OpenCV图像处理中的“机器学习"技术的使用
Opencv支持的机器学习算法(参考《学习OpenCV4》)
| 算法名称 | 描述 |
| Mahalanobis | 通过除以协方差来对数据空间进行变换,由此得到一个标志着空间拉伸程度的距离度量。如果协方差矩阵是单位矩阵,那么这个度量等价于欧氏距离[Mahalanobis36]。 |
| K-均值算法 | 这是一种非监督的聚类方法,用k个聚类中心表示数据的分布,k的大小由用户定义。该方法与期望最大化算法(expectation maximization)的区别在于k-均值的中心不是符合高斯分布的。而由于每个聚类中心都竞争着去俘获与之距离较近的点,所以聚类的结果更像是肥皂泡,聚类区域经常被用作稀疏直方图的bin,用来描述数据。该方法由Steinhaus [Steinhaus56]提出,由Lloyd [Lloyd57]推广。 |
| 正态/朴素贝叶斯 | 这是一个生成式的分类器。它假设特征符合高斯分布且在统计学上服从独立同分布。但是这个过于苛刻的假设在很多情况下是不能满足的。因此,它又被称为“朴素”贝叶斯分类器。尽管如此,在许多情况下,这个方法的效果却出奇的好。该方法最早出自[Maron61; Minsky61] |
| 决策树 | 这是一个判别分类器。该树在当前节点通过寻找数据特征和一个阈值来实现数据到不同类别的最优划分。处理流程是不断将数据进行划分,然后下降到树的左侧子节点或者右侧子节点。虽然该算法的性能不是最好的,但往往是测试时的首选,因为它运行速度快,性能好。[Breiman84] |
| 期望最大化算法(EM) | 这是一种用于聚类的无监督生成算法。它会用N维高斯分布去拟合数据,其中N的大小是由用户自己定义的。这样仅仅用很少的几个参数(方差和均值)就可以表示一个较为复杂的数据分布。该方法经常用于分割,它与k-均值算法的比较见文献[Dempster77]。 |
| Boosting | 它是由一组判别分类器组成。最终的决策是由组成它的各个分类器的加权组合来决定。在训练中,逐个训练子分类器。且每个子分类器都是弱分类器(性能上只是优于随机选择)。这些弱分类器由单变量决策树构成,被称为“桩(stumps)”。在训练中,决策桩(decision stump)不仅从数据中学习分类决策而且根据预测精度学习“投票”的权重。当训练下一个分类器的时候,数据样本的权重会被重新分配。使之能够给予分错的数据更多的注意力。训练过程不停地执行,直到总错误(加权组合所有决策树组成的分类器产生的错误)低于某个已经设置好的阈值。为了达到好的效果,这个方法通常需要很大量训练的训练数据[Freund97]。 |
| 随机森林 | 它是由许多决策树组成的“森林”,每个决策树向下递归以获取最大深度。在学习过程中,每棵树的每个节点只从特征数据的一个随机子集中选择。这保证了每棵树是统计意义上不相关的分类器。在识别过程中,将每棵树的结果进行投票来确定最终结果,每棵树的权重相同。这个分类器方法经常很有效,而且对每棵树的输出进行平均,可以处理回归问题[Ho95; Criminisi13; Breiman01]。 |
| K近邻 | K近邻可能是最简单的分类器。训练数据跟类别标签存放在一起,离测试数据最近的(欧氏距离最近)K个样本进行投票,确定测试数据的分类结果。该方法通常比较有效,但是速度比较慢且对内存需求比较大[Fix51],详见FLANN 入口 |
| 快速近似最近邻算法(FLANN)a | Opencv包含了完整的快速近似最近邻算法函数库,该库由Marius Muja开发,可实现K近邻的快速近似和匹配[Muja09]。 |
| 支持向量机(SVM) | 它可以进行分类,也可以进行回归。该算法需要定义一个高维空间中任两点的距离函数。(将数据投影到高维空间会使数据更容易地线性可分。)该算法可以学习一个分类超平面,用来在高维空间里实现最优分类器。当数据有限的时候,该算法可以获得非常好的性能,而boosting和随机森林只能在拥有大量训练数据b时才有好的效果。 |
| 人脸识别/级联分类器 | 这个物体检测算法巧妙地使用了boosting算法。OpenCV提供了正面人脸检测的检测器,它的检测效果非常好。你可以使用OpenCV提供的训练算法,也可以使用这个分类器提取你自己想要的特征或使用其他的特征,使之能够检测其他物体。该算法非常擅长检测特定视角的刚性物体。这个分类器也俗称“Viola-Jones分类器”,这是以它发明者的名字命名的(Viola04)。 |
| Waldboost | 它是Viola 算法的衍生算法(参见上一条),Waldboost是一个非常快的目标检测器,它在一系列任务中的表现都要优于传统的级联分类器 (Sochman05)。它存在于在…/ opencv_contrib /模块中。 |
| 隐变量支持向量机 | 隐变量支持向量机是一个局部模型。通过识别目标的各个独立部分并学习一个模型去发现这些部分之间联系来识别复杂目标[Felzenszwalb10]。 |
| 词袋模型 | 词袋模型是在文档分类和视觉图像分类中都有大量应用的技术。该算法功能强大,因为它不仅可以用来b识别单个目标,还可以用来识别场景和环境。 |
#include "pch.h"
#include <iostream>
#include <string>
#include <cstring>
#include <cstdlib>
#include <vector>
#include "gocvhelper.h"
using namespace std;
using namespace cv;
//解决具体的“判定当前图片中是否存在车牌”问题,使用SVM方法。
typedef enum {
kForward = 1, // correspond to "has plate"
kInverse = 0 // correspond to "no plate"
} SvmLabel;
typedef struct {
std::string file;
SvmLabel label;
} TrainItem;
std::vector<TrainItem> train_file_list_;
std::vector<TrainItem> test_file_list_;
std::vector<std::string> getFiles(const std::string &folder,const bool all = true ) {
std::vector<std::string> files;
std::list<std::string> subfolders;
subfolders.push_back(folder);
while (!subfolders.empty()) {
std::string current_folder(subfolders.back());
if (*(current_folder.end() - 1) != '/') {
current_folder.append("/*");
}
else {
current_folder.append("*");
}
subfolders.pop_back();
struct _finddata_t file_info;
auto file_handler = _findfirst(current_folder.c_str(), &file_info);
while (file_handler != -1) {
if (all &&
(!strcmp(file_info.name, ".") || !strcmp(file_info.name, ".."))) {
if (_findnext(file_handler, &file_info) != 0) break;
continue;
}
if (file_info.attrib & _A_SUBDIR) {
// it's a sub folder
if (all) {
// will search sub folder
std::string folder(current_folder);
folder.pop_back();
folder.append(file_info.name);
subfolders.push_back(folder.c_str());
}
}
else {
// it's a file
std::string file_path;
// current_folder.pop_back();
file_path.assign(current_folder.c_str()).pop_back();
file_path.append(file_info.name);
files.push_back(file_path);
}
if (_findnext(file_handler, &file_info) != 0) break;
} // while
_findclose(file_handler);
}
return files;
}
const char* plates_folder_ = "E:/代码资源/EasyPR/resources/train/svm";
void prepare() {
srand(unsigned(time(NULL)));
char buffer[260] = { 0 };
sprintf_s(buffer, "%s/has/train", plates_folder_);
auto has_file_train_list = getFiles(buffer);
std::random_shuffle(has_file_train_list.begin(), has_file_train_list.end());
sprintf_s(buffer, "%s/has/test", plates_folder_);
auto has_file_test_list = getFiles(buffer);
std::random_shuffle(has_file_test_list.begin(), has_file_test_list.end());
sprintf_s(buffer, "%s/no/train", plates_folder_);
auto no_file_train_list = getFiles(buffer);
std::random_shuffle(no_file_train_list.begin(), no_file_train_list.end());
sprintf_s(buffer, "%s/no/test", plates_folder_);
auto no_file_test_list = getFiles(buffer);
std::random_shuffle(no_file_test_list.begin(), no_file_test_list.end());
fprintf(stdout, ">> Collecting train data...\n");
for (auto file : has_file_train_list)
train_file_list_.push_back({ file, kForward });
for (auto file : no_file_train_list)
train_file_list_.push_back({ file, kInverse });
fprintf(stdout, ">> Collecting test data...\n");
for (auto file : has_file_test_list)
test_file_list_.push_back({ file, kForward });
for (auto file : no_file_test_list)
test_file_list_.push_back({ file, kInverse });
}
//特征提取
float countOfBigValue(Mat &mat, int iValue) {
float iCount = 0.0;
if (mat.rows > 1) {
for (int i = 0; i < mat.rows; ++i) {
if (mat.data[i * mat.step[0]] > iValue) {
iCount += 1.0;
}
}
return iCount;
}
else {
for (int i = 0; i < mat.cols; ++i) {
if (mat.data[i] > iValue) {
iCount += 1.0;
}
}
return iCount;
}
}
Mat ProjectedHistogram(Mat img, int t, int threshold) {
int sz = (t) ? img.rows : img.cols;
Mat mhist = Mat::zeros(1, sz, CV_32F);
for (int j = 0; j < sz; j++) {
Mat data = (t) ? img.row(j) : img.col(j);
mhist.at<float>(j) = countOfBigValue(data, threshold);
}
// Normalize histogram
double min, max;
minMaxLoc(mhist, &min, &max);
if (max > 0)
mhist.convertTo(mhist, -1, 1.0f / max, 0);
return mhist;
}
Mat getHistogram(Mat in) {
const int VERTICAL = 0;
const int HORIZONTAL = 1;
// Histogram features
Mat vhist = ProjectedHistogram(in, VERTICAL,20);
Mat hhist = ProjectedHistogram(in, HORIZONTAL,20);
// Last 10 is the number of moments components
int numCols = vhist.cols + hhist.cols;
Mat out = Mat::zeros(1, numCols, CV_32F);
int j = 0;
for (int i = 0; i < vhist.cols; i++) {
out.at<float>(j) = vhist.at<float>(i);
j++;
}
for (int i = 0; i < hhist.cols; i++) {
out.at<float>(j) = hhist.at<float>(i);
j++;
}
return out;
}
void getHistogramFeatures(const Mat& image, Mat& features) {
Mat grayImage;
cvtColor(image, grayImage, cv::COLOR_RGB2GRAY);
//grayImage = histeq(grayImage);
Mat img_threshold;
threshold(grayImage, img_threshold, 0, 255, cv::THRESH_OTSU + cv::THRESH_BINARY);
//Mat img_threshold = grayImage.clone();
//spatial_ostu(img_threshold, 8, 2, getPlateType(image, false));
features = getHistogram(img_threshold);
}
void getColorFeatures(const Mat& src, Mat& features) {
Mat src_hsv;
//grayImage = histeq(grayImage);
cvtColor(src, src_hsv, cv::COLOR_BGR2HSV);
int channels = src_hsv.channels();
int nRows = src_hsv.rows;
// consider multi channel image
int nCols = src_hsv.cols * channels;
if (src_hsv.isContinuous()) {
nCols *= nRows;
nRows = 1;
}
const int sz = 180;
int h[sz] = { 0 };
uchar* p;
for (int i = 0; i < nRows; ++i) {
p = src_hsv.ptr<uchar>(i);
for (int j = 0; j < nCols; j += 3) {
int H = int(p[j]); // 0-180
if (H > sz - 1) H = sz - 1;
if (H < 0) H = 0;
h[H]++;
}
}
Mat mhist = Mat::zeros(1, sz, CV_32F);
for (int j = 0; j < sz; j++) {
mhist.at<float>(j) = (float)h[j];
}
// Normalize histogram
double min, max;
minMaxLoc(mhist, &min, &max);
if (max > 0)
mhist.convertTo(mhist, -1, 1.0f / max, 0);
features = mhist;
}
void getHistomPlusColoFeatures(const Mat& image, Mat& features) {
Mat feature1, feature2;
getHistogramFeatures(image, feature1);
getColorFeatures(image, feature2);
hconcat(feature1.reshape(1, 1), feature2.reshape(1, 1), features);
}
void test(cv::Ptr<cv::ml::SVM> svm_) {
if (test_file_list_.empty()) {
prepare();
}
double count_all = test_file_list_.size();
double ptrue_rtrue = 0;
double ptrue_rfalse = 0;
double pfalse_rtrue = 0;
double pfalse_rfalse = 0;
for (auto item : test_file_list_) {
auto image = cv::imread(item.file);
if (!image.data) {
std::cout << "no" << std::endl;
continue;
}
cv::Mat feature;
getHistomPlusColoFeatures(image, feature);
auto predict = int(svm_->predict(feature));
//std::cout << "predict: " << predict << std::endl;
auto real = item.label;
if (predict == kForward && real == kForward) ptrue_rtrue++;
if (predict == kForward && real == kInverse) ptrue_rfalse++;
if (predict == kInverse && real == kForward) pfalse_rtrue++;
if (predict == kInverse && real == kInverse) pfalse_rfalse++;
}
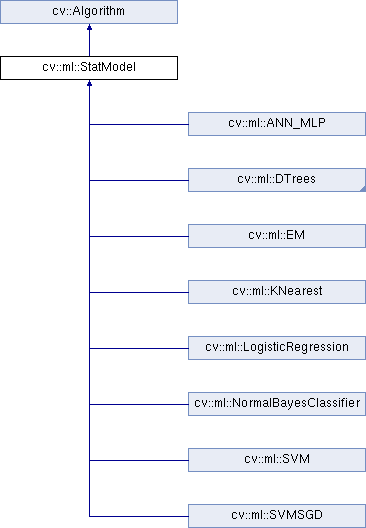
std::cout << "count_all: " << count_all << std::endl;
std::cout << "ptrue_rtrue: " << ptrue_rtrue << std::endl;
std::cout << "ptrue_rfalse: " << ptrue_rfalse << std::endl;
std::cout << "pfalse_rtrue: " << pfalse_rtrue << std::endl;
std::cout << "pfalse_rfalse: " << pfalse_rfalse << std::endl;
double precise = 0;
if (ptrue_rtrue + ptrue_rfalse != 0) {
precise = ptrue_rtrue / (ptrue_rtrue + ptrue_rfalse);
std::cout << "precise: " << precise << std::endl;
}
else {
std::cout << "precise: "
<< "NA" << std::endl;
}
double recall = 0;
if (ptrue_rtrue + pfalse_rtrue != 0) {
recall = ptrue_rtrue / (ptrue_rtrue + pfalse_rtrue);
std::cout << "recall: " << recall << std::endl;
}
else {
std::cout << "recall: "
<< "NA" << std::endl;
}
double Fsocre = 0;
if (precise + recall != 0) {
Fsocre = 2 * (precise * recall) / (precise + recall);
std::cout << "Fsocre: " << Fsocre << std::endl;
}
else {
std::cout << "Fsocre: "
<< "NA" << std::endl;
}
}
//数据准备
cv::Ptr<cv::ml::TrainData> tdata() {
cv::Mat samples;
std::vector<int> responses;
for (auto f : train_file_list_) {
auto image = cv::imread(f.file);
if (!image.data) {
fprintf(stdout, ">> Invalid image: %s ignore.\n", f.file.c_str());
continue;
}
cv::Mat feature;
getHistomPlusColoFeatures(image, feature);
feature = feature.reshape(1, 1);
samples.push_back(feature);
responses.push_back(int(f.label));
}
cv::Mat samples_, responses_;
samples.convertTo(samples_, CV_32FC1);
cv::Mat(responses).copyTo(responses_);
return cv::ml::TrainData::create(samples_, cv::ml::SampleTypes::ROW_SAMPLE, responses_);
}
int main(int argc, char** argv)
{
//initial SVM
cv::Ptr<cv::ml::SVM> svm = cv::ml::SVM::create();
svm->setType(cv::ml::SVM::Types::C_SVC);
svm->setKernel(cv::ml::SVM::KernelTypes::RBF);//使用推荐的参数
svm->setDegree(0.1);
svm->setGamma(0.1);
svm->setCoef0(0.1);
svm->setC(1);
svm->setNu(0.1);
svm->setP(0.1);
svm->setTermCriteria(cv::TermCriteria(cv::TermCriteria::MAX_ITER, 20000, 0.0001));
//数据准备
prepare();
if (train_file_list_.size() == 0) {
fprintf(stdout, "No file found in the train folder!\n");
fprintf(stdout, "You should create a folder named \"tmp\" in EasyPR main folder.\n");
fprintf(stdout, "Copy train data folder(like \"SVM\") under \"tmp\". \n");
return -1;
}
auto train_data = tdata();
fprintf(stdout, ">> Training SVM model, please wait...\n");
svm->trainAuto(train_data, 10, cv::ml::SVM::getDefaultGrid(cv::ml::SVM::C),
cv::ml::SVM::getDefaultGrid(cv::ml::SVM::GAMMA), cv::ml::SVM::getDefaultGrid(cv::ml::SVM::P),
cv::ml::SVM::getDefaultGrid(cv::ml::SVM::NU), cv::ml::SVM::getDefaultGrid(cv::ml::SVM::COEF),
cv::ml::SVM::getDefaultGrid(cv::ml::SVM::DEGREE), true);
//svm->save("svm.xml");
test(svm);
cv::waitKey(0);
return 0;
}


#include "pch.h"
#include <iostream>
#include <string>
#include <cstring>
#include <cstdlib>
#include <vector>
#include "gocvhelper.h"
using namespace std;
using namespace cv;
//解决具体的“判定当前图片中是否存在车牌”问题。
typedef enum {
kForward = 1, // correspond to "has plate"
kInverse = 0 // correspond to "no plate"
} SvmLabel;
typedef struct {
std::string file;
SvmLabel label;
} TrainItem;
std::vector<TrainItem> train_file_list_;
std::vector<TrainItem> test_file_list_;
std::vector<std::string> getFiles(const std::string &folder,const bool all = true ) {
std::vector<std::string> files;
std::list<std::string> subfolders;
subfolders.push_back(folder);
while (!subfolders.empty()) {
std::string current_folder(subfolders.back());
if (*(current_folder.end() - 1) != '/') {
current_folder.append("/*");
}
else {
current_folder.append("*");
}
subfolders.pop_back();
struct _finddata_t file_info;
auto file_handler = _findfirst(current_folder.c_str(), &file_info);
while (file_handler != -1) {
if (all &&
(!strcmp(file_info.name, ".") || !strcmp(file_info.name, ".."))) {
if (_findnext(file_handler, &file_info) != 0) break;
continue;
}
if (file_info.attrib & _A_SUBDIR) {
// it's a sub folder
if (all) {
// will search sub folder
std::string folder(current_folder);
folder.pop_back();
folder.append(file_info.name);
subfolders.push_back(folder.c_str());
}
}
else {
// it's a file
std::string file_path;
// current_folder.pop_back();
file_path.assign(current_folder.c_str()).pop_back();
file_path.append(file_info.name);
files.push_back(file_path);
}
if (_findnext(file_handler, &file_info) != 0) break;
} // while
_findclose(file_handler);
}
return files;
}
//数据集准备
const char* plates_folder_ = "E:/代码资源/EasyPR/resources/train/svm";
void prepare() {
srand(unsigned(time(NULL)));
char buffer[260] = { 0 };
sprintf_s(buffer, "%s/has/train", plates_folder_);
auto has_file_train_list = getFiles(buffer);
std::random_shuffle(has_file_train_list.begin(), has_file_train_list.end());
sprintf_s(buffer, "%s/has/test", plates_folder_);
auto has_file_test_list = getFiles(buffer);
std::random_shuffle(has_file_test_list.begin(), has_file_test_list.end());
sprintf_s(buffer, "%s/no/train", plates_folder_);
auto no_file_train_list = getFiles(buffer);
std::random_shuffle(no_file_train_list.begin(), no_file_train_list.end());
sprintf_s(buffer, "%s/no/test", plates_folder_);
auto no_file_test_list = getFiles(buffer);
std::random_shuffle(no_file_test_list.begin(), no_file_test_list.end());
fprintf(stdout, ">> Collecting train data...\n");
for (auto file : has_file_train_list)
train_file_list_.push_back({ file, kForward });
for (auto file : no_file_train_list)
train_file_list_.push_back({ file, kInverse });
fprintf(stdout, ">> Collecting test data...\n");
for (auto file : has_file_test_list)
test_file_list_.push_back({ file, kForward });
for (auto file : no_file_test_list)
test_file_list_.push_back({ file, kInverse });
}
float countOfBigValue(Mat &mat, int iValue) {
float iCount = 0.0;
if (mat.rows > 1) {
for (int i = 0; i < mat.rows; ++i) {
if (mat.data[i * mat.step[0]] > iValue) {
iCount += 1.0;
}
}
return iCount;
}
else {
for (int i = 0; i < mat.cols; ++i) {
if (mat.data[i] > iValue) {
iCount += 1.0;
}
}
return iCount;
}
}
Mat ProjectedHistogram(Mat img, int t, int threshold) {
int sz = (t) ? img.rows : img.cols;
Mat mhist = Mat::zeros(1, sz, CV_32F);
for (int j = 0; j < sz; j++) {
Mat data = (t) ? img.row(j) : img.col(j);
mhist.at<float>(j) = countOfBigValue(data, threshold);
}
// Normalize histogram
double min, max;
minMaxLoc(mhist, &min, &max);
if (max > 0)
mhist.convertTo(mhist, -1, 1.0f / max, 0);
return mhist;
}
Mat getHistogram(Mat in) {
const int VERTICAL = 0;
const int HORIZONTAL = 1;
// Histogram features
Mat vhist = ProjectedHistogram(in, VERTICAL,20);
Mat hhist = ProjectedHistogram(in, HORIZONTAL,20);
// Last 10 is the number of moments components
int numCols = vhist.cols + hhist.cols;
Mat out = Mat::zeros(1, numCols, CV_32F);
int j = 0;
for (int i = 0; i < vhist.cols; i++) {
out.at<float>(j) = vhist.at<float>(i);
j++;
}
for (int i = 0; i < hhist.cols; i++) {
out.at<float>(j) = hhist.at<float>(i);
j++;
}
return out;
}
void getHistogramFeatures(const Mat& image, Mat& features) {
Mat grayImage;
cvtColor(image, grayImage, cv::COLOR_RGB2GRAY);
//grayImage = histeq(grayImage);
Mat img_threshold;
threshold(grayImage, img_threshold, 0, 255, cv::THRESH_OTSU + cv::THRESH_BINARY);
//Mat img_threshold = grayImage.clone();
//spatial_ostu(img_threshold, 8, 2, getPlateType(image, false));
features = getHistogram(img_threshold);
}
//获得图片特征
void getColorFeatures(const Mat& src, Mat& features) {
Mat src_hsv;
//grayImage = histeq(grayImage);
cvtColor(src, src_hsv, cv::COLOR_BGR2HSV);
int channels = src_hsv.channels();
int nRows = src_hsv.rows;
// consider multi channel image
int nCols = src_hsv.cols * channels;
if (src_hsv.isContinuous()) {
nCols *= nRows;
nRows = 1;
}
const int sz = 180;
int h[sz] = { 0 };
uchar* p;
for (int i = 0; i < nRows; ++i) {
p = src_hsv.ptr<uchar>(i);
for (int j = 0; j < nCols; j += 3) {
int H = int(p[j]); // 0-180
if (H > sz - 1) H = sz - 1;
if (H < 0) H = 0;
h[H]++;
}
}
Mat mhist = Mat::zeros(1, sz, CV_32F);
for (int j = 0; j < sz; j++) {
mhist.at<float>(j) = (float)h[j];
}
// Normalize histogram
double min, max;
minMaxLoc(mhist, &min, &max);
if (max > 0)
mhist.convertTo(mhist, -1, 1.0f / max, 0);
features = mhist;
}
void getHistomPlusColoFeatures(const Mat& image, Mat& features) {
Mat feature1, feature2;
getHistogramFeatures(image, feature1);
getColorFeatures(image, feature2);
hconcat(feature1.reshape(1, 1), feature2.reshape(1, 1), features);
}
void test(cv::Ptr<cv::ml::StatModel> svm_) {
if (test_file_list_.empty()) {
prepare();
}
double count_all = test_file_list_.size();
double ptrue_rtrue = 0;
double ptrue_rfalse = 0;
double pfalse_rtrue = 0;
double pfalse_rfalse = 0;
for (auto item : test_file_list_) {
auto image = cv::imread(item.file);
if (!image.data) {
std::cout << "no" << std::endl;
continue;
}
cv::Mat feature;
getHistomPlusColoFeatures(image, feature);
auto predict = int(svm_->predict(feature));
//std::cout << "predict: " << predict << std::endl;
auto real = item.label;
if (predict == kForward && real == kForward) ptrue_rtrue++;
if (predict == kForward && real == kInverse) ptrue_rfalse++;
if (predict == kInverse && real == kForward) pfalse_rtrue++;
if (predict == kInverse && real == kInverse) pfalse_rfalse++;
}
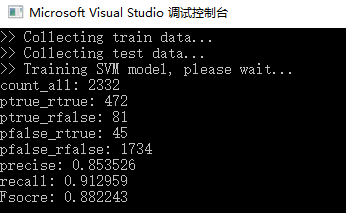
std::cout << "count_all: " << count_all << std::endl;
std::cout << "ptrue_rtrue: " << ptrue_rtrue << std::endl;
std::cout << "ptrue_rfalse: " << ptrue_rfalse << std::endl;
std::cout << "pfalse_rtrue: " << pfalse_rtrue << std::endl;
std::cout << "pfalse_rfalse: " << pfalse_rfalse << std::endl;
double precise = 0;
if (ptrue_rtrue + ptrue_rfalse != 0) {
precise = ptrue_rtrue / (ptrue_rtrue + ptrue_rfalse);
std::cout << "precise: " << precise << std::endl;
}
else {
std::cout << "precise: "
<< "NA" << std::endl;
}
double recall = 0;
if (ptrue_rtrue + pfalse_rtrue != 0) {
recall = ptrue_rtrue / (ptrue_rtrue + pfalse_rtrue);
std::cout << "recall: " << recall << std::endl;
}
else {
std::cout << "recall: "
<< "NA" << std::endl;
}
double Fsocre = 0;
if (precise + recall != 0) {
Fsocre = 2 * (precise * recall) / (precise + recall);
std::cout << "Fsocre: " << Fsocre << std::endl;
}
else {
std::cout << "Fsocre: "
<< "NA" << std::endl;
}
}
//数据准备
cv::Ptr<cv::ml::TrainData> tdata() {
cv::Mat samples;
std::vector<int> responses;
for (auto f : train_file_list_) {
auto image = cv::imread(f.file);
if (!image.data) {
fprintf(stdout, ">> Invalid image: %s ignore.\n", f.file.c_str());
continue;
}
cv::Mat feature;
getHistomPlusColoFeatures(image, feature);
feature = feature.reshape(1, 1);
samples.push_back(feature);
responses.push_back(int(f.label));
}
cv::Mat samples_, responses_;
samples.convertTo(samples_, CV_32FC1);
cv::Mat(responses).copyTo(responses_);
return cv::ml::TrainData::create(samples_, cv::ml::SampleTypes::ROW_SAMPLE, responses_);
}
int main(int argc, char** argv)
{
//init RT
Ptr<cv::ml::RTrees> m_trees;
m_trees = cv::ml::RTrees::create();
m_trees->setMaxDepth(10);
m_trees->setMinSampleCount(10);
m_trees->setRegressionAccuracy(0);
m_trees->setUseSurrogates(false);
m_trees->setMaxCategories(2);//设置/获取最大的类别数,默认值为10;
//m_trees->setPriors(0); //setPriors/getPriors函数:设置/获取先验概率数值,用于调整决策树的偏好,默认值为空的Mat;
m_trees->setCalculateVarImportance(true);//方法setCalculateVarImportance()是用来设置是否在训练期间计算每个特征变量的重要性(会有一些额外时间开销)。
m_trees->setActiveVarCount(false); //树节点随机选择特征子集的大小 setActiveVarCount()方法是用来设置给定节点上要测试特征集规模,这些特征集是随机选择的。如果用户未明确设置,则通常将其设置为总数量的平方根。
m_trees->setTermCriteria({ cv::TermCriteria::MAX_ITER + cv::TermCriteria::EPS,100, 0.01});
//数据准备
prepare();
if (train_file_list_.size() == 0) {
fprintf(stdout, "No file found in the train folder!\n");
fprintf(stdout, "You should create a folder named \"tmp\" in EasyPR main folder.\n");
fprintf(stdout, "Copy train data folder(like \"SVM\") under \"tmp\". \n");
return -1;
}
auto train_data = tdata();
fprintf(stdout, ">> Training ML model, please wait...\n");
//m_trees.train(features, CV_ROW_SAMPLE, categ_mat, cv::Mat(), cv::Mat(), cv::Mat(), cv::Mat(), m_rt_params);//这些参数可能 不是 全部都能够使用的
m_trees->train(train_data);
//mlmodel->save("mlmodel.xml");
test(m_trees);
cv::waitKey(0);
return 0;
}
m_trees->setMaxDepth(10);
m_trees->setMinSampleCount(10);
m_trees->setRegressionAccuracy(0);
m_trees->setUseSurrogates(false);
//m_trees->setPriors(0);
m_trees->setCalculateVarImportance(true);
m_trees->setActiveVarCount(false)
附件列表
OpenCV图像处理中的“机器学习"技术的使用的更多相关文章
- OpenCV图像处理中常用函数汇总(1)
//俗话说:好记性不如烂笔头 //用到opencv 中的函数时往往会一时记不起这个函数的具体参数怎么设置,故在此将常用函数做一汇总: Mat srcImage = imread("C:/Us ...
- OpenCV图像处理中常用函数汇总(2)
// 霍夫线变换 hough vector<Vec2f> lines;//定义一个矢量结构lines用于存放得到的线段矢量集合 HoughLines(dstImage,lines,,CV_ ...
- Zedboard甲诊opencv图像处理(三)
整个工程进展到这一步也算是不容易吧,但技术含量也不怎么高,中间乱起八糟的错误太烦人了,不管怎么样,现在面临了最大的困难吧,图像处理算法.算法确实不好弄啊,虽然以前整过,但都不是针对图像的. 现在的图像 ...
- paper 119:[转]图像处理中不适定问题-图像建模与反问题处理
图像处理中不适定问题 作者:肖亮博士 发布时间:09-10-25 图像处理中不适定问题(ill posed problem)或称为反问题(inverse Problem)的研究从20世纪末成为国际上的 ...
- 在opencv3中的机器学习算法
在opencv3.0中,提供了一个ml.cpp的文件,这里面全是机器学习的算法,共提供了这么几种: 1.正态贝叶斯:normal Bayessian classifier 我已在另外一篇博文中介 ...
- OpenCV图像处理篇之边缘检测算子
OpenCV图像处理篇之边缘检测算子 转载: http://xiahouzuoxin.github.io/notes/ 3种边缘检测算子 一阶导数的梯度算子 高斯拉普拉斯算子 Canny算子 Open ...
- 数据挖掘:实用机器学习技术P295页:
数据挖掘:实用机器学习技术P295页: 在weka软件中的实验者界面中,新建好实验项目后,添加相应的实验数据,然后添加对应需要的分类算法 ,需要使用多个算法时候重复操作添加add algorithm. ...
- 入门系列之Scikit-learn在Python中构建机器学习分类器
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由信姜缘 发表于云+社区专栏 介绍 机器学习是计算机科学.人工智能和统计学的研究领域.机器学习的重点是训练算法以学习模式并根据数据进行预 ...
- Python+OpenCV图像处理(十四)—— 直线检测
简介: 1.霍夫变换(Hough Transform) 霍夫变换是图像处理中从图像中识别几何形状的基本方法之一,应用很广泛,也有很多改进算法.主要用来从图像中分离出具有某种相同特征的几何形状(如,直线 ...
随机推荐
- 在线打开,浏览PDF文件的各种方式及各种pdf插件------(MS OneDrive/google drive & google doc/ github ?raw=true)
在线打开,浏览PDF文件的各种方式: 1 Google drive&doc (国内不好使,you know GFW=Great Firewall) 1. google drive: 直接分 ...
- 互联网公司技术岗实习/求职经验(实习内推+简历+面试+offer篇)
找工作的事基本尘埃落定了,打算把这大半年来积累的经验写下来,基本都是我希望当年找实习的时候自己能够知道的东西,帮师弟师妹们消除一点信息不平等,攒攒RP~ 不要像我当年那样,接到电话吓成狗,没接到电话吓 ...
- Intersection Observer
Intersection Observer Intersection Observer API https://developer.mozilla.org/en-US/docs/Web/API/Int ...
- Masterboxan INC发布《2019年可持续发展报告》
近日,Masterboxan INC万事达资产管理有限公司(公司编号:20151264097)发布<2019年可持续发展报告>,全面回顾了在过去一年Masterboxan INC开展的可持 ...
- Java开发的得力助手---Guava
导语 guava是google出品的java类库,被google广泛用于内部项目,该类库经过google大牛们的千锤百炼,以优雅的设计在java世界流行.版本迭代至今,很多思想甚至被JDK标准库借鉴, ...
- 使用RSEM进行转录组测序的差异表达分析
仍然是两年前的笔记 1. prepare-reference 如果用RSEM对比对后的bam进行转录本定量,则在比对过程中要确保比对用到的索引是由rsem-prepare-reference产生的. ...
- Why GraphQL? 6个问题
Why GraphQL? 6个问题 GraphQL, 是一个API的标准: specification. 对于每个新技术, 要搞清楚的6个问题: 1.这个技术出现的背景, 初衷, 要达到什么样的目标或 ...
- 阿里云linux安装nginx,亲测有效
系统平台:CentOS release 6.6 (Final) 64位. 一.安装编译工具及库文件 yum -y install make zlib zlib-devel gcc-c++ libtoo ...
- MySQL 常用命令手册 增删改查大法
一.数据库操作 创建数据库 语法: CREATE DATABASE database_name; 删除数据库 删除数据库务必谨慎!因为执行删除命令后,所有数据将消失. 语法: DROP DATABAS ...
- 获取点击元素的id
1.onclick="dianji(this.id)" 传入id到方法里function dianji(id){ //这个就是id}2. $(document).click(fun ...