websockrt部署
当你的django项目中使用channels增加了websocket功能的时候,在使用runserver命令启动时,既可以访问http请求,又可以访问websocket请求.但是当你使用uWSGI+n ...
- 洛谷P3906 Hoof Paper, Scissor (记忆化搜索)
这道题问的是石头剪刀布的的出题问题 首先不难看出这是个dp题 其次这道题的状态也很好确定,之前输赢与之后无关,确定三个状态:当前位置,当前手势,当前剩余次数,所以对于剪刀,要么出石头+1分用一次机会, ...
- 【Azure Redis 缓存 Azure Cache For Redis】Azure Redis由低级别(C)升级到高级别(P)的步骤和注意事项, 及对用户现有应用的潜在影响,是否需要停机时间窗口,以及这个时间窗口需要多少的预估问题
问题描述 由于Azure Redis的性能在不同级别表现不同,当需要升级/缩放Redis的时候,从使用者的角度,需要知道有那些步骤? 注意事项? 潜在影响?停机事件窗口? 升级预估时间? 解决方案 从 ...
- 函数与函数式编程(生成器 && 列表解析 && map函数 && filter函数)-(四)
在学习python的过程中,无意中看到了函数式编程.在了解的过程中,明白了函数与函数式的区别,函数式编程的几种方式. 函数定义:函数是逻辑结构化和过程化的一种编程方法. 过程定义:过程就是简单特殊没有 ...
- Jquery返回顶部插件
自己jquery开发的返回顶部,当时只为了自己用一下,为了方便,修改成了插件... 自己的博客现在用的也是这个插件..使用方便!! <!DOCTYPE html> <html> ...