python线性回归
一.理论基础
1.回归公式
对于单元的线性回归,我们有:f(x) = kx + b 的方程(k代表权重,b代表截距)。
对于多元线性回归,我们有:
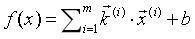
或者为了简化,干脆将b视为k0·x0,,其中k0为1,于是我们就有:
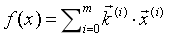
2.损失函数

3.误差衡量
MSE,RMSE,MAE越接近于0越好,R方越接近于1越好。
MSE平均平方误差(mean squared error)
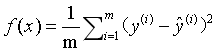
RMSE,是MSE的开根号
MAE平均绝对值误差(mean absolute error)
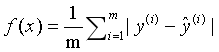
R方
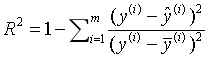
其中y_hat是预测值。
二.代码实现
本次,我们将用iris数据集实现单元线性回归的机器学习,使用boston数据集实现多元线性回归的机器学习。在python中,单元线性回归与多元线性回归的操作完全一样,这里只是为了演示而将其一分为二。
1.鸢尾花花瓣长度与宽度的线性回归
# 导入鸢尾花数据集
from sklearn.datasets import load_iris
# 导入用于分割训练集和测试集的类
from sklearn.model_selection import train_test_split
# 导入线性回归类
from sklearn.linear_model import LinearRegression
import numpy as np
iris = load_iris()
'''
iris数据集的第三列是鸢尾花长度,第四列是鸢尾花宽度
x和y就是自变量和因变量
reshape(-1,1)就是将iris.data[:,3]由一维数组转置为二维数组,
以便于与iris.data[:,2]进行运算
'''
x,y = iris.data[:,2].reshape(-1,1),iris.data[:,3]
lr = LinearRegression()
'''
train_test_split可以进行训练集与测试集的拆分,
返回值分别为训练集的x,测试集的x,训练集的y,测试集的y,
分别赋值给x_train,x_test,y_train,y_test,
test_size:测试集占比
random_state:选定随机种子
'''
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size = 0.25,random_state = 0)
# 利用训练集进行机器学习
lr.fit(x_train,y_train)
# 权重为lr.coef_
# 截距为lr.intercept_
# 运用训练出来的模型得出测试集的预测值
y_hat = lr.predict(x_test)
# 比较测试集的y值与预测出来的y值的前5条数据
print(y_train[:5])
print(y_hat[:5])
# 评价模型的准确性,用测试集来评价
# 导入分别用于求MSE,MAE和R方的包
from sklearn.metrics import mean_squared_error,mean_absolute_error,r2_score
# 求解MSE
print('MSE:',mean_squared_error(y_test,y_hat))
# 求解RMSE,是MSE的开根号
print('RMSE:',np.sqrt(mean_squared_error(y_test,y_hat))
# 求解MAE
print('MAE:',mean_absolute_error(y_test,y_hat))
# 求解R方,有两种方法,注意lr.score的参数是x_test,y_test
print('R方:',r2_score(y_test,y_hat))
print('R方:',lr.score(x_test,y_test))
# 导入matplotlib模块,进行可视化
from matplotlib import pyplot as plt
plt.rcParams['font.family'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.size'] = 15
plt.figure(figsize = (20,8))
# 训练集散点图
plt.scatter(x_train,y_train,color = 'green',marker = 'o',label = '训练集')
# 测试集散点图
plt.scatter(x_test,y_test,color = 'orange',marker = 'o',label = '测试集')
# 回归线
plt.plot(x,lr.predict(x),'r-')
plt.legend()
plt.xlabel('花瓣长度')
plt.ylabel('花瓣宽度')就这样画出了一张很丑的图,如果想画更精美的图或者其他方面的比较,各位读者不妨自己去试一试吧。
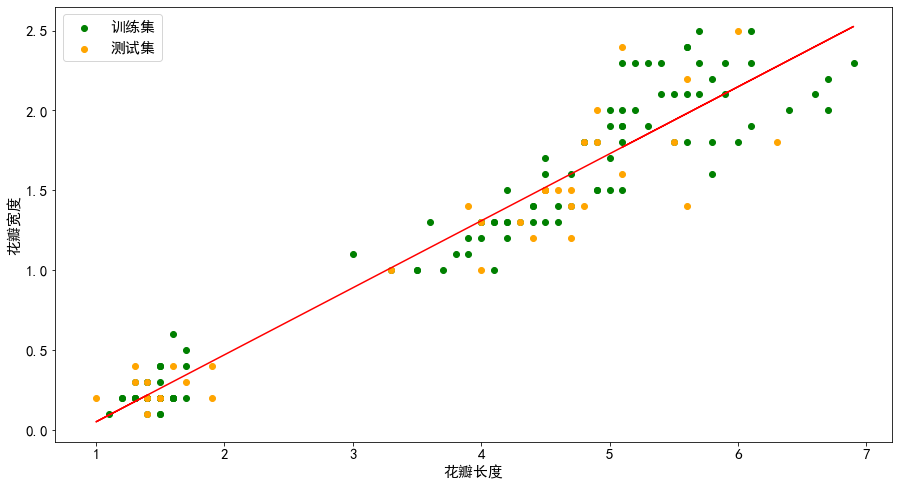
刚刚我们做了对鸢尾花花瓣长度和宽度的线性回归,探讨长度与宽度的关系,探究鸢尾花的花瓣宽度受长度变化的趋势是怎么样的。但是在现实生活当中的数据是十分复杂的,像这种单因素影响的事物是比较少的,我们需要引入多元线性回归来对多个因素的权重进行分配,从而与复杂事物相符合。
2.boston房价预测(多元线性回归)
呐,boston数据集的介绍在这里了,我就不详细介绍了
现在,我们要探讨boston当中每一个因素对房价的影响有多大,这就是一个多因素影响的典型例子。
import pandas as pd
import numpy as np
from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
boston = load_boston()
# lr继承LinearRegression类
lr = LinearRegression()
# 因为boston.data本身就是二维数组,所以无需转置,boston.target是房价
x,y = boston.data,boston.target
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size = 0.15,random_state = 0)
lr.fit(x_train,y_train)
# 显示权重,因为有很多因素,所以权重也有很多个
print(lr.coef_)
# 显示截距
print(lr.intercept_)
y_hat = lr.predict(x_test)
# 模型评判仍然是用那几个包,这里不再赘述。结果如下,可以发现每一个因素都有相应的权重。
[-1.24536078e-01 4.06088227e-02 5.56827689e-03 2.17301021e+00
-1.72015611e+01 4.02315239e+00 -4.62527553e-03 -1.39681074e+00
2.84078987e-01 -1.17305066e-02 -1.06970964e+00 1.02237522e-02
-4.54390752e-01]
36.09267761760974本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理
想要获取更多Python学习资料可以加
QQ:2955637827私聊
或加Q群630390733
大家一起来学习讨论吧!
python线性回归的更多相关文章
- Python 线性回归(Linear Regression) 基本理解
背景 学习 Linear Regression in Python – Real Python,对线性回归理论上的理解做个回顾,文章是前天读完,今天凭着记忆和理解写一遍,再回温更正. 线性回归(Lin ...
- python 线性回归示例
说明:此文的第一部分参考了这里 用python进行线性回归分析非常方便,有现成的库可以使用比如:numpy.linalog.lstsq例子.scipy.stats.linregress例子.panda ...
- Python 线性回归(Linear Regression) - 到底什么是 regression?
背景 学习 Linear Regression in Python – Real Python,对 regression 一词比较疑惑. 这个 linear Regression 中的 Regress ...
- Python - 线性回归(Linear Regression) 的 Python 实现
背景 学习 Linear Regression in Python – Real Python,前面几篇文章分别讲了"regression怎么理解","线性回归怎么理解& ...
- 机器学习之路: python线性回归 过拟合 L1与L2正则化
git:https://github.com/linyi0604/MachineLearning 正则化: 提高模型在未知数据上的泛化能力 避免参数过拟合正则化常用的方法: 在目标函数上增加对参数的惩 ...
- 机器学习之路: python 线性回归LinearRegression, 随机参数回归SGDRegressor 预测波士顿房价
python3学习使用api 线性回归,和 随机参数回归 git: https://github.com/linyi0604/MachineLearning from sklearn.datasets ...
- 机器学习之路:python线性回归分类器 LogisticRegression SGDClassifier 进行良恶性肿瘤分类预测
使用python3 学习了线性回归的api 分别使用逻辑斯蒂回归 和 随机参数估计回归 对良恶性肿瘤进行预测 我把数据集下载到了本地,可以来我的git下载源代码和数据集:https://gith ...
- Python线性回归算法【解析解,sklearn机器学习库】
一.概述 参考博客:https://www.cnblogs.com/yszd/p/8529704.html 二.代码实现[解析解] import numpy as np import matplotl ...
- ml的线性回归应用(python语言)
线性回归的模型是:y=theta0*x+theta1 其中theta0,theta1是我们希望得到的系数和截距. 下面是代码实例: 1. 用自定义数据来看看格式: # -*- coding:utf ...
随机推荐
- JS指定音频audio在某个时间点进行播放,获取当前音频audio的长度,音频时长格式转化
前言: 今天接到一个需求,需要获取某个.mp3音频文件的时间长度和指定音频audio在某个时间点进行播放(比如说这个视频有4分钟,我要让它默认从第2秒的时候开始播放),这里当然想到了H5中的audio ...
- LCCUP 2020 秋季编程大赛 补题
果然是力扣杯,难度较于平时周赛提高了不少,个人感觉最后两题并不太容易QAQ LCP 18.早餐组合 #二分思想 题目链接 题意 你获得了每种主食的价格,及每种饮料的价格,你需要选择一份主食和一份饮料, ...
- 精尽MyBatis源码分析 - Spring-Boot-Starter 源码分析
该系列文档是本人在学习 Mybatis 的源码过程中总结下来的,可能对读者不太友好,请结合我的源码注释(Mybatis源码分析 GitHub 地址.Mybatis-Spring 源码分析 GitHub ...
- C++之父接受采访:对 C++ 成功的关键和发展历程进行了回顾
C++ 的起源可以追溯到 40 年前,但它仍然是当今使用最广泛的编程语言之一. 到 2020 年 9 月为止,C++ 是仅次于 C 语言.Java 和 Python,位于全球第四的编程语言.根据最新的 ...
- 关于C语言编程的高效学习方法,首要任务是掌握高效编程,其次乃代码优化!
在本篇文章中,我收集了很多经验和方法.应用这些经验和方法,可以帮助我们从执行速度和内存使用等方面来优化C语言代码. 简介 在最近的一个项目中,我们需要开发一个运行在移动设备上但不保证图像高质量的轻量级 ...
- vue中,模拟锚点定位,实现滚动动画效果
平时我们利用锚点进行页面内的快速瞬移,画面跳转生硬,观感很差. 在VUE中,如何快速的实现锚点效果,并且还让它拥有滚动的动画效果呢. 其实两行代码就能解决问题 1 <a @click=" ...
- Golang自学系列
为什么会有这个系列? 因为我要往架构方向靠拢啊. 关于架构,其实架构的书我看了<架构整洁之道>,也有<实现驱动领域设计>.但是我感觉明显还不够,所以我在极客时间买了一个架构相关 ...
- 冲刺随笔——Day_Ten
这个作业属于哪个课程 软件工程 (福州大学至诚学院 - 计算机工程系) 这个作业要求在哪里 团队作业第五次--Alpha冲刺 这个作业的目标 团队进行Alpha冲刺 作业正文 正文 其他参考文献 无 ...
- springmvc<三> 异常解析链与视图解析链
1.1.7. Exceptions - 如果异常被Controller抛出,则DispatchServlet委托异常解析链来处理异常并提供处理方案(通常是一个错误的响应) spri ...
- PyQt(Python+Qt)学习随笔:QTreeWidget中获取指定位置项的itemAt方法
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 QTreeWidget的itemAt方法通过视口内的坐标点获取对应坐标位置的项,相关调用方法如下: ...